








![LRU (Least Recently Used)
Items are added to the cache as they are accessed; when
the cache is full, the least recently used item is ejected.
Cache access overhead is against constant time. This
algorithm is simple and fast, and it has a significant
advantage over FIFO in being able to adapt somewhat to
the data access pattern; frequently used items are less
likely to be ejected from the cache. The main disadvantage
is that it can still get filled up with items that are unlikely to
be reaccessed soon; in particular, it can become useless in
the face of scans over a larger number of items than fit in
the cache. Nonetheless, this is by far the most frequently
used caching algorithm [4].
Summary for LRU: fast, adaptive, not scan resistant](https://image.slidesharecdn.com/j2eeenterprisecaching-120923112756-phpapp01/85/Caching-for-J2ee-Enterprise-Applications-9-320.jpg)



![TTL (Time to live) expiration
Data in the cache is invalidated by
specifying the amount of time the
item is allowed to be idle in the
cache after last access time [5].](https://image.slidesharecdn.com/j2eeenterprisecaching-120923112756-phpapp01/85/Caching-for-J2ee-Enterprise-Applications-13-320.jpg)
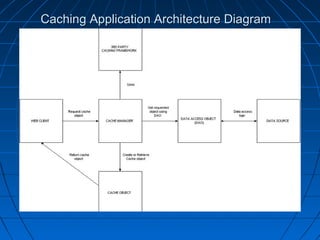
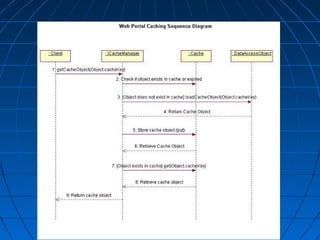
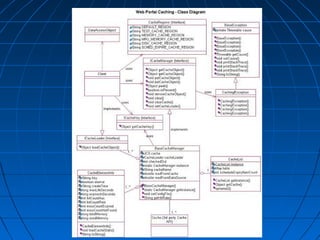














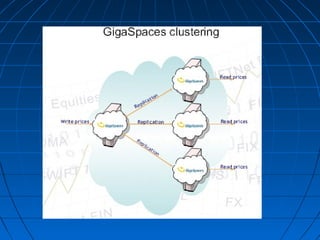




This document discusses caching for Java EE enterprise applications. It begins by explaining the need for caching to improve performance by reducing database access. It then describes advantages of caching like improved scalability and avoiding repeated object recreation. Potential disadvantages discussed are increased memory usage, synchronization complexity, and data durability issues. The document goes on to describe using HttpSession, EJB, and different caching algorithms like FIFO, LRU, and LFU for caching. It provides examples and diagrams to illustrate key caching concepts and components like CacheManager, CacheLoader, and CacheRegion.


















![[Hanoi-August 13] Tech Talk on Caching Solutions](https://cdn.slidesharecdn.com/ss_thumbnails/nitecocachingsolution-130826204343-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
















































