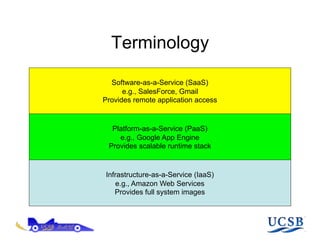
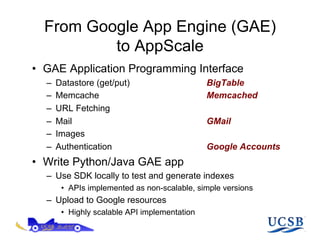
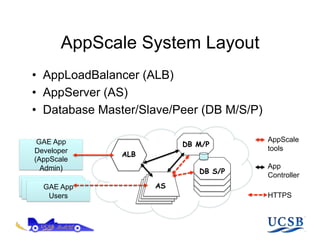
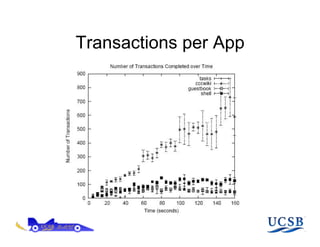
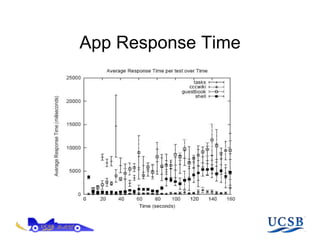
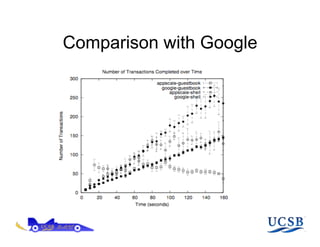
The document discusses AppScale, an open-source platform as a service that enables scalable deployment and management of applications on cloud infrastructure, emphasizing the use of Google App Engine (GAE) APIs and transitioning them to AppScale's pluggable components. It covers the system architecture, performance testing, and potential improvements, including fault tolerance and support for various databases. Future work is aimed at extending capabilities beyond web services and integrating high-performance computing support.

































































![Java Web Programming on Google Cloud Platform [1/3] : Google App Engine](https://cdn.slidesharecdn.com/ss_thumbnails/gae-chapter1-130106064147-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)























