Downloaded 84 times





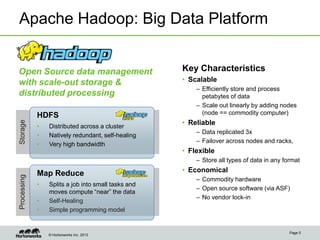

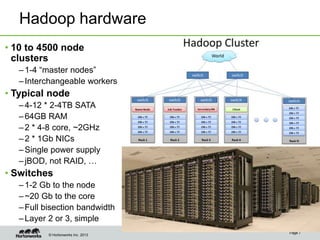
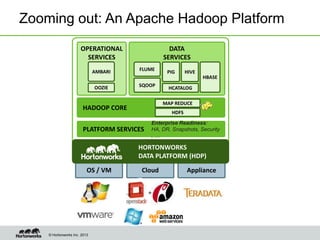
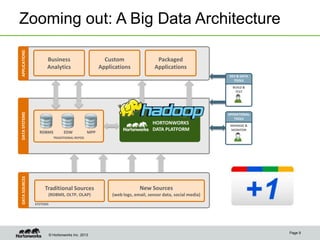



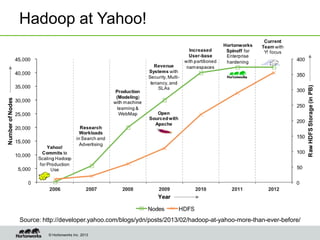
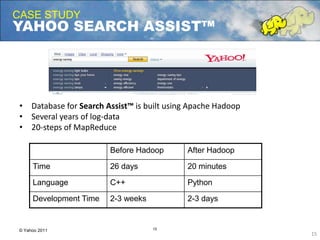
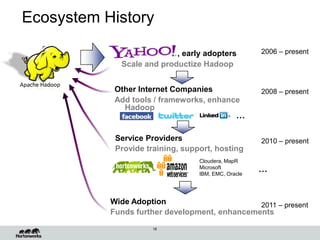





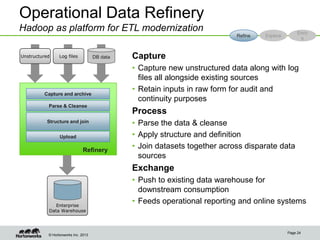
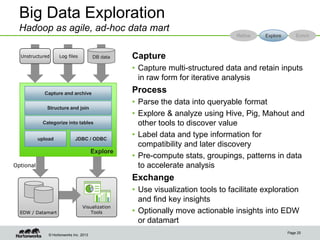
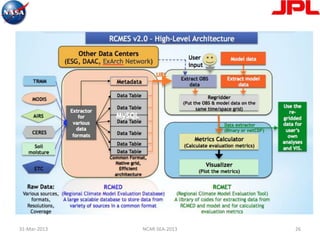




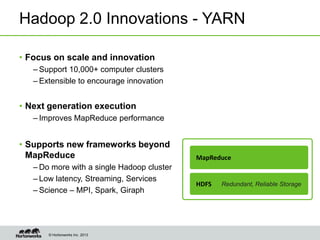
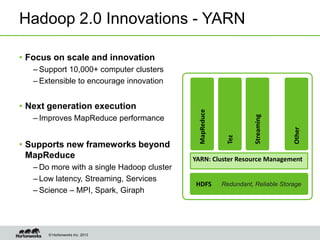

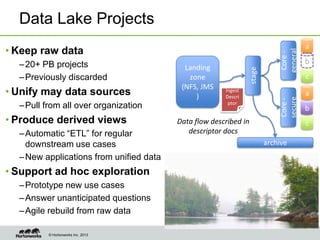



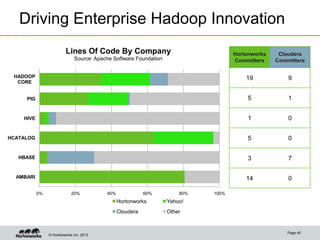
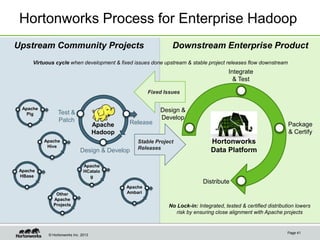

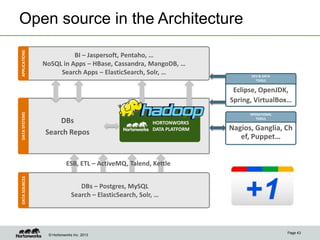



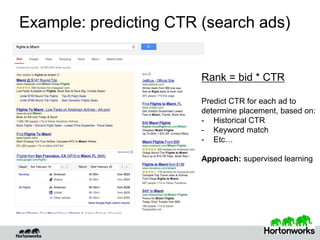


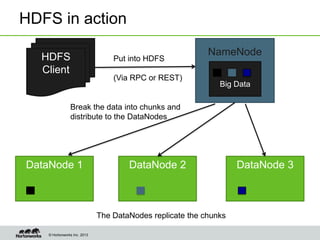

Eric Baldeschwieler, CTO of Hortonworks, presents on Apache Hadoop for big science. He discusses the history and motivation for Hadoop, including its origins at Yahoo in 2005. Baldeschwieler outlines several use cases for Hadoop in domains like genomics, oil and gas, and high-energy physics. He also explores futures for Hadoop, including innovations in YARN and the Stinger initiative to improve Hive for interactive queries.















































