Downloaded 15 times






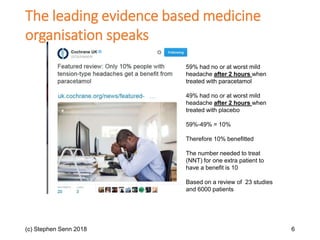



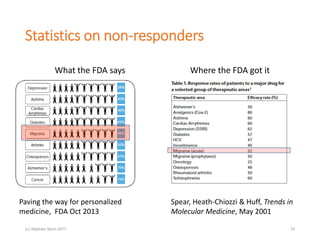



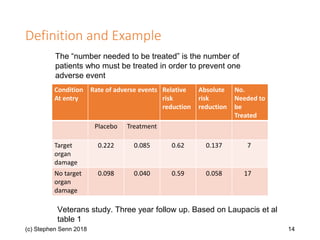

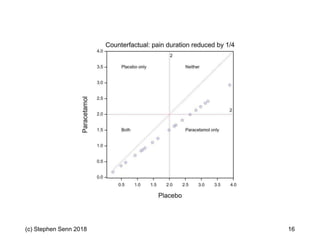
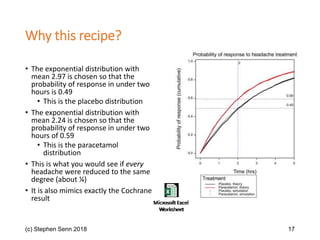



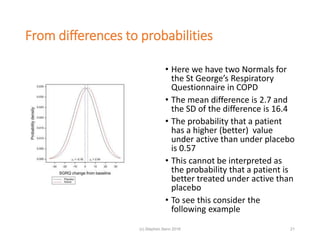
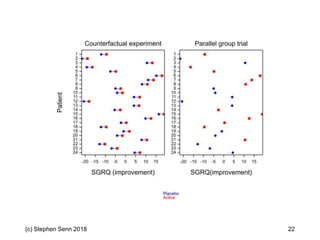






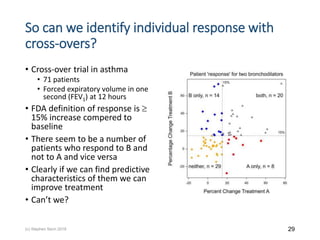
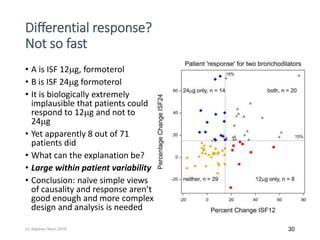



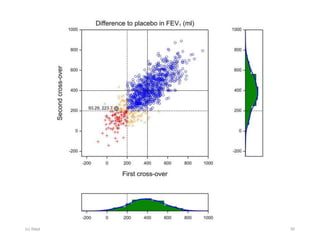
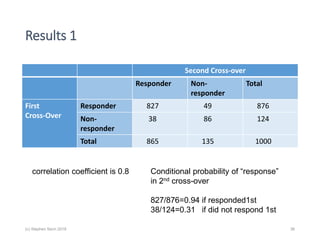
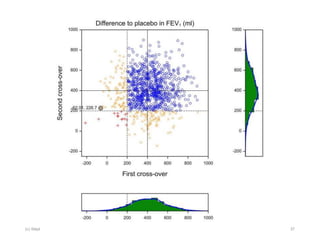
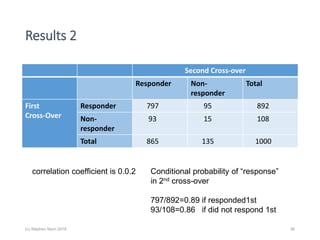

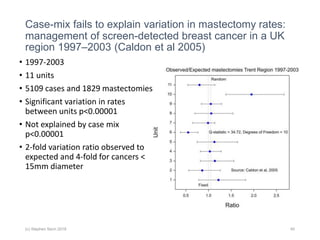





The document discusses the concept of 'number needed to treat' (NNT) and raises concerns about its interpretation and application in personalized medicine. It highlights the common misconceptions associated with NNT and responder analyses, emphasizing that these metrics can be misleading and fail to reflect individual patient responses accurately. The author argues for a better understanding of statistical variation in clinical trials and the need to avoid simplistic interpretations of treatment effects.






















































![PERI-PROSTHETIC FRACTURE NAIL-PLATE CONSTRUCT [NPC].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/drarunkumardrmohamedashrafperiprostheticfrasturenail-plateconstructnpc-260209164459-7e9d15a1-thumbnail.jpg?width=640&height=640&fit=bounds)




![ONFH[AVN HIP] -TRIPLE REGIME -A NOVAL SURGICAL CONCEPT .pptx](https://cdn.slidesharecdn.com/ss_thumbnails/onfhavnhip2026koaconcalicutdrgokuldevdrmashraf-260210064517-213ec005-thumbnail.jpg?width=640&height=640&fit=bounds)







