Download to read offline













![Query Categorization
• 3) rank the clusters by cluster-based language
model, as proposed by Lee et. Al [19]
15](https://image.slidesharecdn.com/query-dependent-pseudorelevance-feedback-based-on-wikipedia-160212152441/85/Query-Dependent-Pseudo-Relevance-Feedback-based-on-Wikipedia-15-320.jpg)


















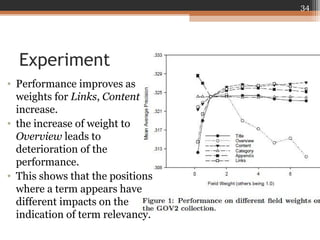






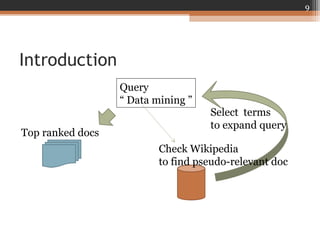
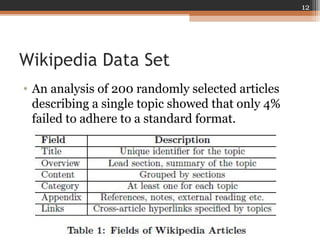
This document summarizes a presentation on using Wikipedia for query expansion in pseudo-relevance feedback (PRF) for information retrieval. Three query expansion methods are proposed: 1) a baseline relevance model, 2) selecting terms from the Wikipedia entity page for entity/ambiguous queries, and 3) two field-based methods (unsupervised and supervised) that consider term distributions and structures. Experiments on TREC collections show the query-dependent approach, which selects the expansion method based on query type, outperforms the baseline relevance model. Future work could include exploring term selection for broader queries and evaluating on additional datasets.


































































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)







![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)









