Download as PDF, PPTX











![Analysing the data – GC Logs
• The GC logs will show details of all Garbage
Collection since the server started
• The files are human readable
• Example:
[GC 325407K->83000K(776768K), 0.2300771 secs]
[GC 325816K->83372K(776768K), 0.2454258 secs]
[Full GC 267628K->83769K(776768K), 1.8479984 secs]
© C2B2 Consulting Limited 2013
All Rights Reserved](https://image.slidesharecdn.com/javamiddlewaresurgery-131107082753-phpapp01/85/Java-Middleware-Surgery-11-320.jpg)
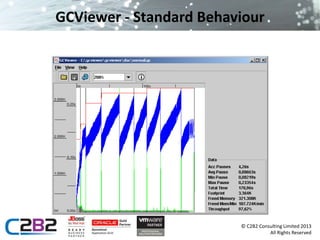
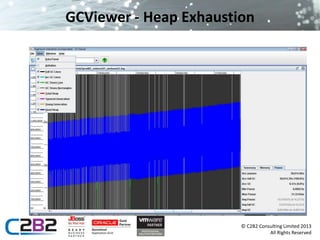





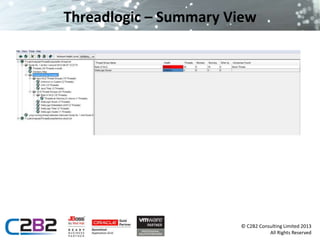

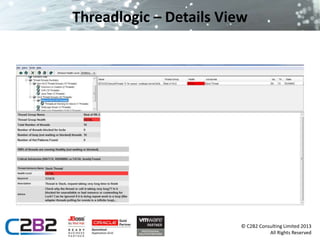








The document discusses common server issues such as slowdown and out of memory errors, presenting two main scenarios for diagnosis and resolution. It provides detailed steps for gathering information, analyzing garbage collection logs, heap dumps, and stack traces to identify problems, along with preventive measures. Additionally, it addresses JMS-related issues like message loss and reliability, suggesting the use of message bridges and various provider options.























































































