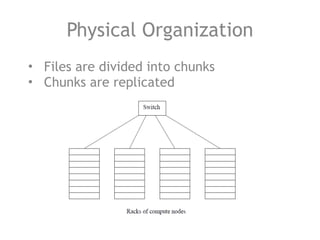
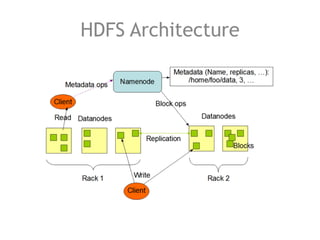
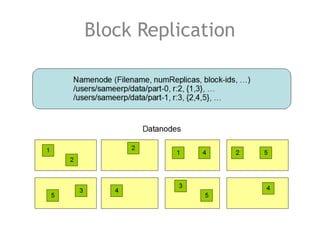
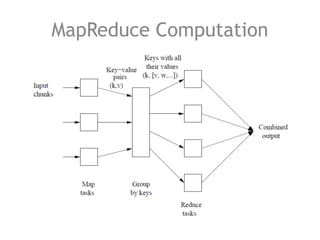
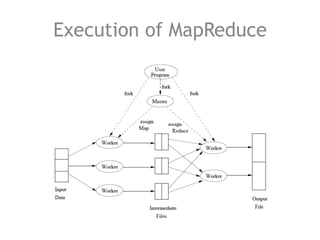
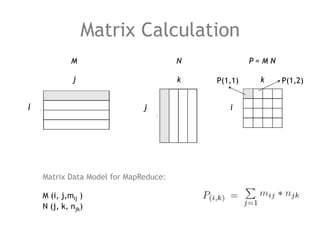
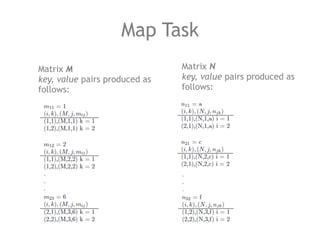
The document discusses the necessity of efficient data management for big data analysis, particularly through the MapReduce programming model and distributed file systems like HDFS. It outlines the structure of MapReduce computations involving the processing of <key, value> pairs, and provides a detailed example of word count to illustrate its execution. Additionally, it briefly touches on matrix calculations and their data model as applied within the MapReduce framework.