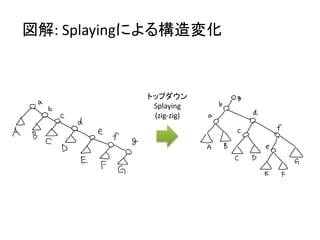
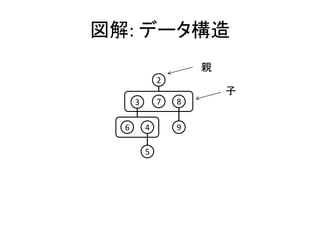
データ構造
• ヒープ規則で順序づけられた多分岐木
– (整数で小さい順なら)親はどの子より小さい
※以後、これを採用して説明します
• data PairingHeap a = E | T a [PairingHeap a]
– ただし、Heapの子に E は登場しない
Fredman, Michael L.; Sedgewick, Robert; Sleator, Daniel D.; Tarjan, Robert E. (1986),
"The pairing heap: a new form of self-adjusting heap“
http://www.lb.cs.cmu.edu/afs/cs.cmu.edu/user/sleator/www/papers/pairing-heaps.pdf
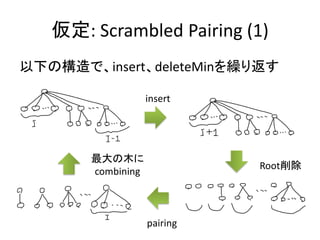
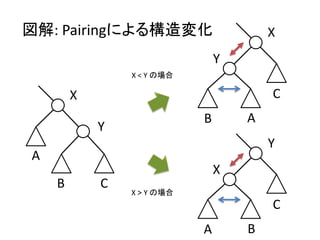
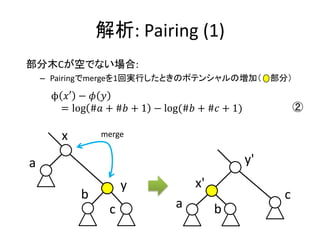
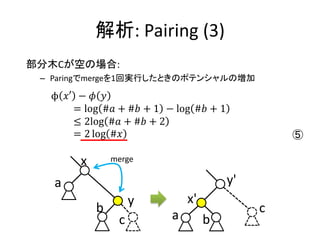
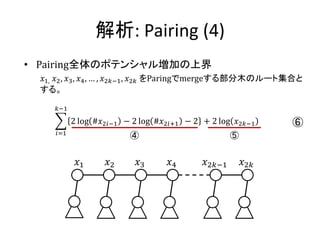
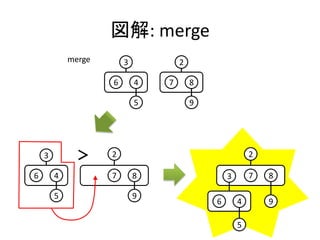
実装: merge
• merge関数はふたつの木のルート要素を比較して、
小さい方を結果のルートに残し、大きい方とその部
分木をルートの部分木として追加する
merge h E = h
merge E h = h
merge h1@(T x hs1) h2@(T y hs2)
| x < y = T x (h2:hs1)
| otherwise = T y (h1:hs2)
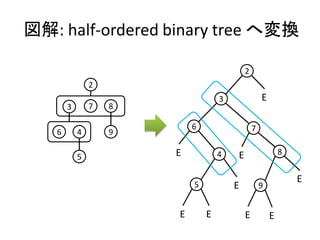
実装: 二分木への変換
• 二分木のデータ構造
data BinTree a = E'
| T' (BinTree a) a (BinTree a)
• 変換
toBinary :: PairingHeap a -> BinTree a
toBinary E = E'
toBinary (T x hs) = T' (tree hs) x E'
where
tree [] = E'
tree ((T x hs1):hs2) = T' (tree hs1) x (tree hs2)
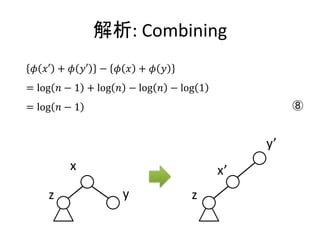
参考文献
• Chris Okasaki, “5.5 Paring Heaps”, Purely Functional Data Structures, Cambridge University
Press (1999)
• Wikipedia, “Paring heap”, on 29 January 2012 at 15:45
http://en.wikipedia.org/wiki/Pairing_heap
• Fredman, Michael L.; Sedgewick, Robert; Sleator, Daniel D.; Tarjan, Robert E.,
"The pairing heap: a new form of self-adjusting heap“, 1986
http://www.lb.cs.cmu.edu/afs/cs.cmu.edu/user/sleator/www/papers/pairing-heaps.pdf




![データ構造
• ヒープ規則で順序づけられた多分岐木
– (整数で小さい順なら)親はどの子より小さい
※以後、これを採用して説明します
• data PairingHeap a = E | T a [PairingHeap a]
– ただし、Heapの子に E は登場しない
Fredman, Michael L.; Sedgewick, Robert; Sleator, Daniel D.; Tarjan, Robert E. (1986),
"The pairing heap: a new form of self-adjusting heap“
http://www.lb.cs.cmu.edu/afs/cs.cmu.edu/user/sleator/www/papers/pairing-heaps.pdf](https://image.slidesharecdn.com/pairingheap-120304023946-phpapp02/85/PFDS-5-5-Pairing-heap-3-320.jpg)




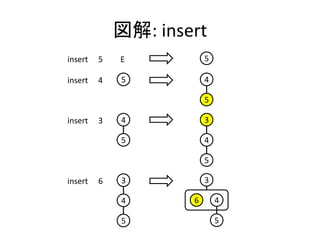
![実装: insert
• insert関数は追加する要素に対して新しい木を作り、
追加先の木にマージする。
insert x h = merge (T x []) h](https://image.slidesharecdn.com/pairingheap-120304023946-phpapp02/85/PFDS-5-5-Pairing-heap-10-320.jpg)
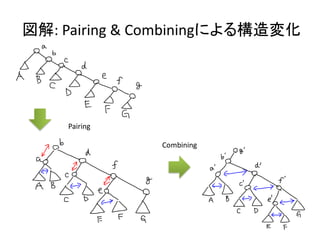
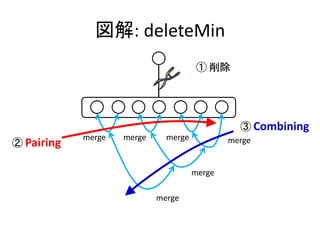
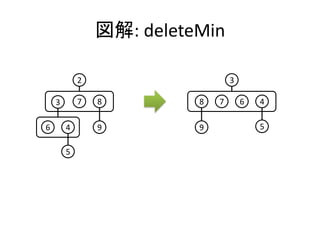
![実装: deleteMin
• ルートを取り除き、部分木をマージする。
mergePairs [] = E
mergePairs [h] = h
mergePairs (h1:h2:hs) =
merge (merge h1 h2) mergePairs hs
deleteMin (T x hs) = mergePairs hs](https://image.slidesharecdn.com/pairingheap-120304023946-phpapp02/85/PFDS-5-5-Pairing-heap-12-320.jpg)
![実装: 二分木への変換
• 二分木のデータ構造
data BinTree a = E'
| T' (BinTree a) a (BinTree a)
• 変換
toBinary :: PairingHeap a -> BinTree a
toBinary E = E'
toBinary (T x hs) = T' (tree hs) x E'
where
tree [] = E'
tree ((T x hs1):hs2) = T' (tree hs1) x (tree hs2)](https://image.slidesharecdn.com/pairingheap-120304023946-phpapp02/85/PFDS-5-5-Pairing-heap-15-320.jpg)