Download as PDF, PPTX





















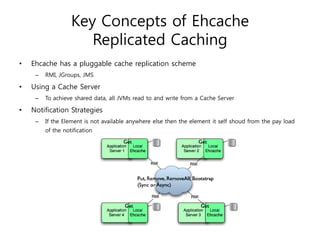

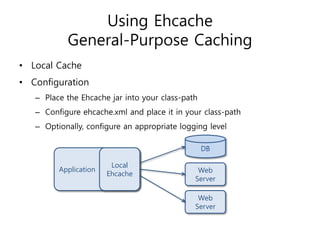
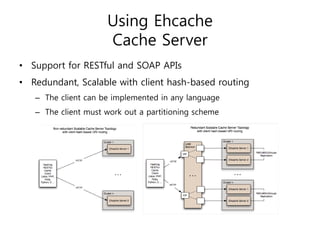

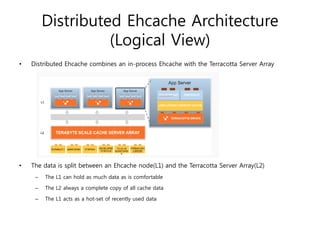

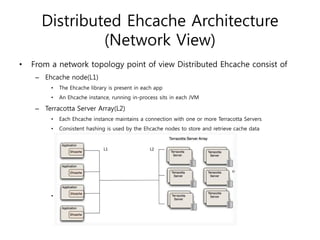
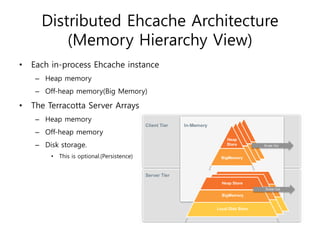
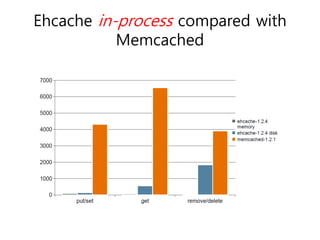


Ehcache is an open source Java caching library that provides fast, scalable caching for applications. It allows for in-process caching with single nodes or distributed caching across multiple nodes. Ehcache provides features like memory and disk storage, replication, search capabilities, and integration with Terracotta for distributed caching. It uses common caching patterns like cache-aside, read-through, write-through, and cache-as-sor. Ehcache has a simple API and is lightweight, scalable, and standards-based.











































































































