Download as PDF, PPTX








![Think 2019 / 2238 / Feb, 2019 / © 2019 IBM Corporation
SELECT … INTO
<Table Locator> [STORED AS CSV | PARQUET | JSON]
PARTITIONED [BY (<column list>)]
[INTO <num> BUCKETS]
[EVERY <num> ROWS]
BY: Produces Hive Style Partitioning
INTO: Produced fix number of partitions (hash partitioned)
EVERY: Produces partitioned of even size (e.g. for pagination)
Table Partitioning Definition](https://image.slidesharecdn.com/think20192238whatidontneedadatabase-190306144728/85/IBM-THINK-2019-What-I-Don-t-Need-a-Database-to-Do-All-That-with-SQL-14-320.jpg)












![Table Locators
Think 2019 / 2238 / Feb, 2019 / © 2019 IBM Corporation
cos://<endpoint>/<bucket>/[<prefix>] <format definition>
Endpoint – of your object storage bucket or a short alias
E.g. s3.us-south.cloud-object-storage.appdomain.cloud or us-south
Bucket – name in object storage
Prefix – one or multiple objects (e.g., table partitions) with same prefix
Used in FROM clauses for input data and in target field for result set data
Examples:
cos://us-south/myBucket/myFolder/mySubFolder/myData.parquet
cos://us-geo/otherBucket/myData
cos://us-geo/otherBucket/myData/part
cos://eu-geo/newBucket/](https://image.slidesharecdn.com/think20192238whatidontneedadatabase-190306144728/85/IBM-THINK-2019-What-I-Don-t-Need-a-Database-to-Do-All-That-with-SQL-32-320.jpg)
![Think 2019 / 2238 / Feb, 2019 / © 2019 IBM Corporation
<Table Locator> [STORED AS CSV | PARQUET | JSON]
• Specifies the data format of the input data
• Table schema is automatically inferred at SQL execution time
• Clause is optional, the default is CSV
• Additional parameters for CSV:
• E.g.: FIELDS TERMINATEY BY ‘t’ NOHEADER
Table Format Definition](https://image.slidesharecdn.com/think20192238whatidontneedadatabase-190306144728/85/IBM-THINK-2019-What-I-Don-t-Need-a-Database-to-Do-All-That-with-SQL-33-320.jpg)




![Notices and disclaimers
continued
38Think 2019 / DOC ID / Month XX, 2019 / © 2019 IBM Corporation
Information concerning non-IBM products was obtained from the
suppliers of those products, their published announcements or other
publicly available sources. IBM has not tested those products about this
publication and cannot confirm the accuracy of performance,
compatibility or any other claims related to non-IBM products.
Questions on the capabilities of non-IBM products should be addressed
to the suppliers of those products. IBM does not warrant the quality of
any third-party products, or the ability of any such third-party products
to interoperate with IBM’s products. IBM expressly disclaims all
warranties, expressed or implied, including but not limited to, the
implied warranties of merchantability and fitness for a purpose.
The provision of the information contained herein is not intended to, and
does not, grant any right or license under any IBM patents, copyrights,
trademarks or other intellectual property right.
IBM, the IBM logo, ibm.com and [names of other referenced IBM
products and services used in the presentation] are trademarks of
International Business Machines Corporation, registered in many
jurisdictions worldwide. Other product and service names might
be trademarks of IBM or other companies. A current list of IBM
trademarks is available on the Web at “Copyright and trademark
information” at: www.ibm.com/legal/copytrade.shtml.](https://image.slidesharecdn.com/think20192238whatidontneedadatabase-190306144728/85/IBM-THINK-2019-What-I-Don-t-Need-a-Database-to-Do-All-That-with-SQL-38-320.jpg)


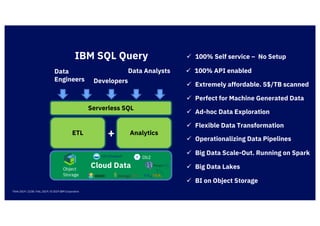
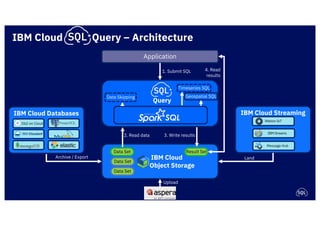
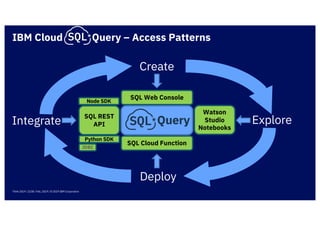
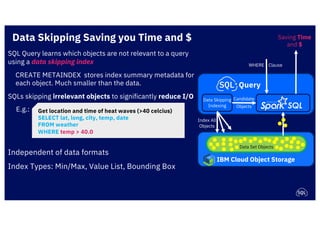
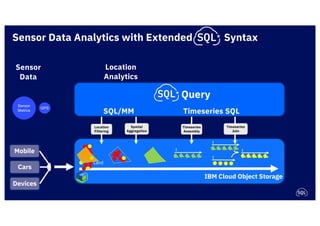
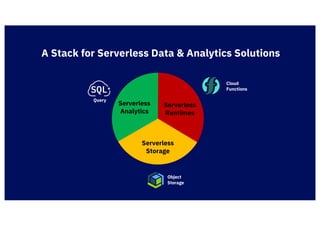
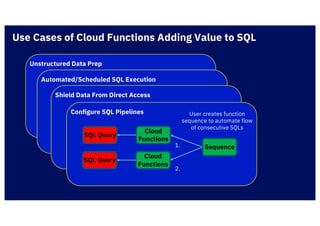
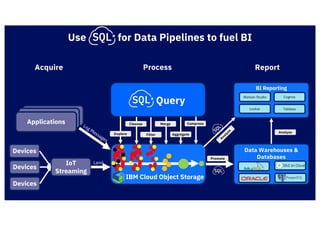
The document discusses IBM's cloud SQL query capabilities that allow data analysis without traditional database management, utilizing a serverless architecture for flexible data exploration and processing. It highlights best practices for data organization, query optimization, and the advantages of using advanced SQL features for timeseries and spatial data analytics. Furthermore, it emphasizes affordability, scalability, and integration with various data formats and analytics tools.









































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)

