Download to read offline



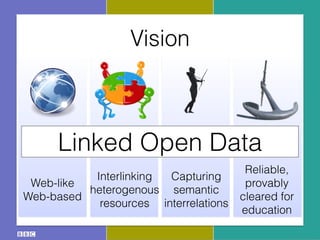
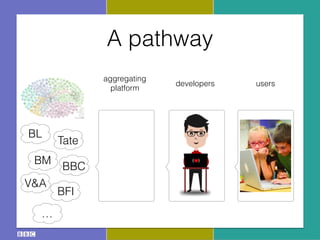
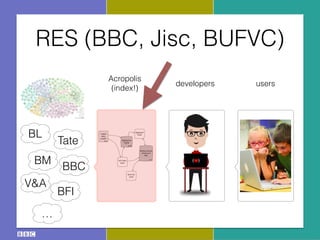
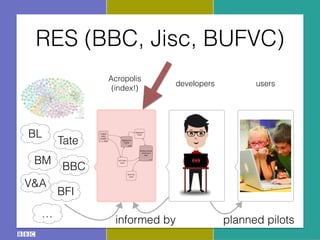
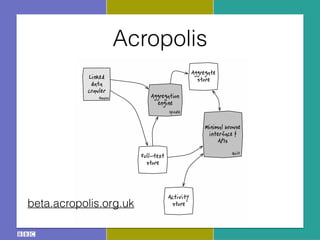
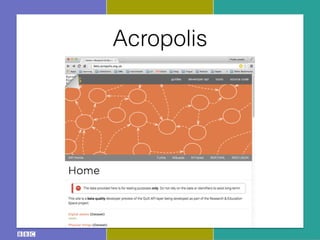
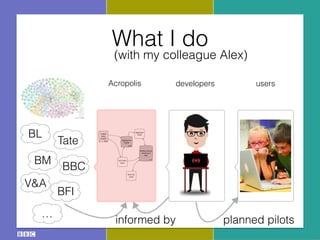
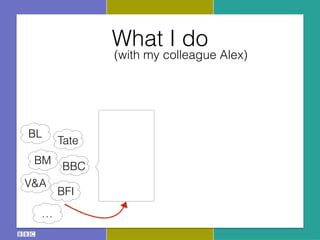
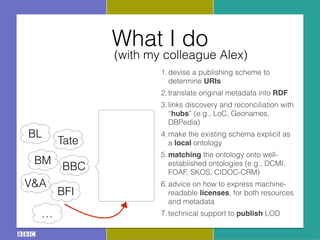










The document discusses the Research and Education Space (RES) project, which aims to create a web-based platform called Acropolis that aggregates and interconnects cultural heritage resources from various institutions like the British Library, British Museum, BBC archive, and others. It describes Acropolis' technical approach of using crawlers, indexes, and APIs to make these resources searchable. It also outlines challenges around standardizing heterogeneous metadata, reliably linking entities, and usability issues regarding tools, licensing, and stakeholder engagement. The author is looking to provide guidance on publishing cultural data as linked open data to help address these challenges.















































