Download as PDF, PPTX









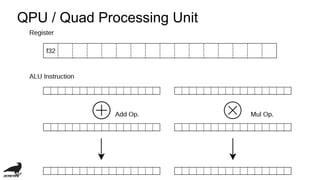
![QPU / Quad Processing Unit
・general purpose register A/B x32 (=64 registers)
・accumulator register r[0-3] (= 4 registers)](https://image.slidesharecdn.com/vc4cdevelopmentofopenclcompilerforvideocore4-181109141143/85/Vc4c-development-of-opencl-compiler-for-videocore4-12-320.jpg)


![Flow of execution
・allocate GPU memory
・build uniforms
・for each thread
・run driver
with Driver () as drv :
n_threads = 12
r = drv.alloc((n_threads, 128),
’float32’)
a = drv.alloc((n_threads, 128),
’float32’)
………
code = drv.program(mul2)
uniforms = drv.alloc((n_threads, 3),
‘uint32’)
uniforms[:, 0] = r.address()[:, 0]
uniforms[:, 1] = 128
uniforms[:, 2] = a.address()[0][0]
drv.execute(n_threads=n_threads,
program=code, uniforms=uniforms)](https://image.slidesharecdn.com/vc4cdevelopmentofopenclcompilerforvideocore4-181109141143/85/Vc4c-development-of-opencl-compiler-for-videocore4-27-320.jpg)
![performance example: qmkl
$ sudo ./qmkl/test/sgemm 224 224 224
GPU: 6.17614e+09 [flop/s]
CPU: 9.78483e+08 [flop/s]
NEON: 1.06783e+09 [flop/s]
https://github.com/idein/qmkl
・mathematical kernels using VC4 cation: no-trans, no-trans](https://image.slidesharecdn.com/vc4cdevelopmentofopenclcompilerforvideocore4-181109141143/85/Vc4c-development-of-opencl-compiler-for-videocore4-28-320.jpg)
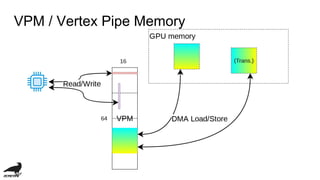
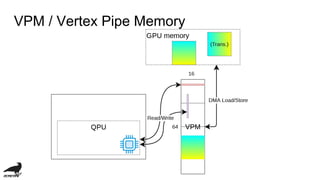
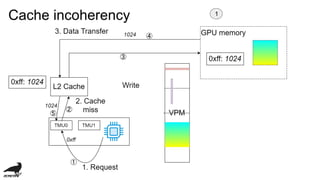
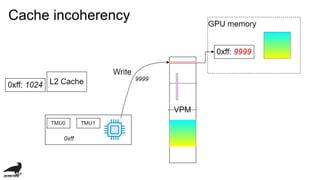
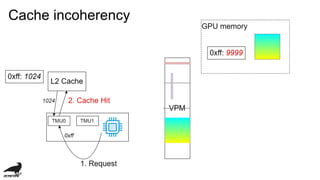
![Performance issue
・low memory band-width:
・4.48 GBPS v.s. 98 GBPS in my computer...
・TMU Latecy (cycle):
・TMU cache hit: 9
・L2 cache hit: 12
・Memory: 20 (if v3d_freq=250 [MHz])
・cache incoherency](https://image.slidesharecdn.com/vc4cdevelopmentofopenclcompilerforvideocore4-181109141143/85/Vc4c-development-of-opencl-compiler-for-videocore4-29-320.jpg)

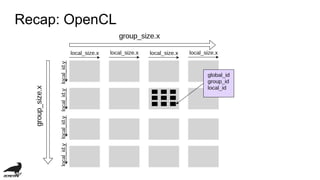
![・Parallel programming framework for
heterogene computing (GPU, DSP, FPGA, etc...)
・Support data paralle computing model
Recap: OpenCL
kernel void mul2(global float * a)
{
int id = get_global_id(0);
a[id] = a[id] * 2 + 1;
}
clCreateContext
clCreateProgramWithSource
clCreateBuffer
clEnqueueWriteBuffer
global_item_size = { 4, 8, 12 };
clEnqueueNDRangeKernel
compile at runtime
enqueue kernel
Host program](https://image.slidesharecdn.com/vc4cdevelopmentofopenclcompilerforvideocore4-181109141143/85/Vc4c-development-of-opencl-compiler-for-videocore4-34-320.jpg)
![Asm structure kernel void mul2(global float * a) {
int id = get_global_id(0);
a[id] = a[id] * 2 + 1;
}
・make implicit loop
・OpenCL parameters are
passed via uniform
・Loop exit are passed via
uniform](https://image.slidesharecdn.com/vc4cdevelopmentofopenclcompilerforvideocore4-181109141143/85/Vc4c-development-of-opencl-compiler-for-videocore4-37-320.jpg)







![Insufficient use of DMA
kernel void mul2(global float * a)
{
int id = get_global_id(0);
a[id] = a[id] * 2 + 1;
}
・region a is read/write
・a is just read once
・Acutually, Load via TMU is safe
・required complex analysis…???](https://image.slidesharecdn.com/vc4cdevelopmentofopenclcompilerforvideocore4-181109141143/85/Vc4c-development-of-opencl-compiler-for-videocore4-45-320.jpg)

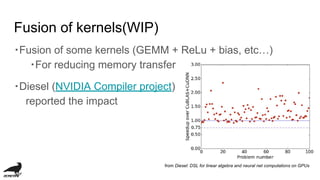




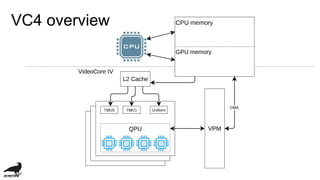
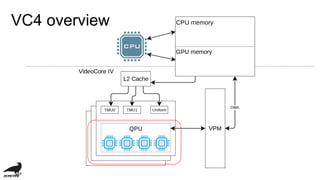
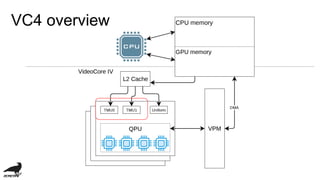
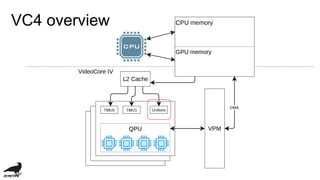
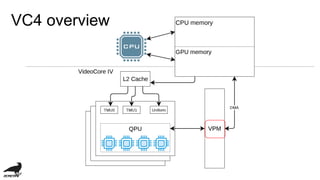
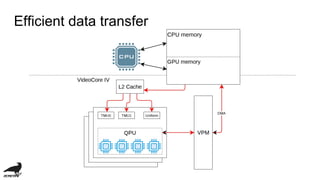
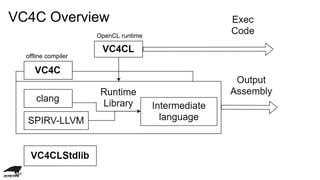
This document discusses the development of an OpenCL compiler called VC4C for the VideoCore IV GPU found in the Raspberry Pi. It provides an overview of the VC4 architecture including its quad processing units, texture and memory lookup unit, uniform cache, and vertex pipe memory. It then introduces VC4C as an open-source project that compiles OpenCL to optimized assembly for the VC4. Several challenges are discussed such as limited registers, cache incoherency, and complex iteration patterns from OpenCL IDs. Optimization techniques explored include constant handling, vectorization, kernel fusion, and software pipelining. In conclusion, VC4C remains a work in progress but provides an opportunity for compiler optimization on an unoptimized


































































