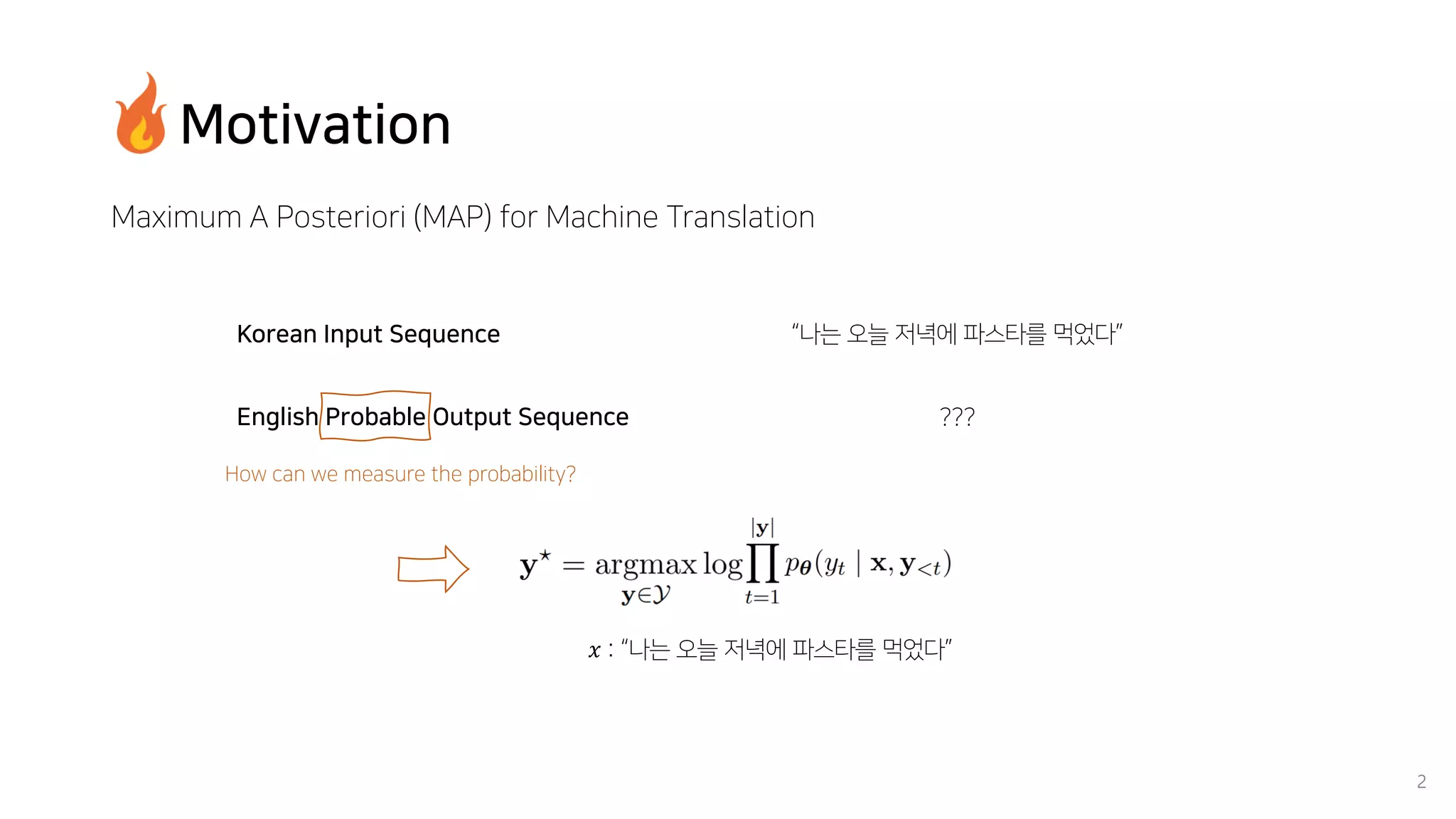
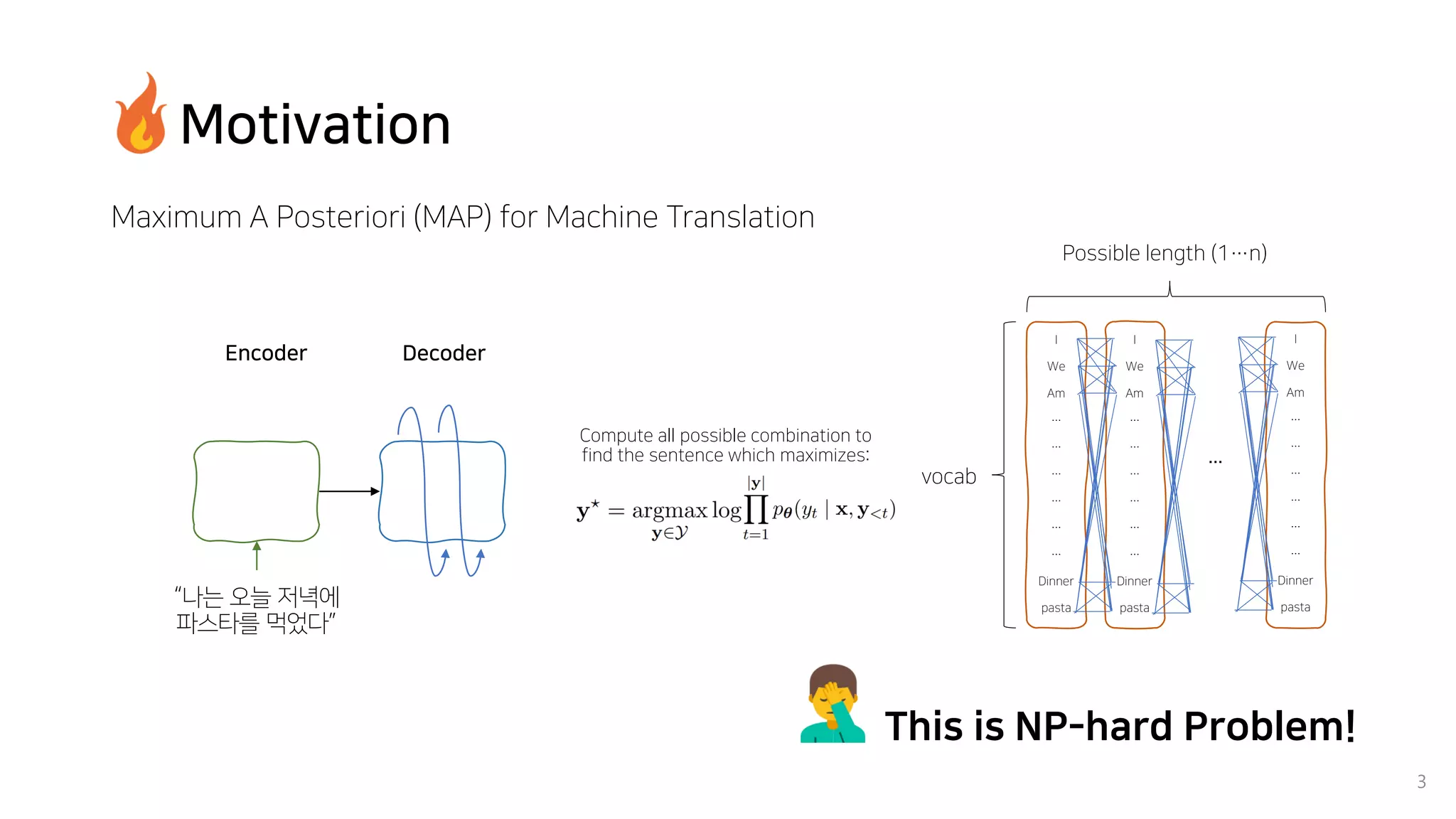
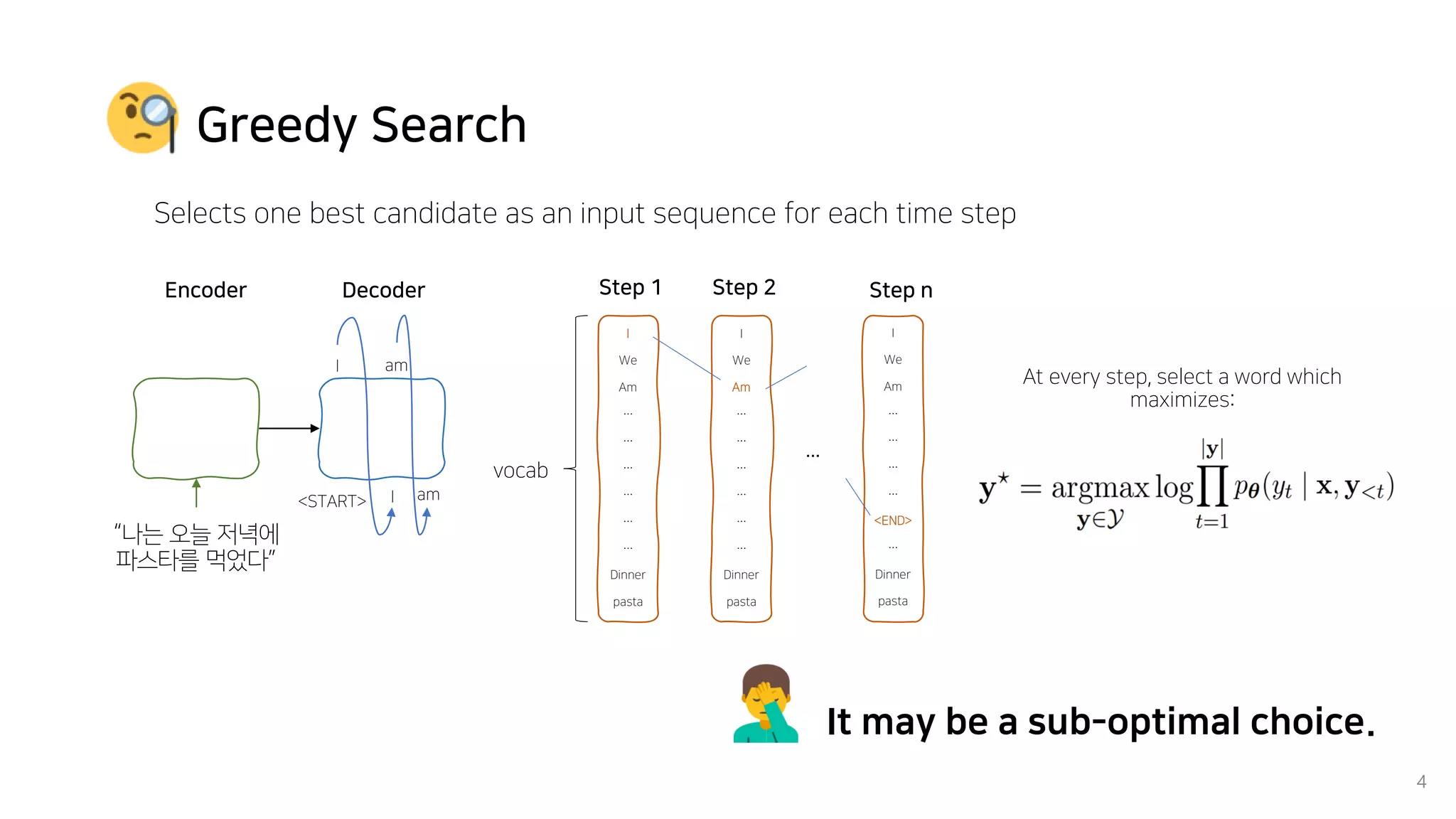
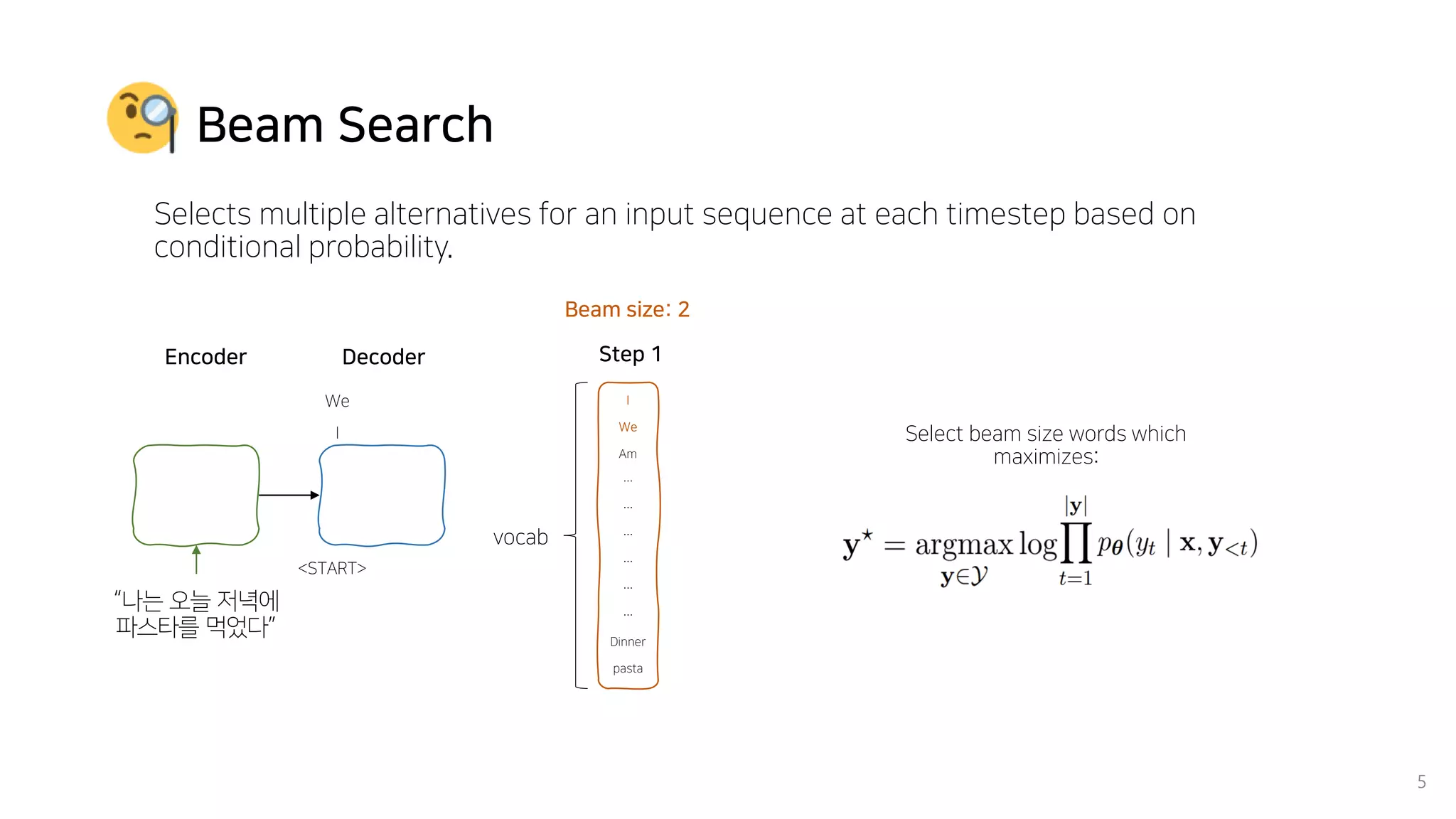
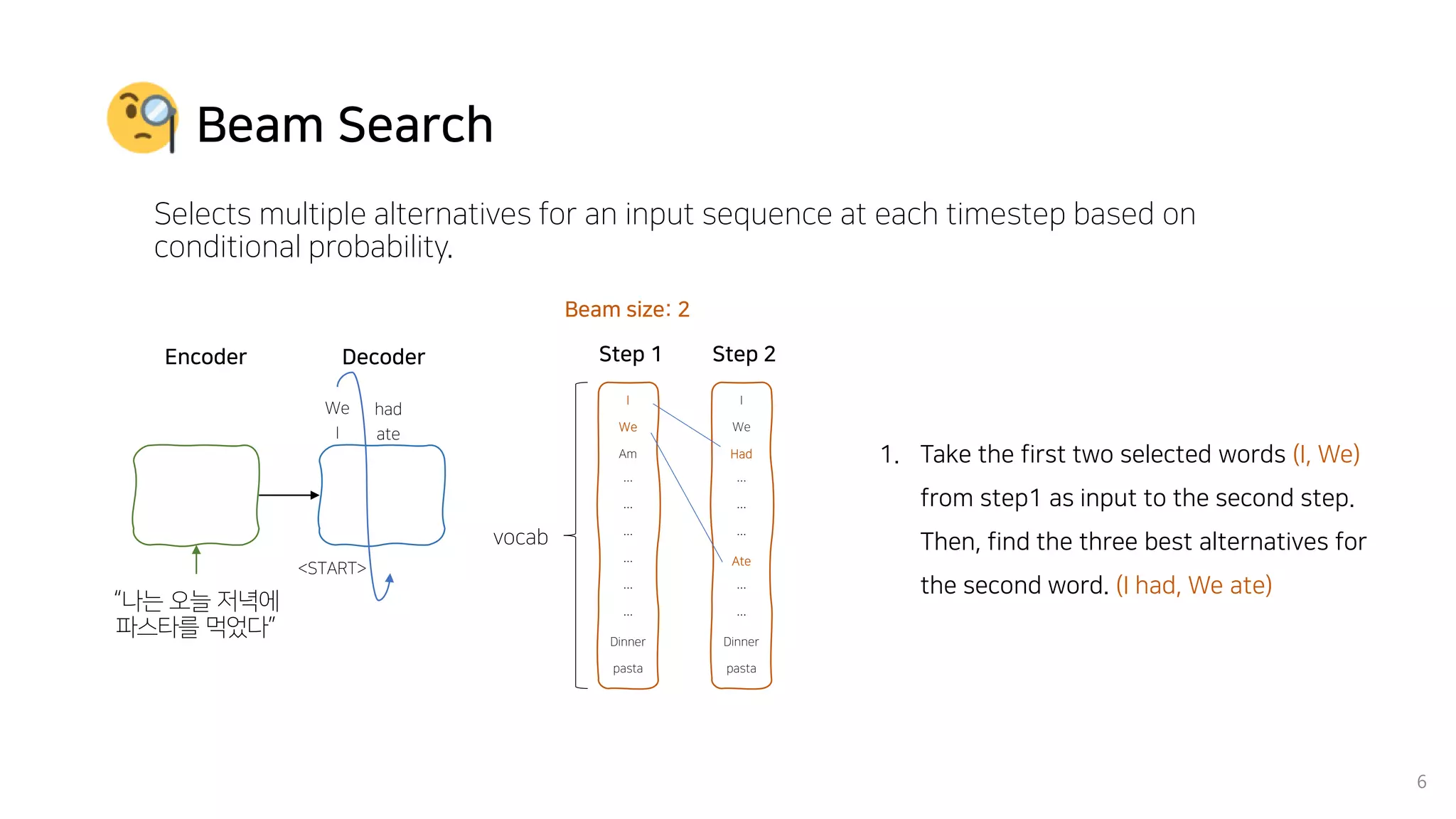
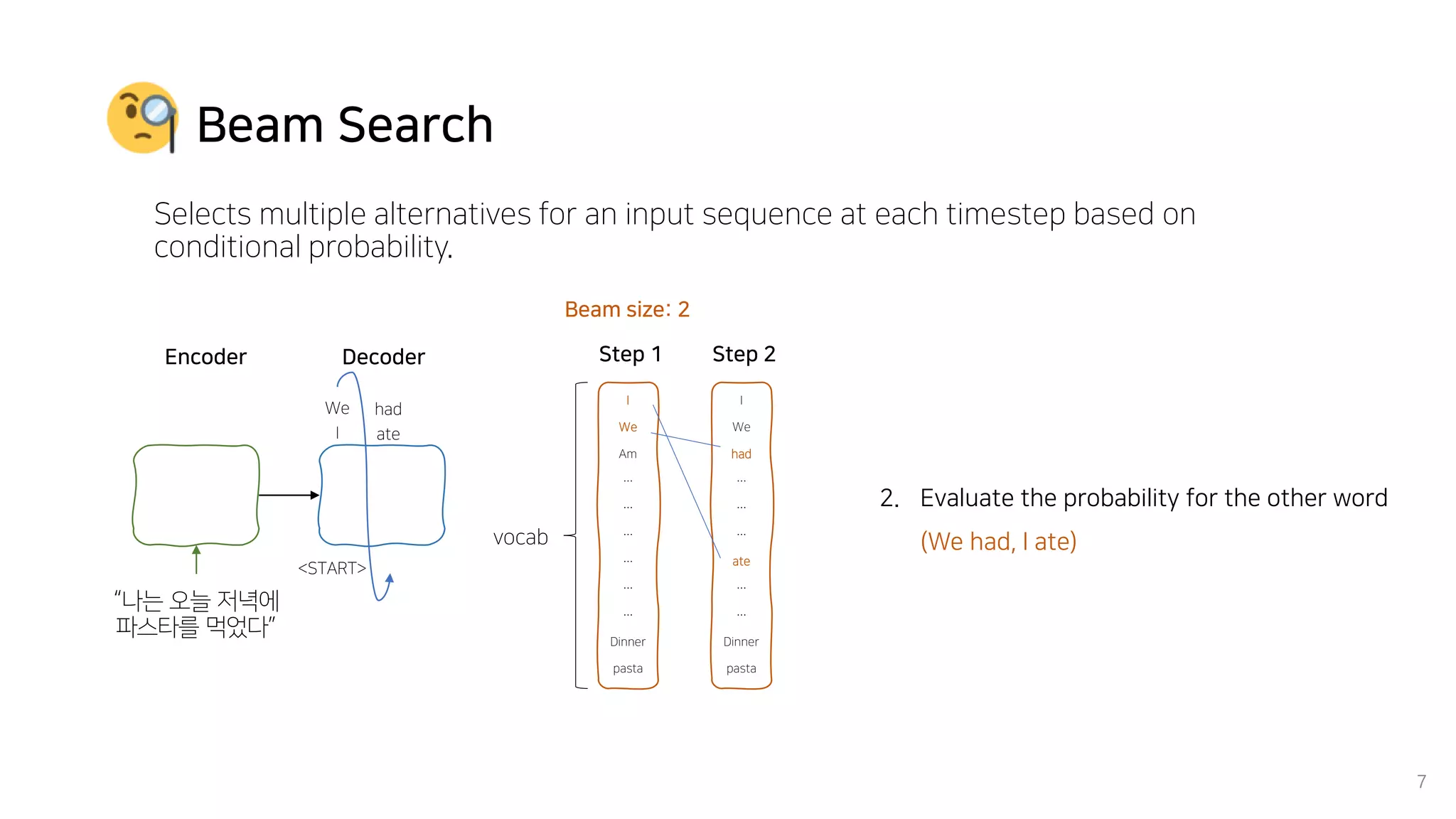
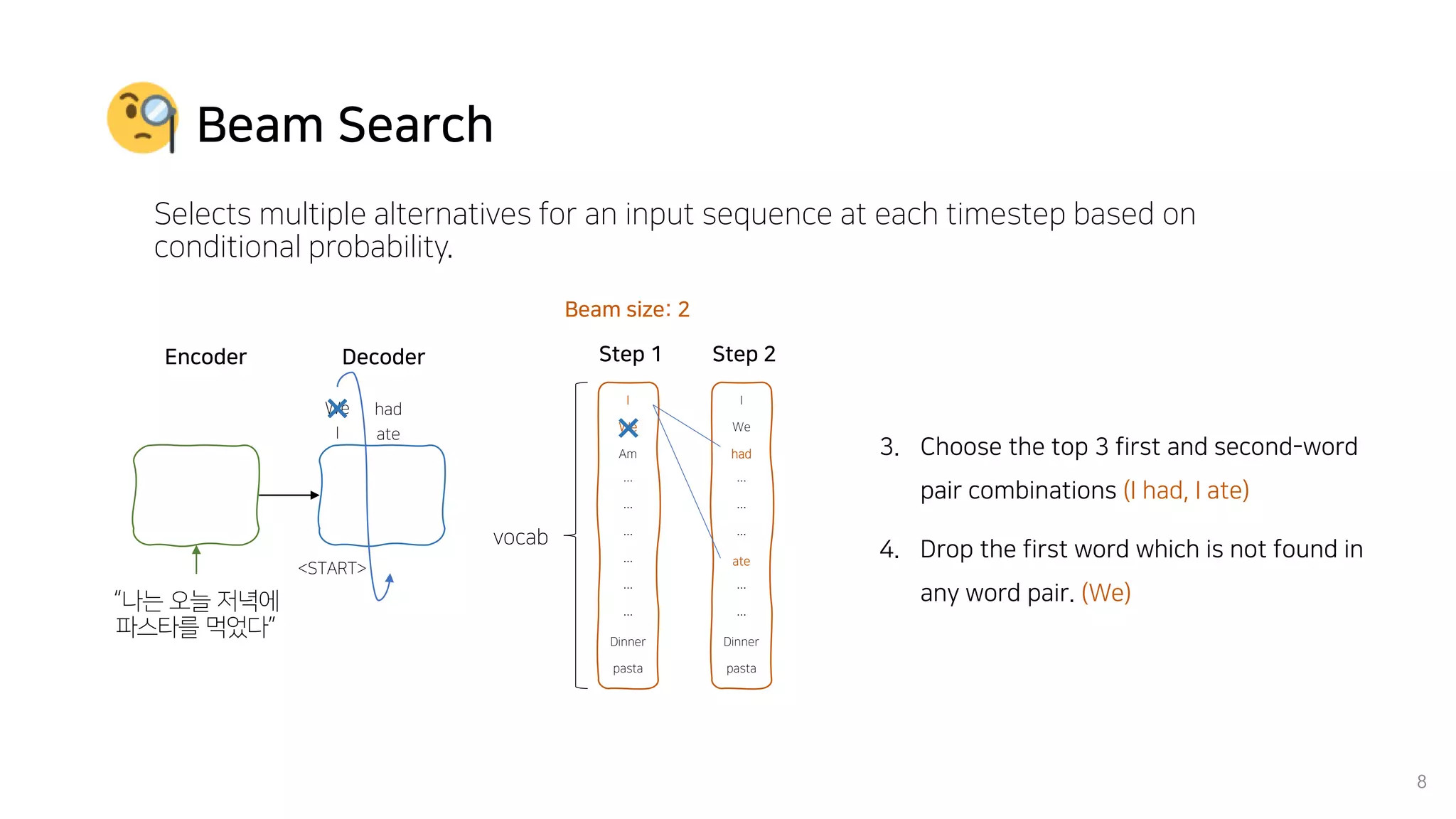
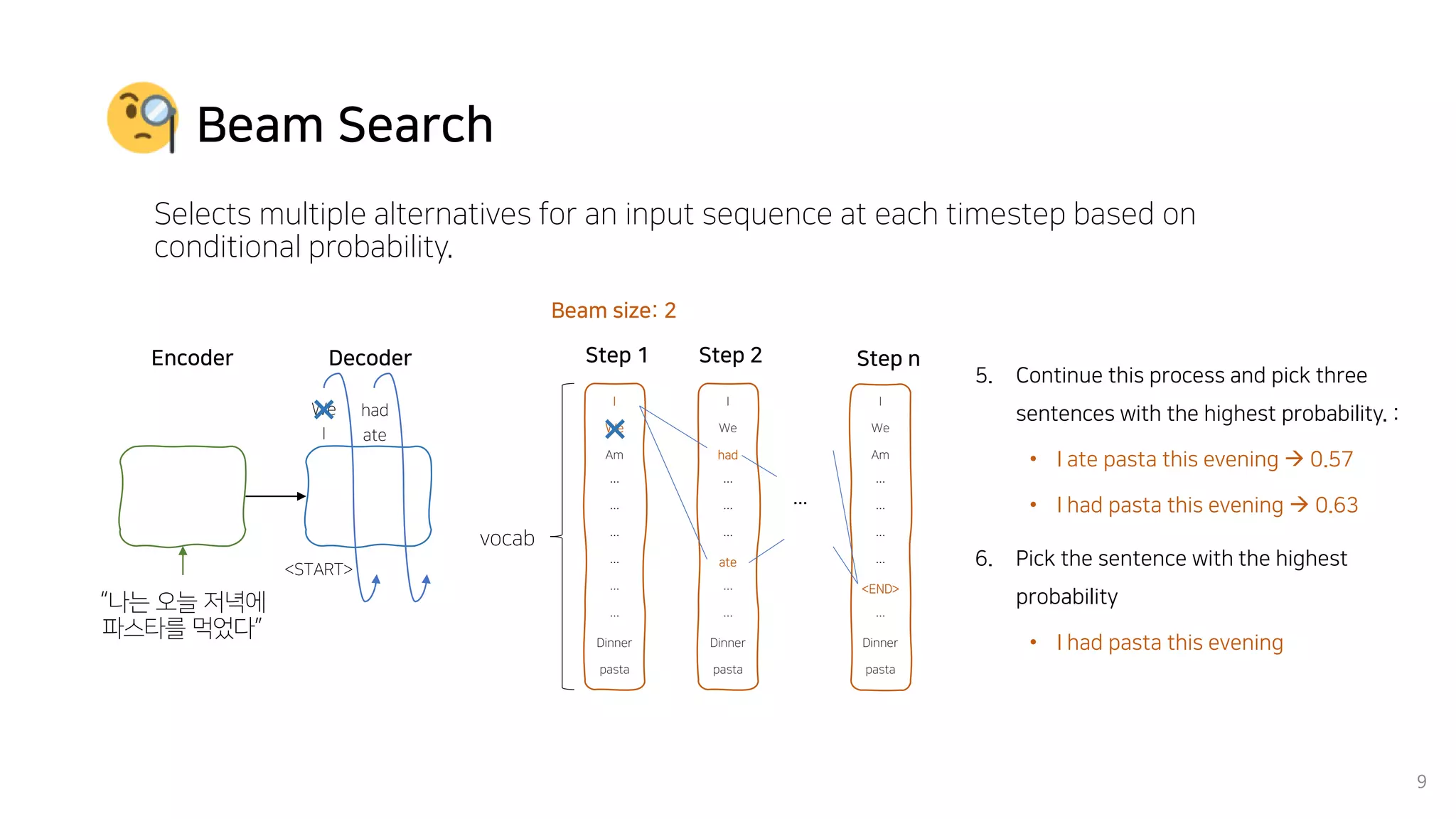
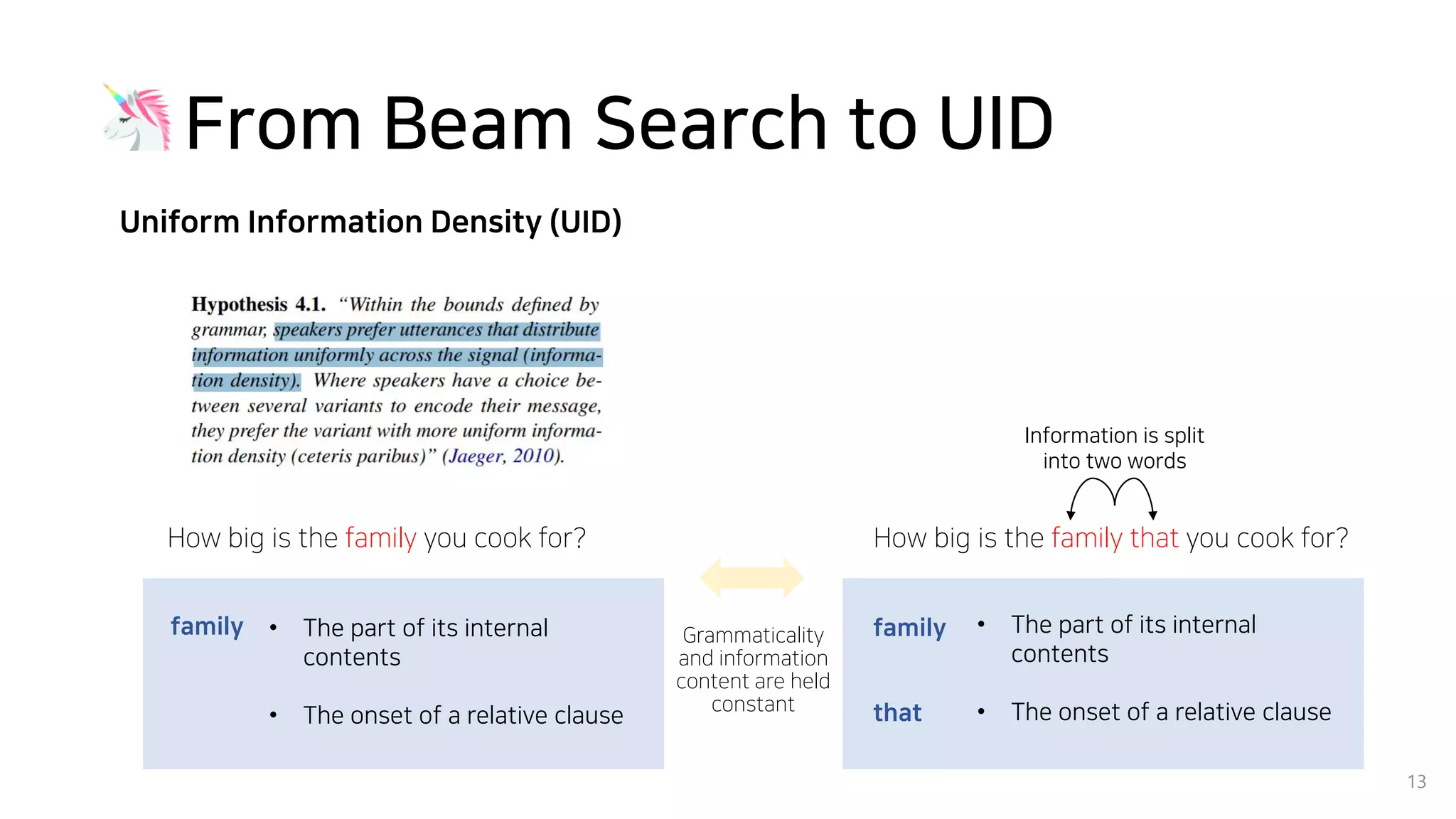
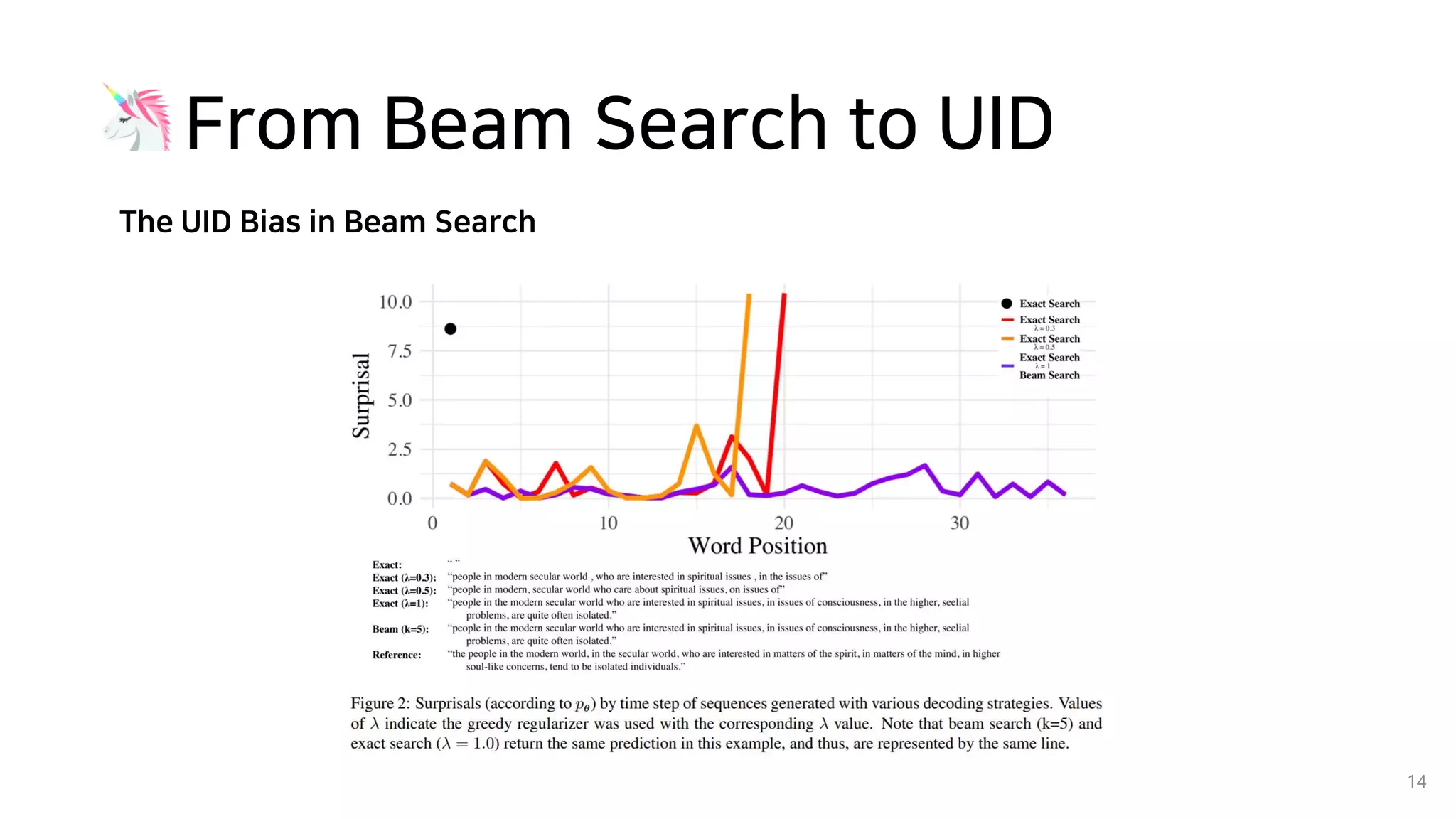
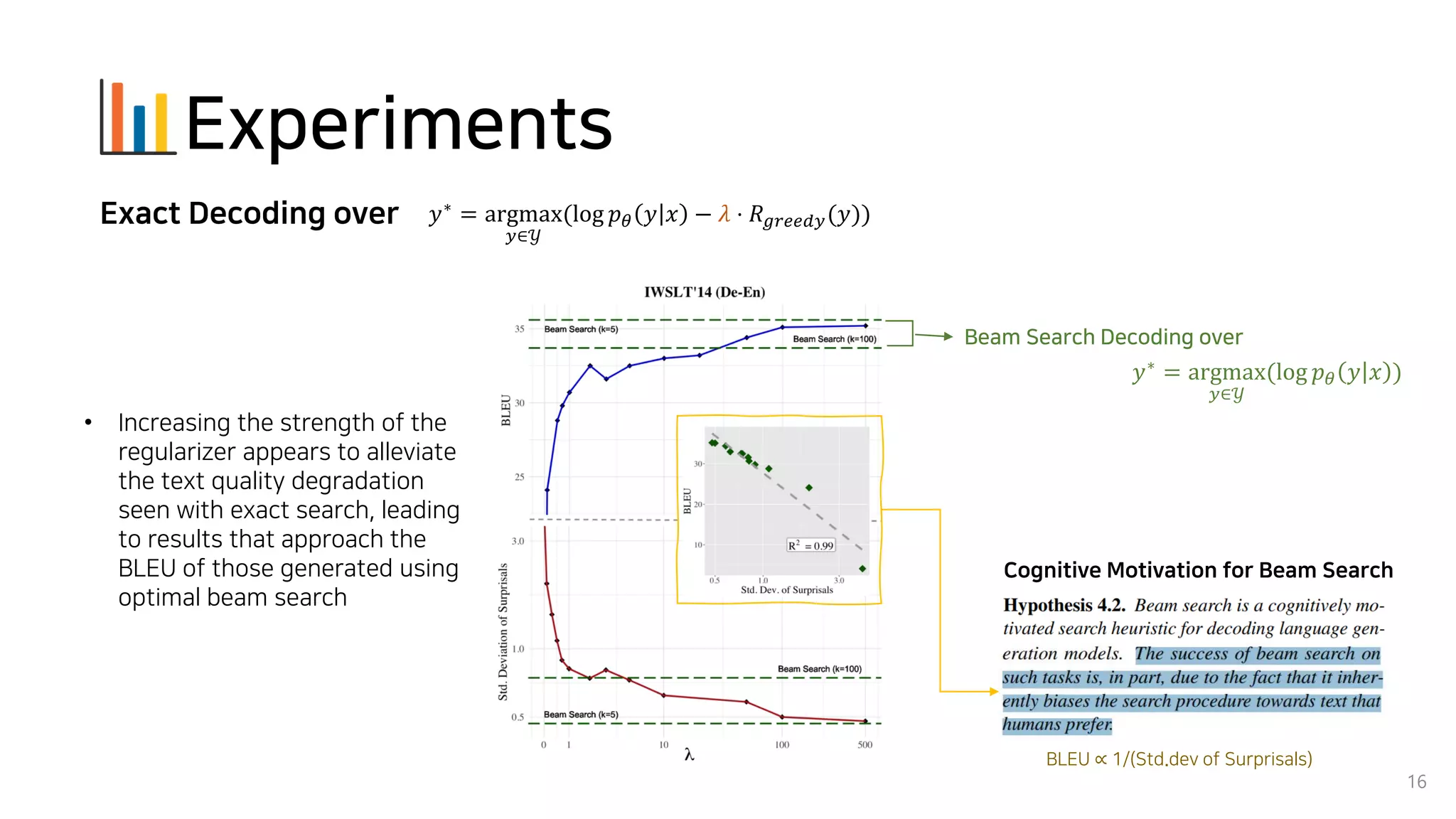
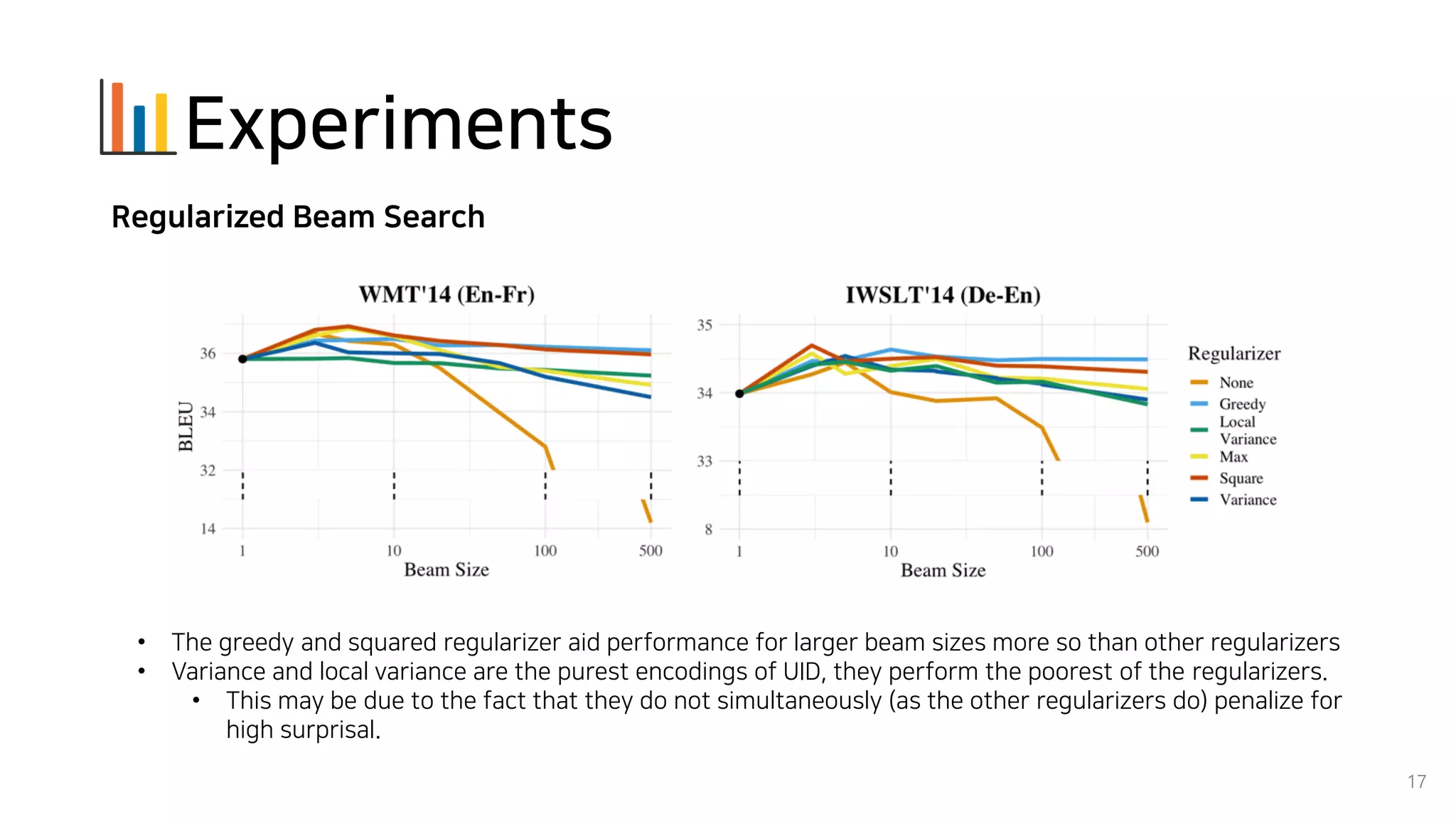
Beam search is an algorithm used in machine translation to find the most probable translation among all possible translations. It aims to overcome the limitations of greedy search which may result in a sub-optimal translation. Beam search considers multiple alternative translations at each time step and selects the top k translations based on conditional probability to carry forward. This allows it to consider a broader search space than greedy search. The paper proposes that beam search inherently biases generated text towards uniform information density, where information is spread evenly over time steps. It presents experiments showing that regularizing the decoding process to explicitly encourage uniform information density can improve generated text quality for larger beam sizes.















![[PR12] PR-036 Learning to Remember Rare Events](https://cdn.slidesharecdn.com/ss_thumbnails/pr12pr-036learningtoremeberrareevents-170917140144-thumbnail.jpg?width=640&height=640&fit=bounds)

























































