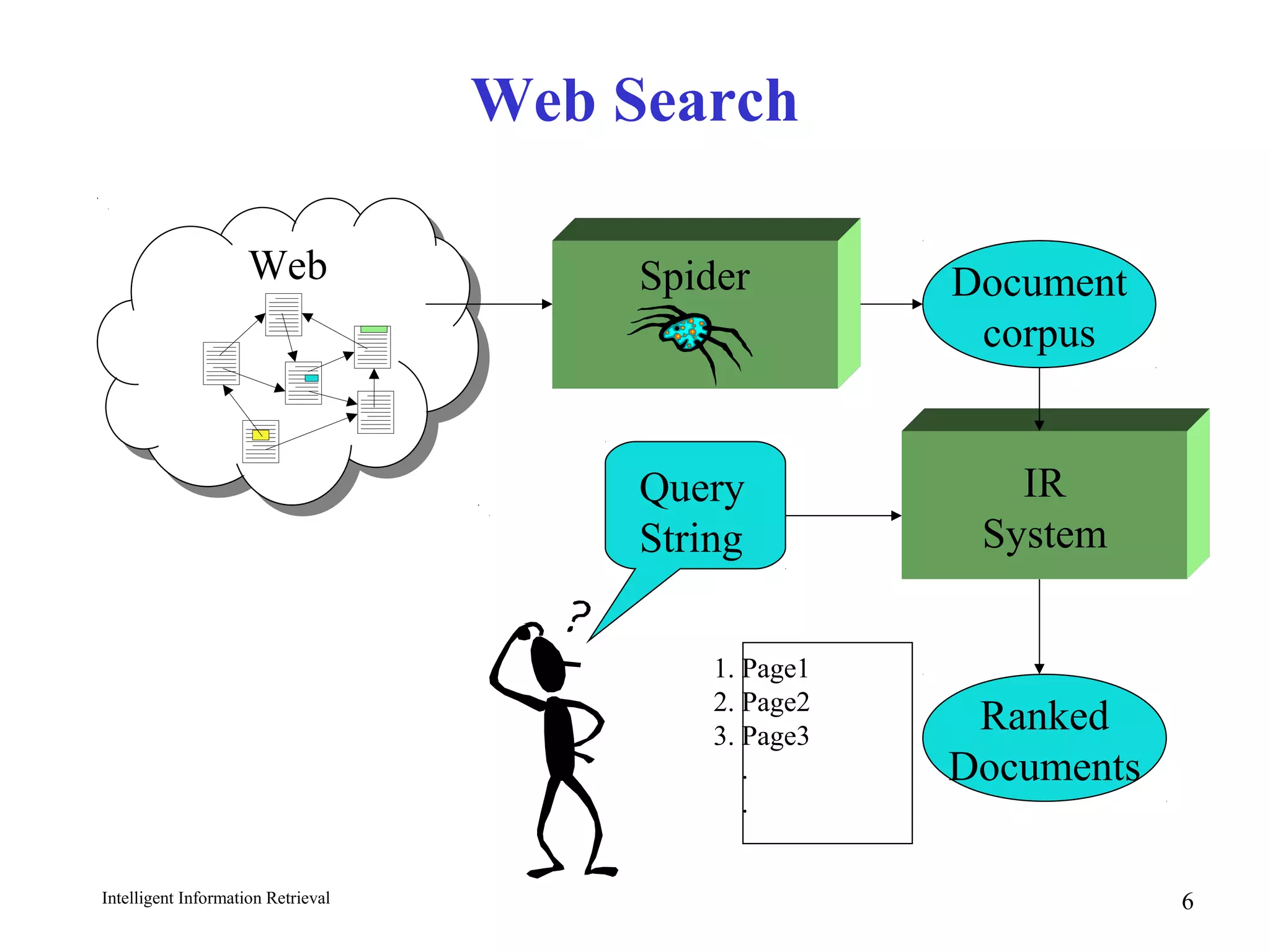
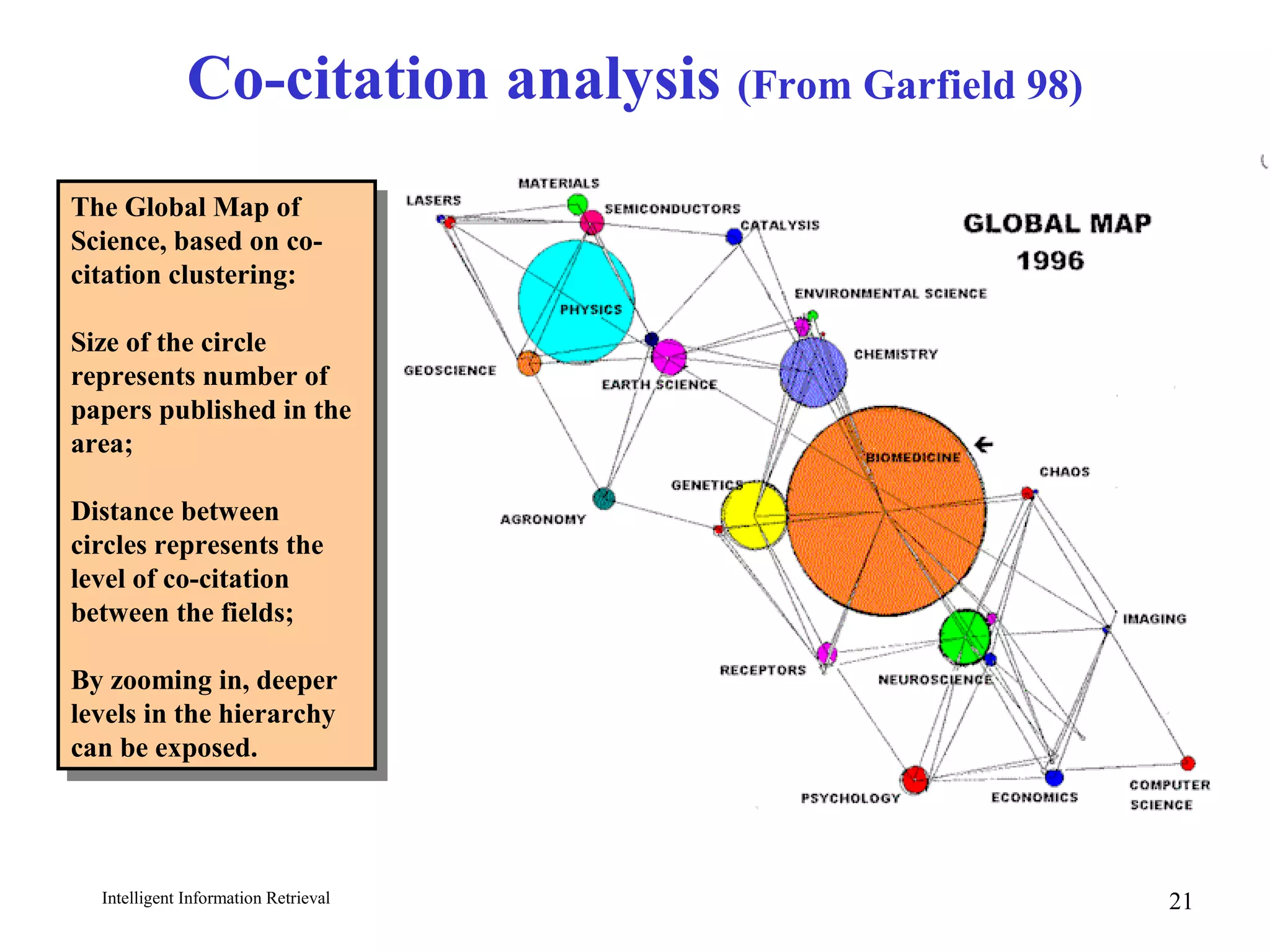
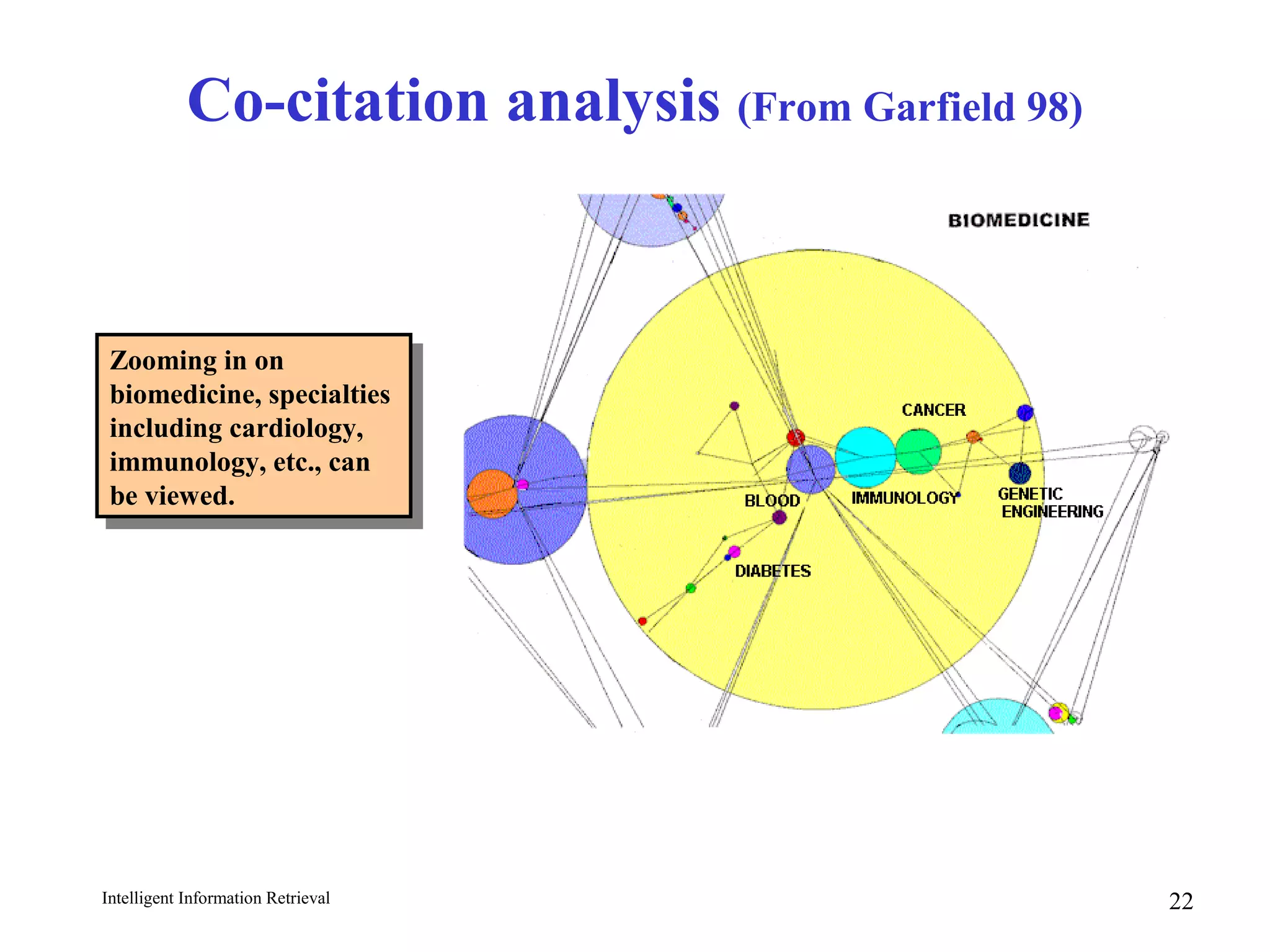
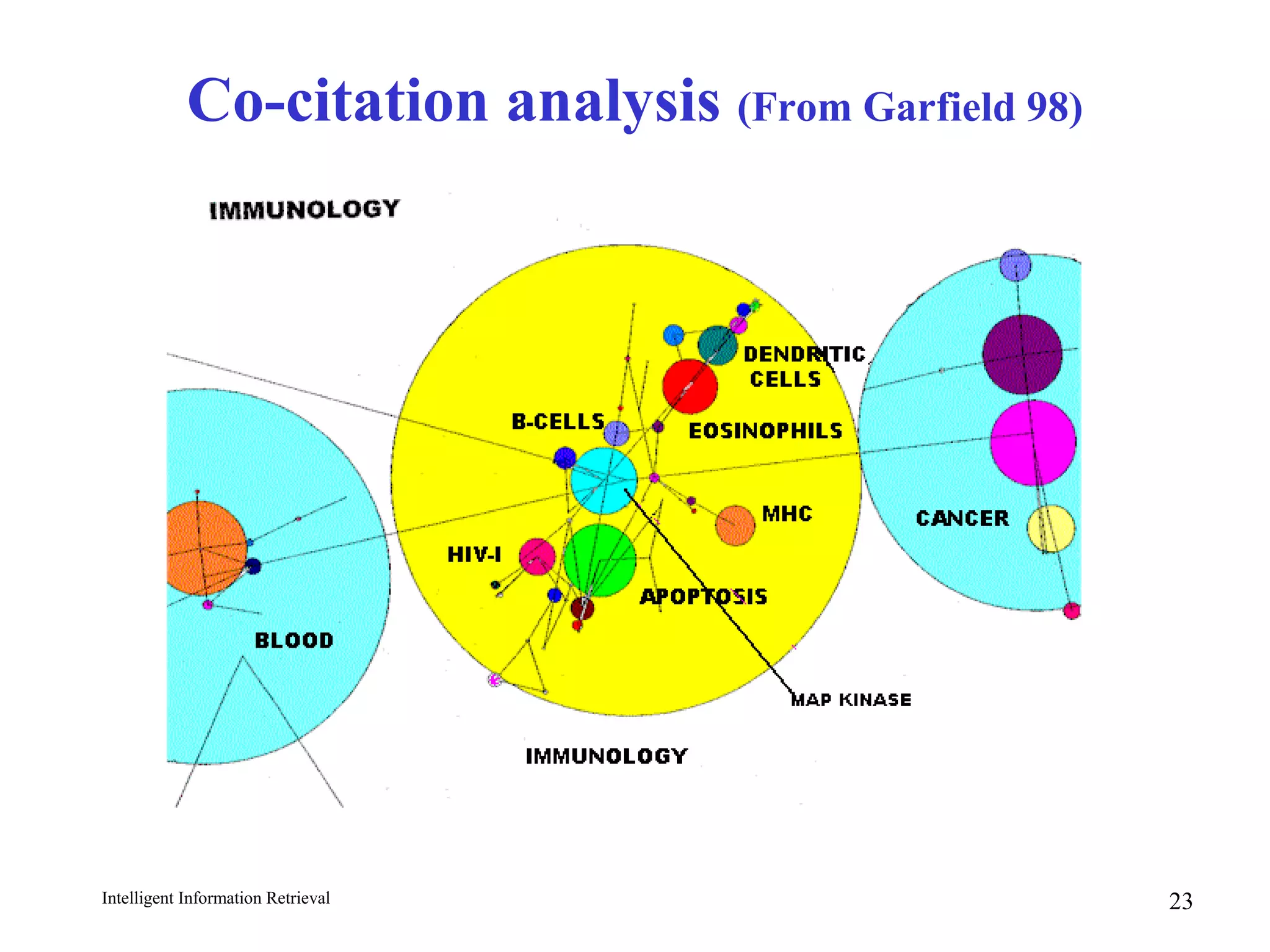
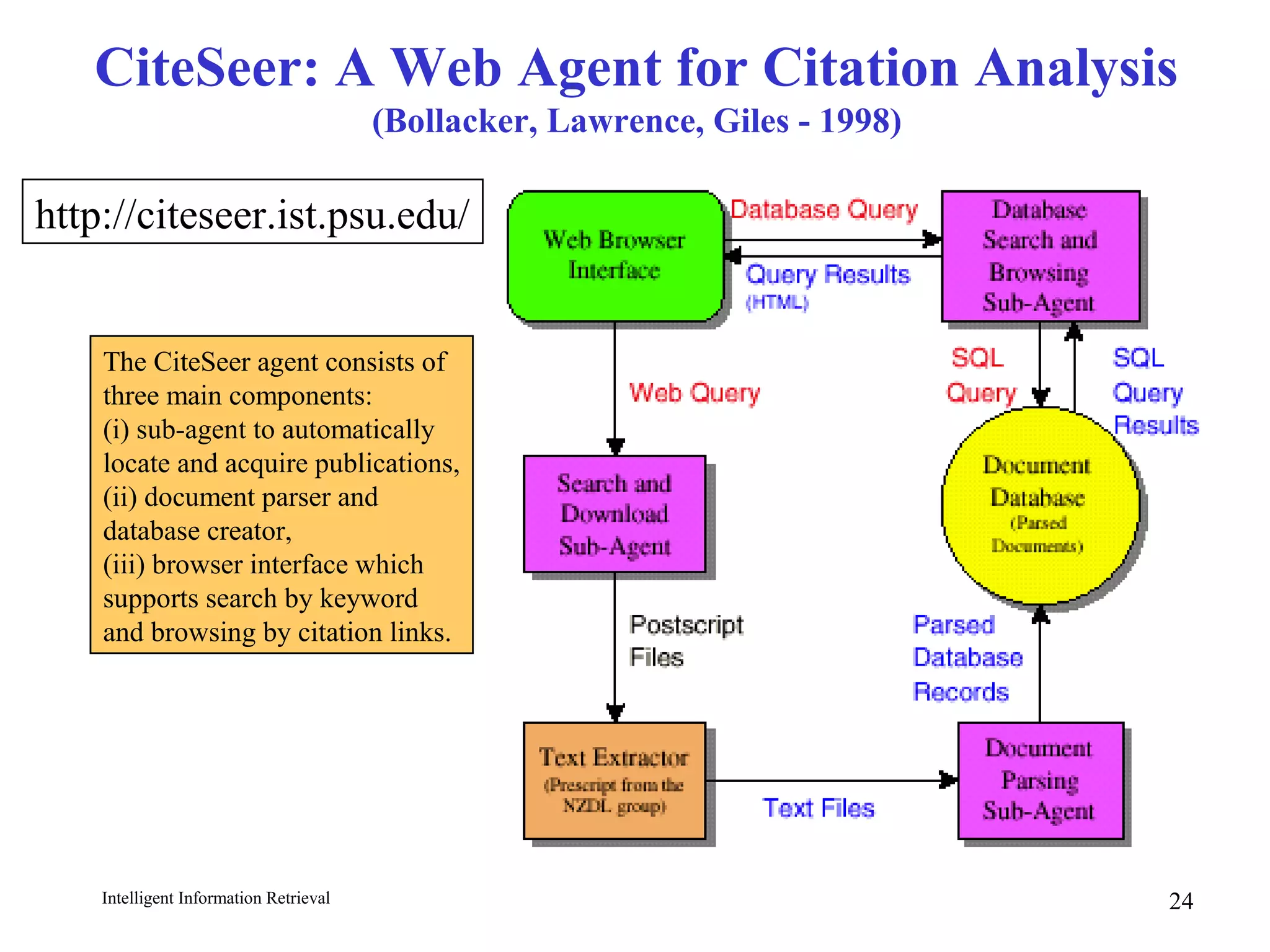
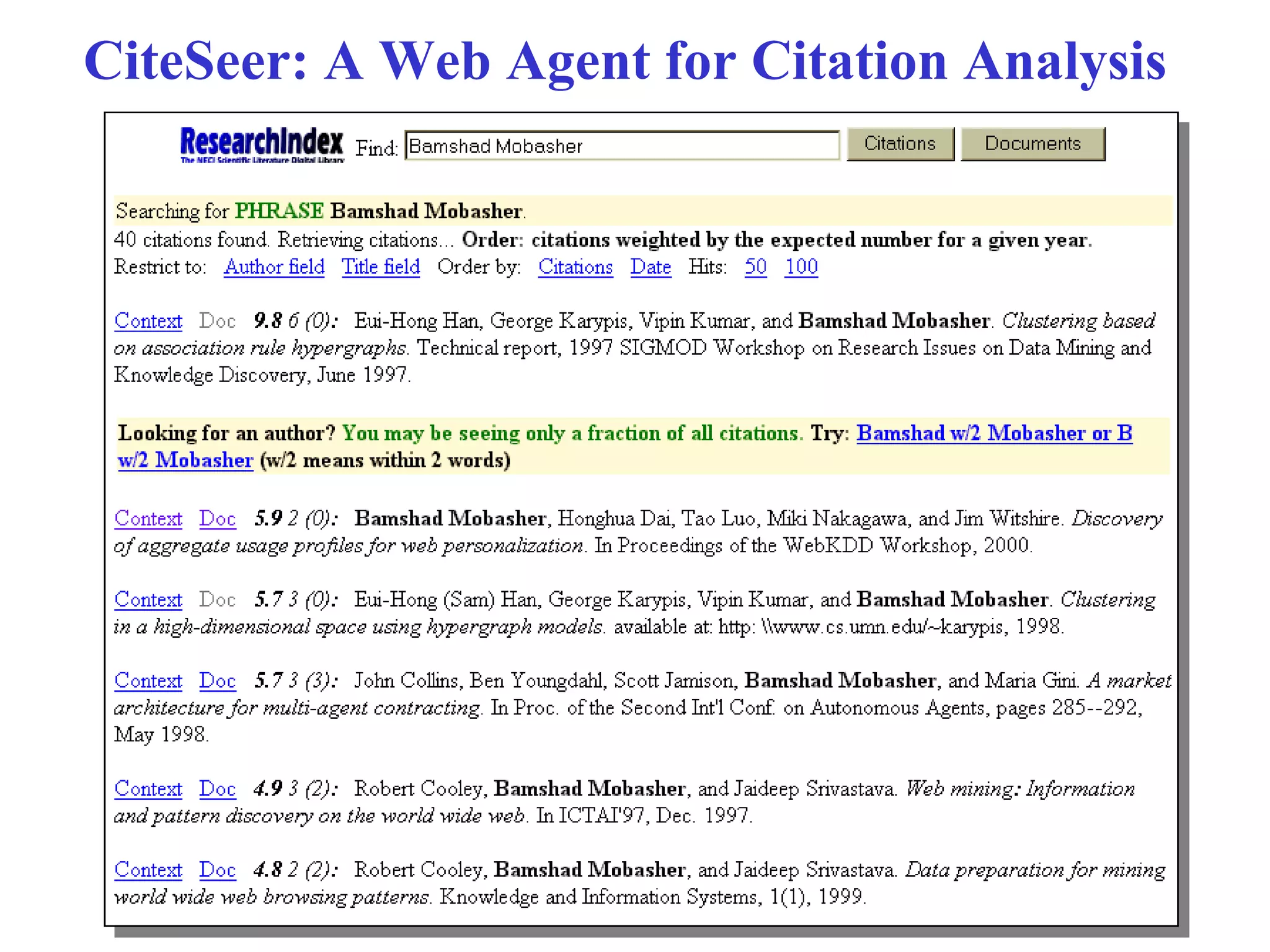
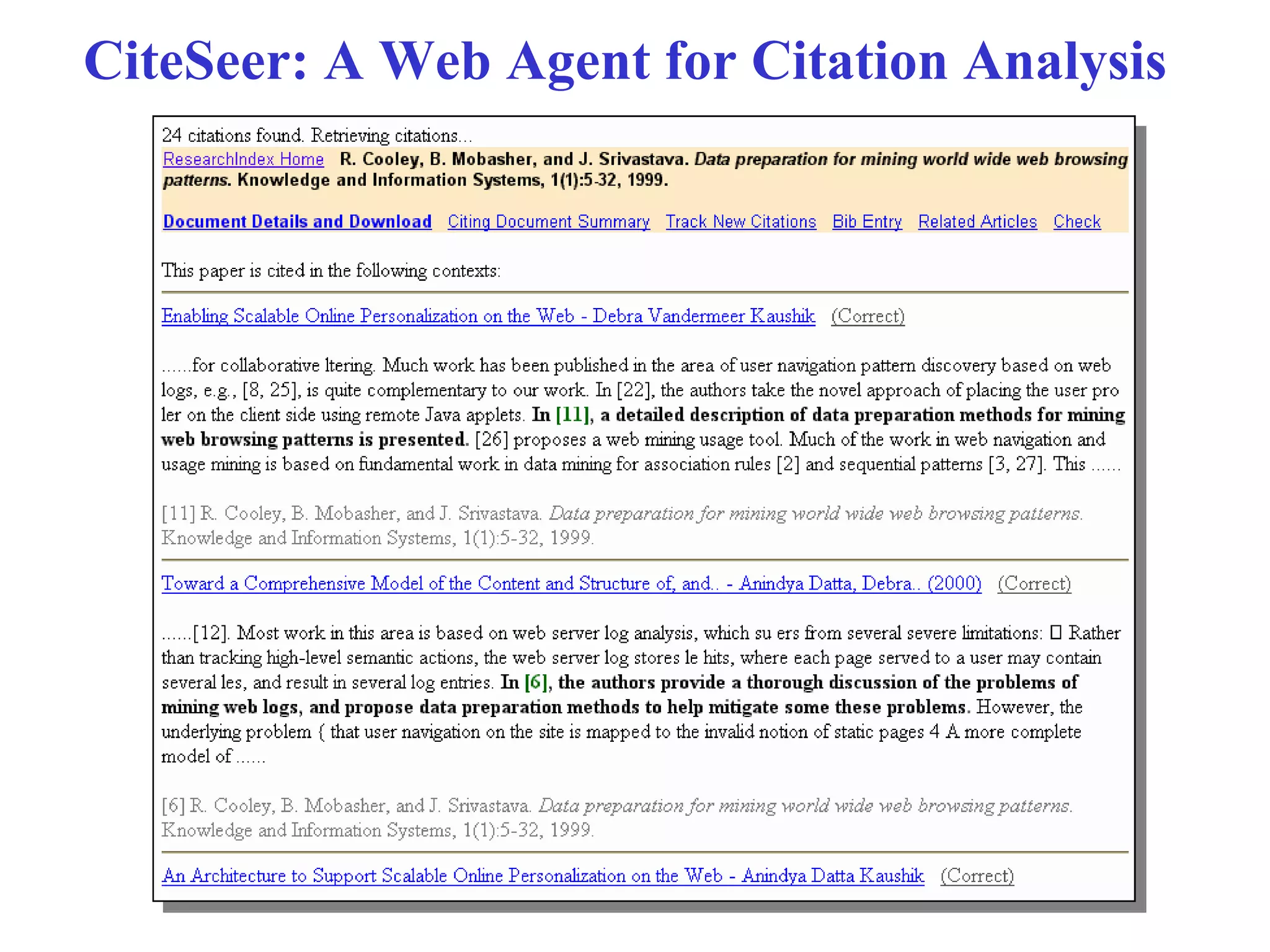
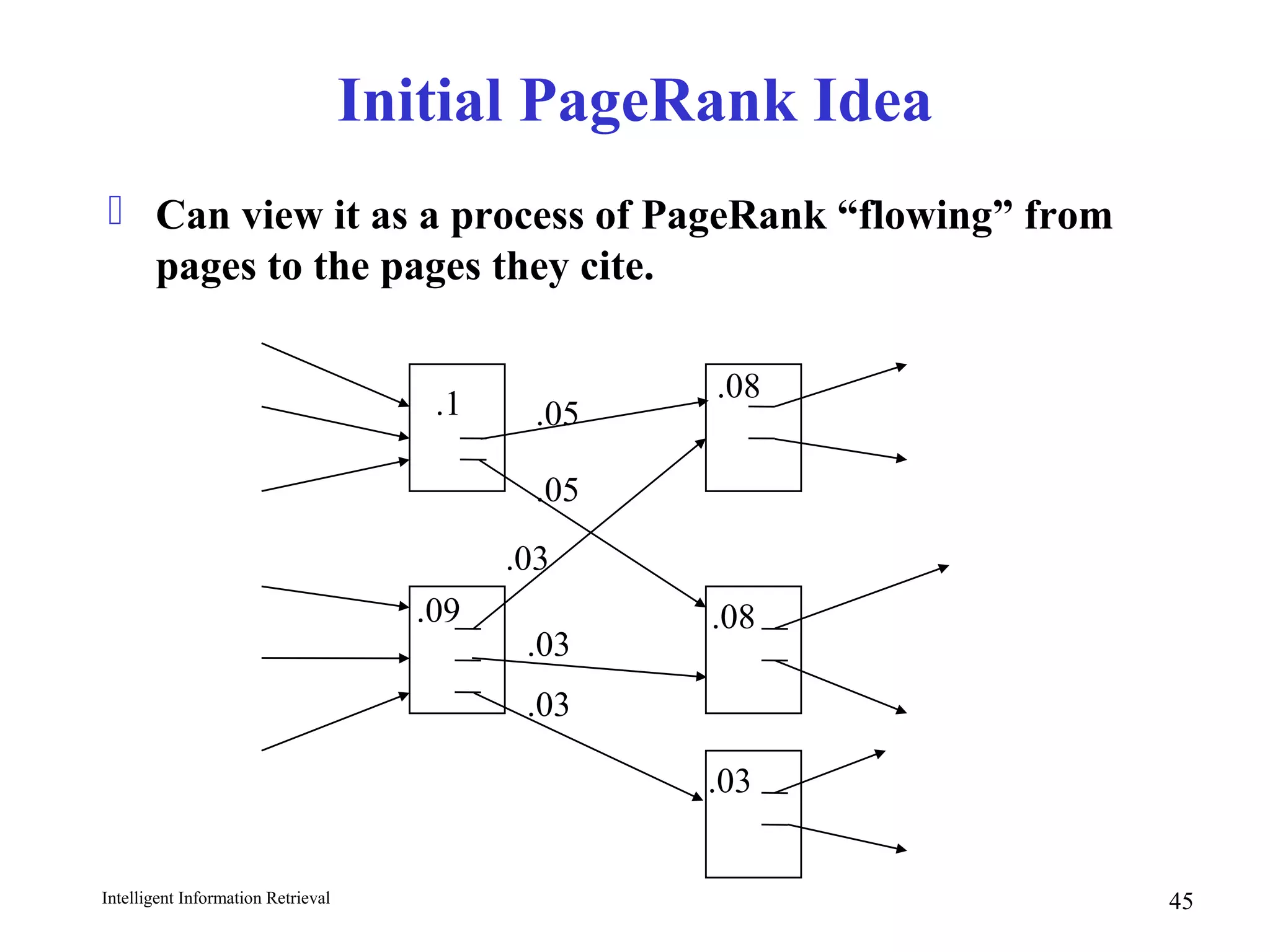
The document discusses intelligent information retrieval techniques for web search engines. It covers topics like:
- Differences between web IR and classic IR like the large volume and distributed nature of web data.
- How web spiders and crawlers work to index web pages by following links in a breadth-first manner.
- Using anchor text and hyperlinks for citation/link analysis and ranking pages by authority and hub scores.
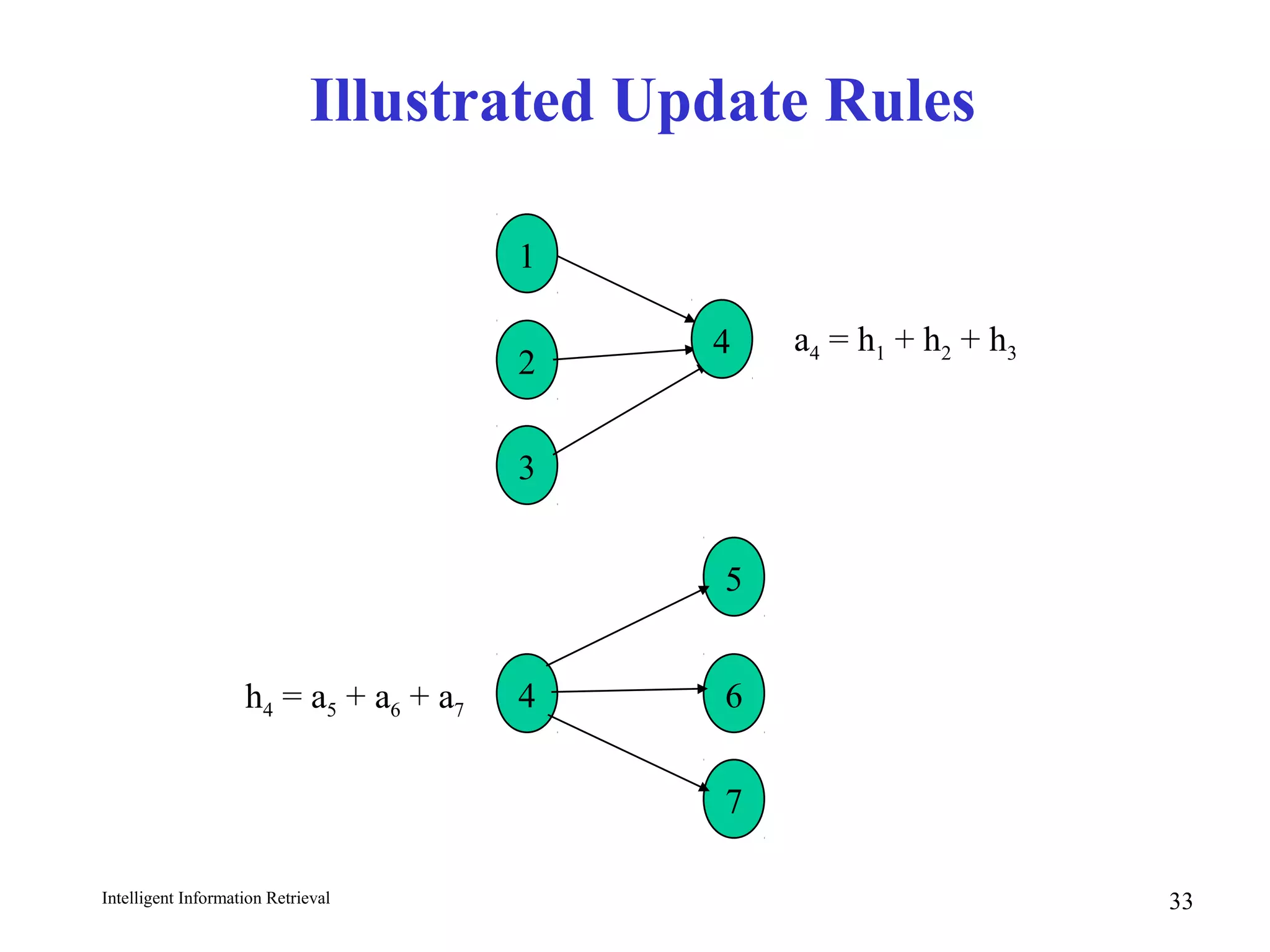
- The HITS algorithm which computes authority and hub scores through an iterative process to find important pages.


























![Intelligent Information Retrieval 35
HITS Example
D
A
B
C
E
D A C B E
A: [0.0, 0.0, 2.0, 2.0, 1.0]
D A C B E
H: [4.0, 5.0, 0.0, 0.0, 0.0]
D A C B E
Norm A: [0.0, 0.0, 0.67, 0.67.0, 0.33]
D A C B E
Norm H: [0.62, 0.78, 0.0, 0.0, 0.0]
First Iteration
Normalize: divide
each vector by its
norm (square root
of the sum of the
squares)](https://image.slidesharecdn.com/4saivkuztblbei9or2na-signature-36f32e70ca4a33ced055e07ae5cf71cddac8f7fec70112c9f9e169a5a2016f84-poli-160425162034/75/Information-retrieval-35-2048.jpg)
![Intelligent Information Retrieval 36
HITS Algorithm
Let HUB[v] and AUTH[v] represent the hub and
authority values associated with a vertex v
Repeat until HUB and AUTH vectors converge
Normalize HUB and AUTH
HUB[v] := Σ AUTH[ui] for all ui with Edge(v, ui)
AUTH[v] := Σ HUB[wi] for all ui with Edge(wi, v)
A H
v
u1
u2
uk
...
w1
w2
wk
...](https://image.slidesharecdn.com/4saivkuztblbei9or2na-signature-36f32e70ca4a33ced055e07ae5cf71cddac8f7fec70112c9f9e169a5a2016f84-poli-160425162034/75/Information-retrieval-36-2048.jpg)





![Intelligent Information Retrieval 42
Modified HITS Algorithm
Let HUB[v] and AUTH[v] represent the hub and
authority values associated with a vertex v
Repeat until HUB and AUTH vectors converge
Normalize HUB and AUTH
HUB[v] := Σ AUTH[ui] . TopicScore[ui] . Weight(v, ui)
for all ui with Edge(v, ui)
AUTH[v] := Σ HUB[wi] . TopicScore[wi] . Weight(wi, v)
for all ui with Edge(wi, v)
Topic score is determined based on similarity measure
between the query and the documents](https://image.slidesharecdn.com/4saivkuztblbei9or2na-signature-36f32e70ca4a33ced055e07ae5cf71cddac8f7fec70112c9f9e169a5a2016f84-poli-160425162034/75/Information-retrieval-42-2048.jpg)







![Intelligent Information Retrieval
PageRank Example
A B
C
α = 0.3
A C B
Initial R: [0.33, 0.33, 0.33]
R’(C): R(A)/2 + R(B)/1 + 0.3/3
R’(B): R(A)/2 + 0.3/3
R’(A): 0.3/3
A C B
R’: [0.1, 0.595, 0.27]
A C B
R: [0.104, 0.617, 0.28]
Normalization factor:
1/[R’(A)+R’(B)+R’(C)] = 1/0.965
First Iteration Only:
before
normalization:
after
normalization:](https://image.slidesharecdn.com/4saivkuztblbei9or2na-signature-36f32e70ca4a33ced055e07ae5cf71cddac8f7fec70112c9f9e169a5a2016f84-poli-160425162034/75/Information-retrieval-51-2048.jpg)
































































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)











