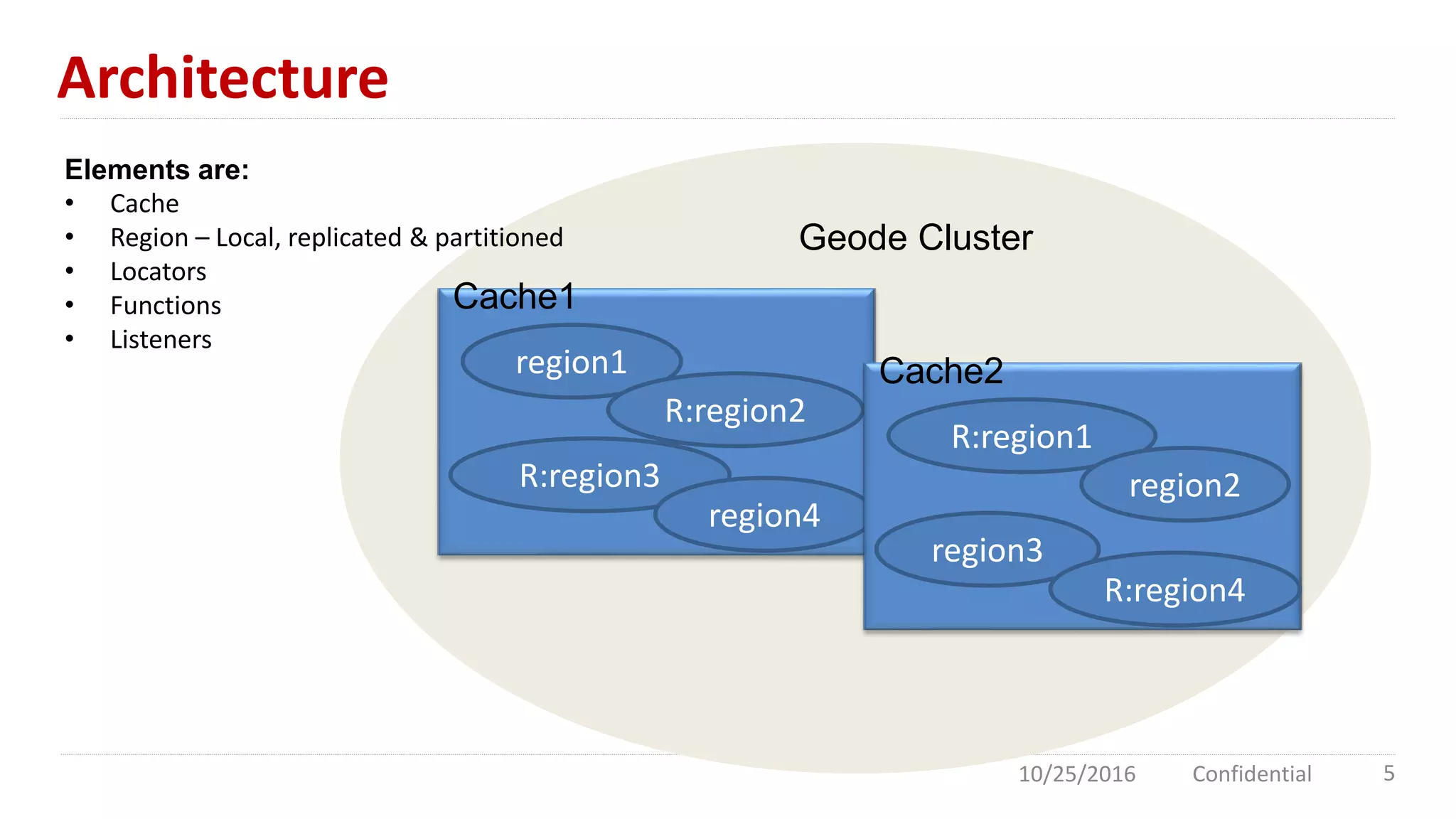
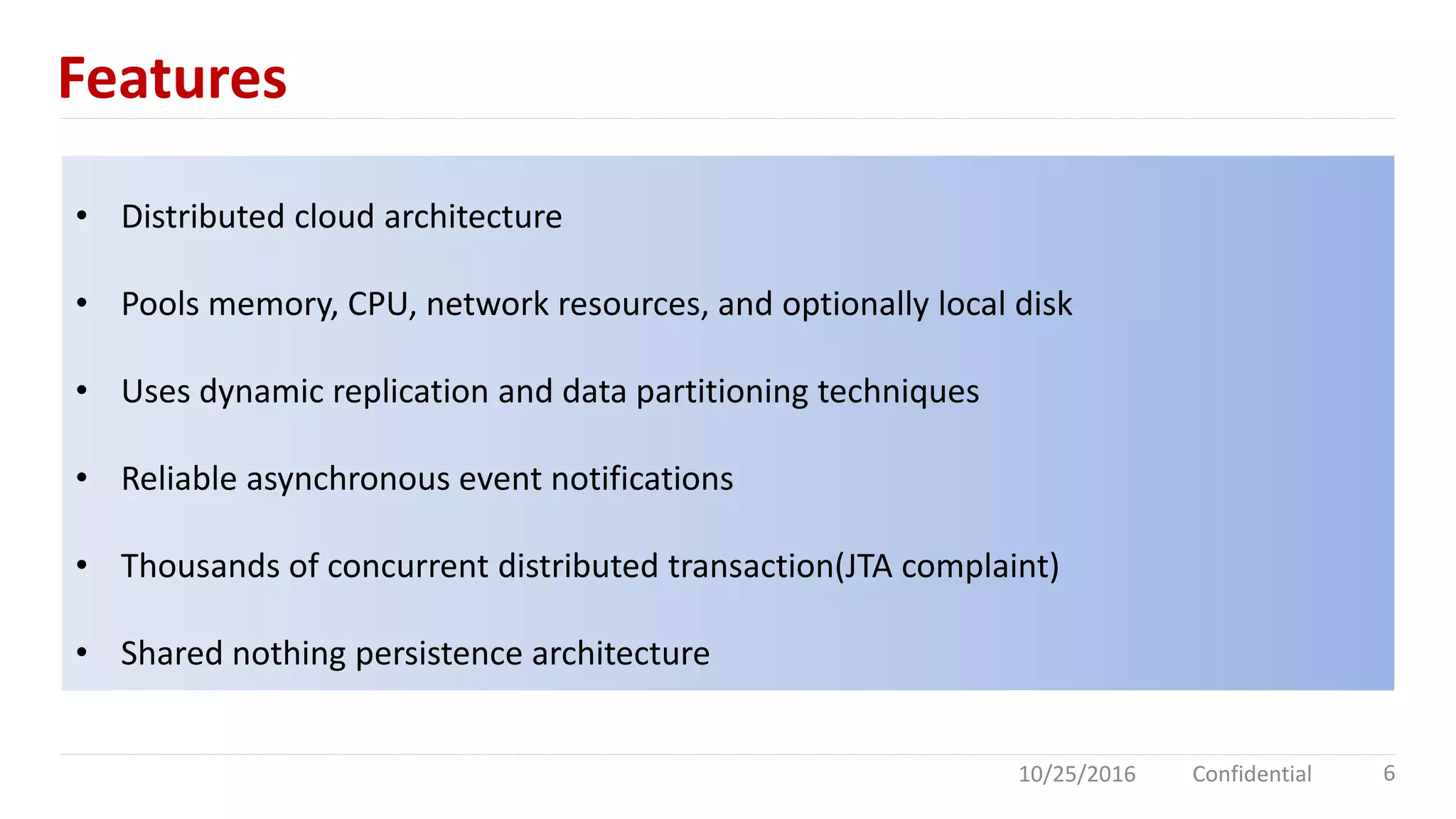
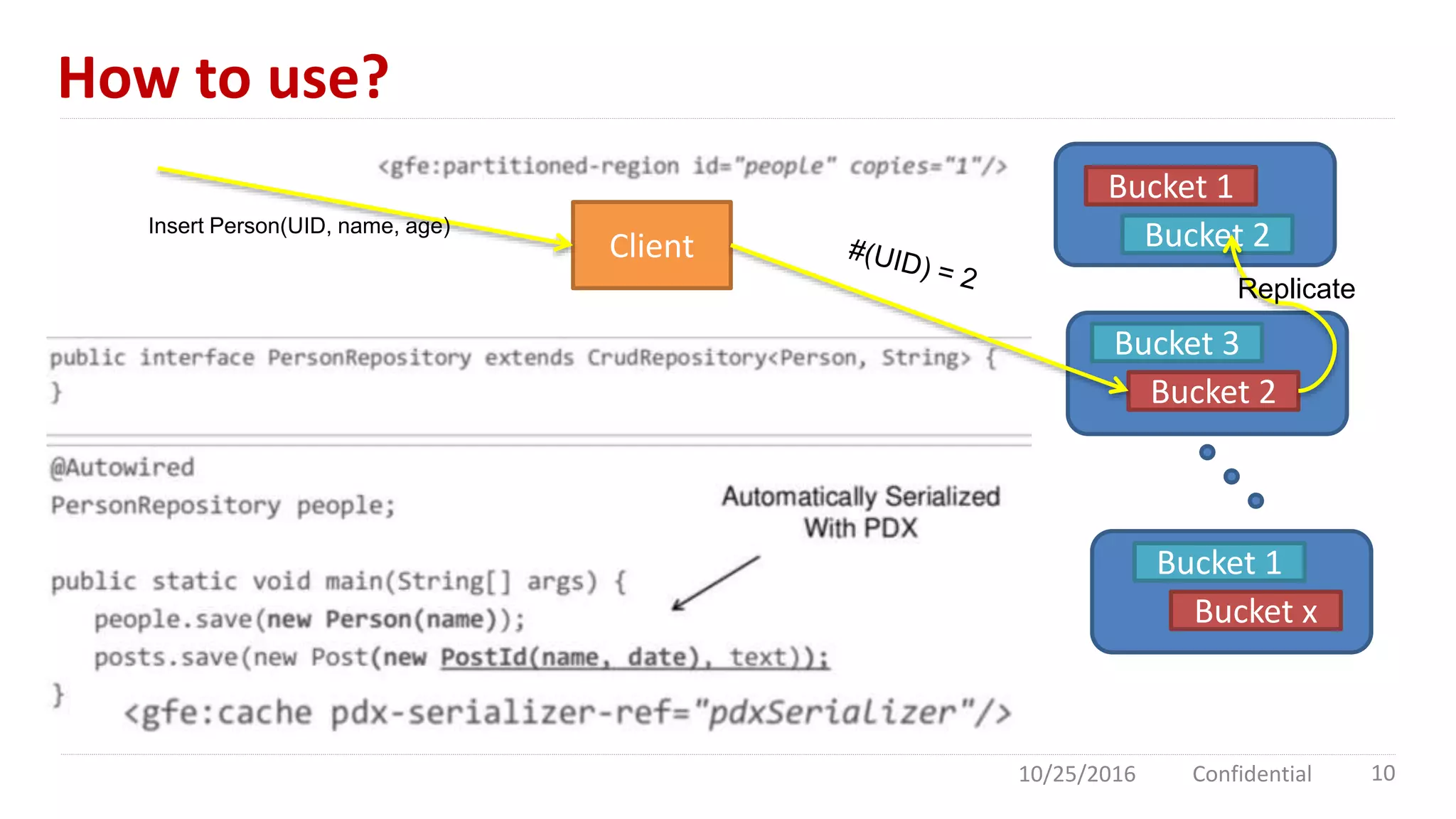
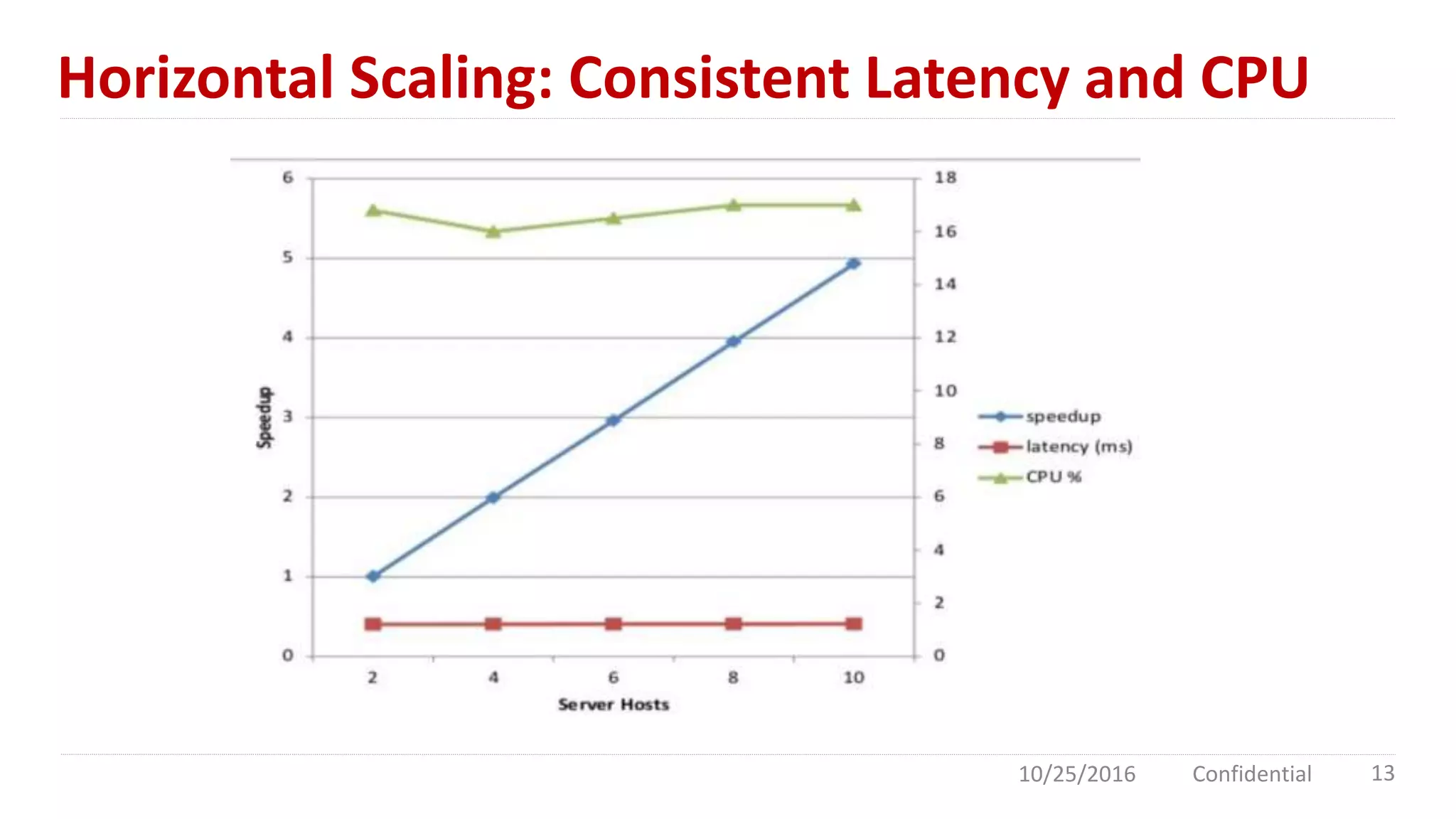
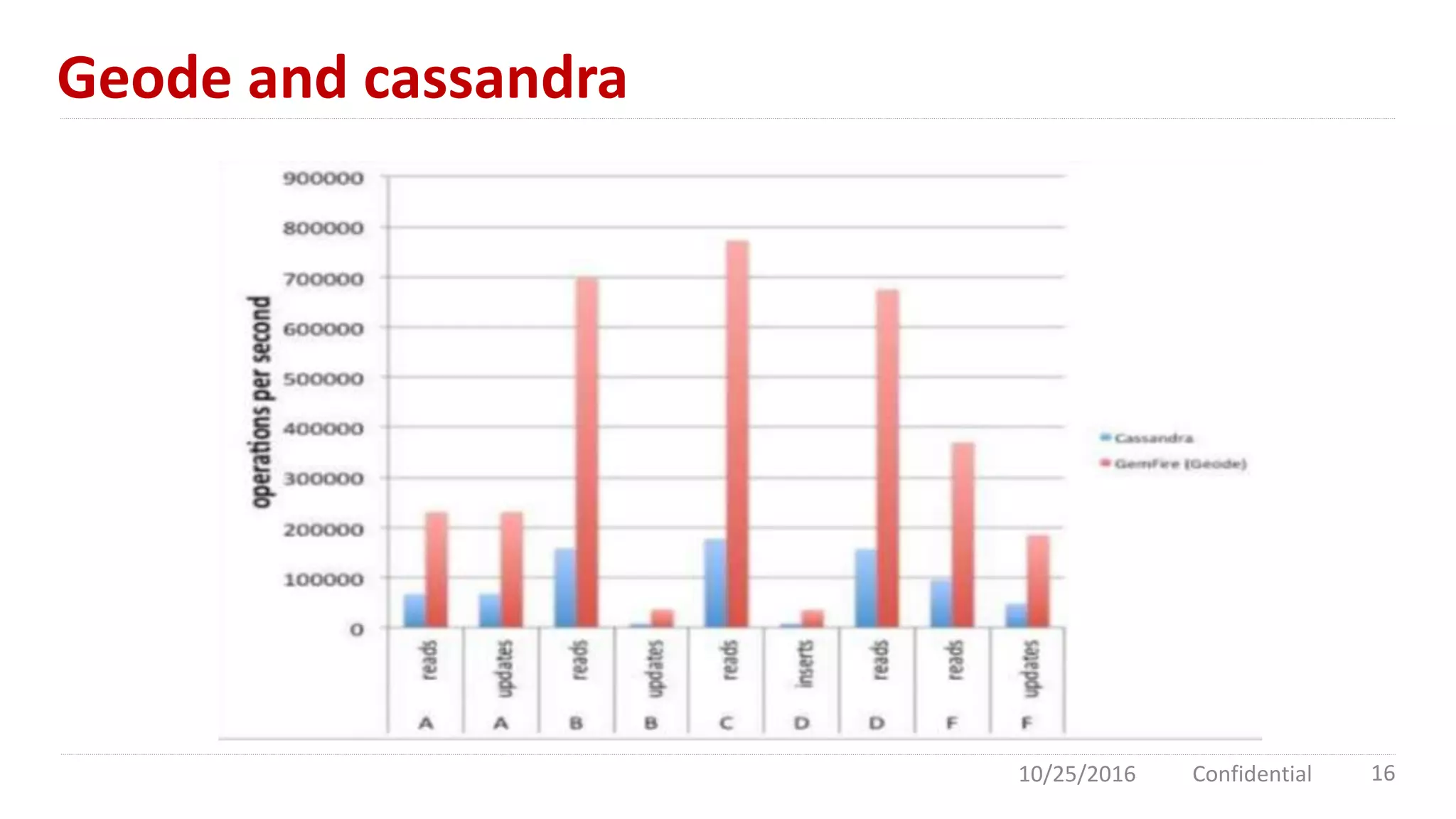
Apache Geode is an in-memory data management platform designed for high concurrency and low latency, primarily used in the financial sector and for high-traffic applications like Southwest Airlines. It features a distributed cloud architecture with dynamic replication, asynchronous event notifications, and robust performance, achieving 10 times the throughput of traditional databases. Comparisons with Redis highlight Geode's superior multi-threading and data redundancy capabilities.



![10/25/2016 Confidential 4
Applications
• GIRE[Rapipago] a leading financial company in Argentina
• 19 million transactions per month
• Southwest Airlines
• Southwest.com is the world’s largest airline website by number of visitors.
• SBI, China Citic bank, Philips, BMW, Union bank, AllState,](https://image.slidesharecdn.com/apachegeode-161025072155/75/Apache-geode-4-2048.jpg)

![Features
10/25/2016 Confidential 8
• HDFS Store – analytics job
• Rebalancing
• Integrated security : DATA_READ, DATA_WRITE, MONITOR, ADMIN [HTTP/HTTPS Authentication for REST ]
• JVSD – for analyzing the performance issues
• Off heap memory
• REST APIs](https://image.slidesharecdn.com/apachegeode-161025072155/75/Apache-geode-8-2048.jpg)














































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)














