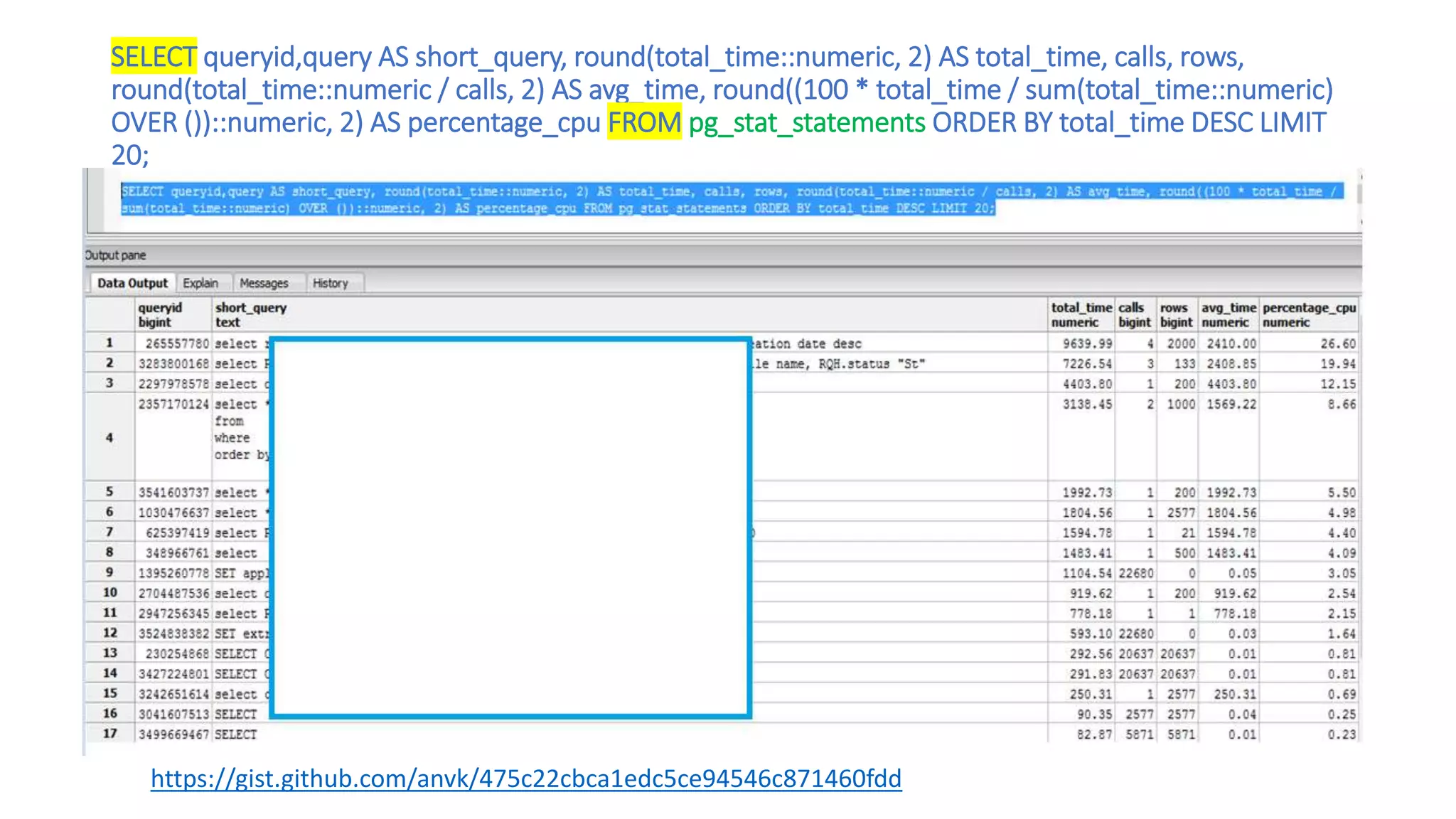
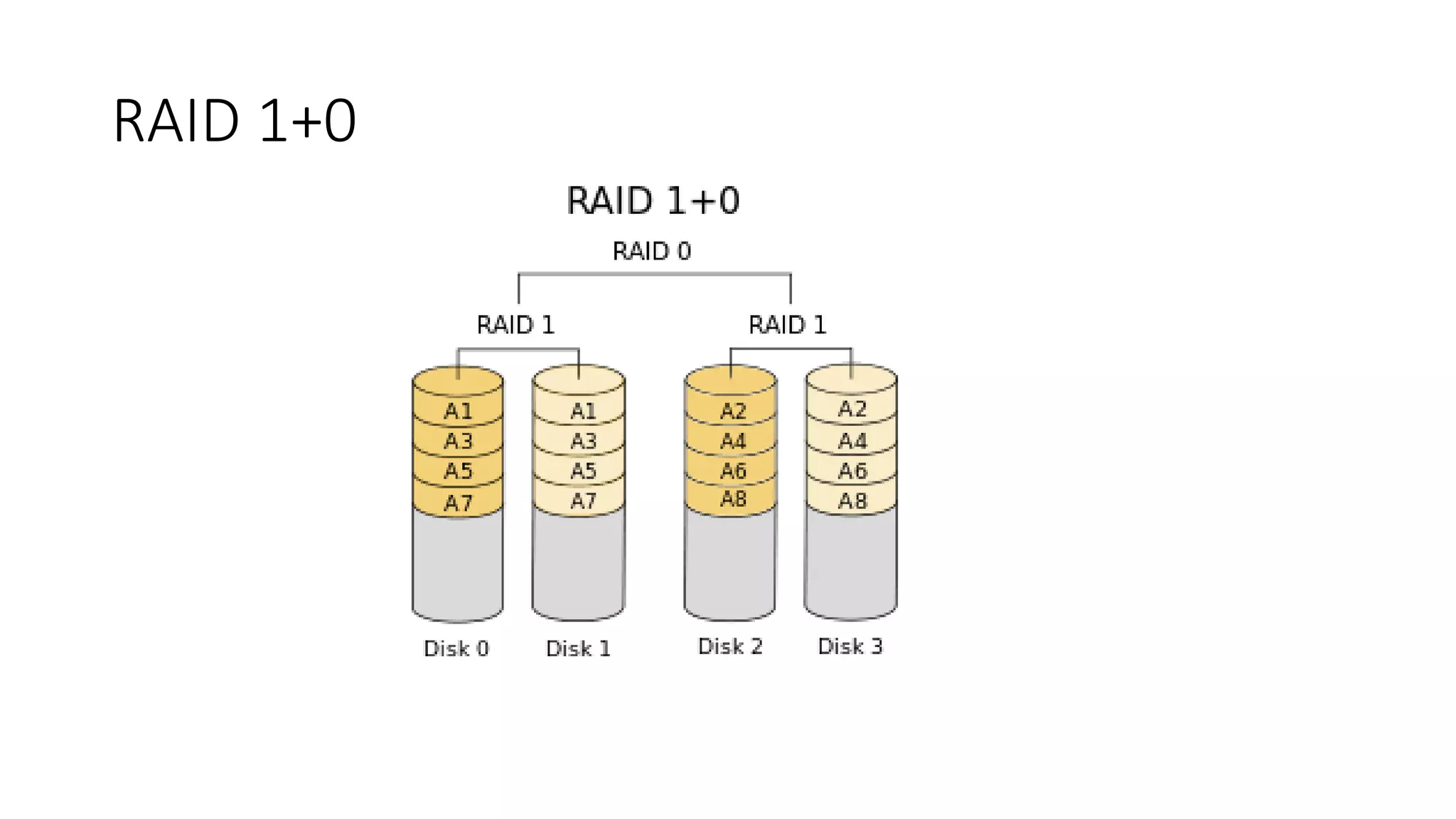
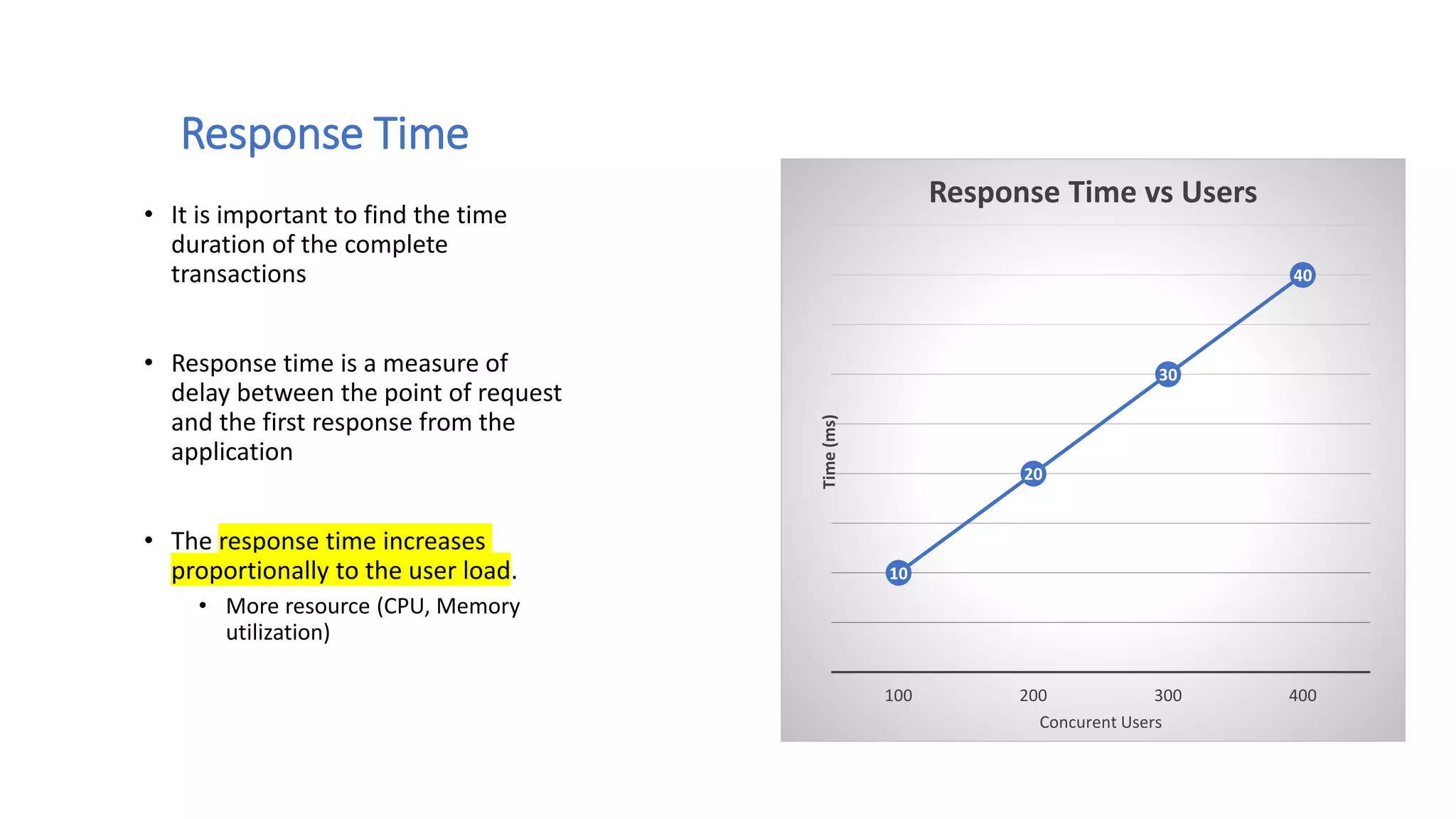
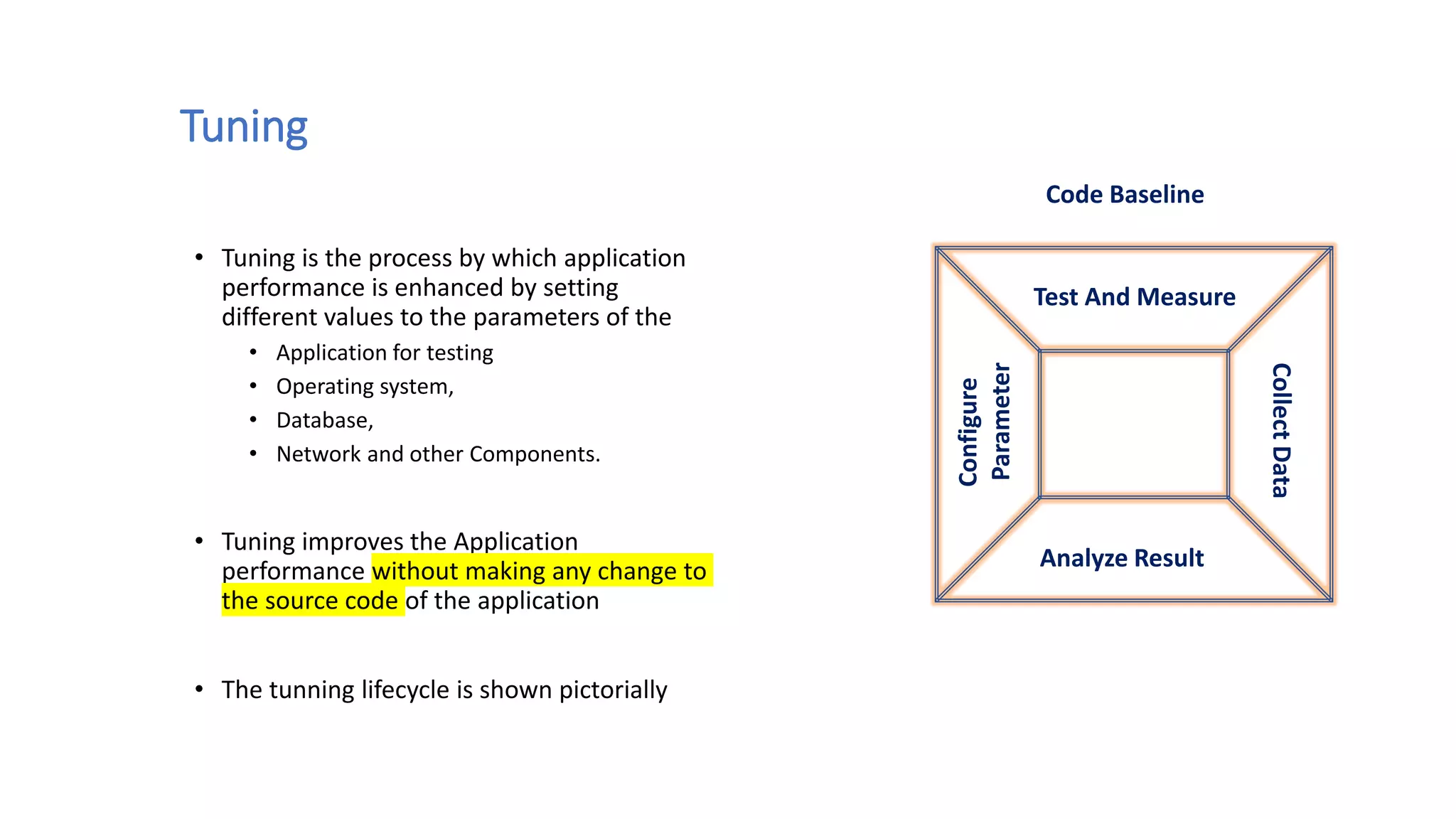
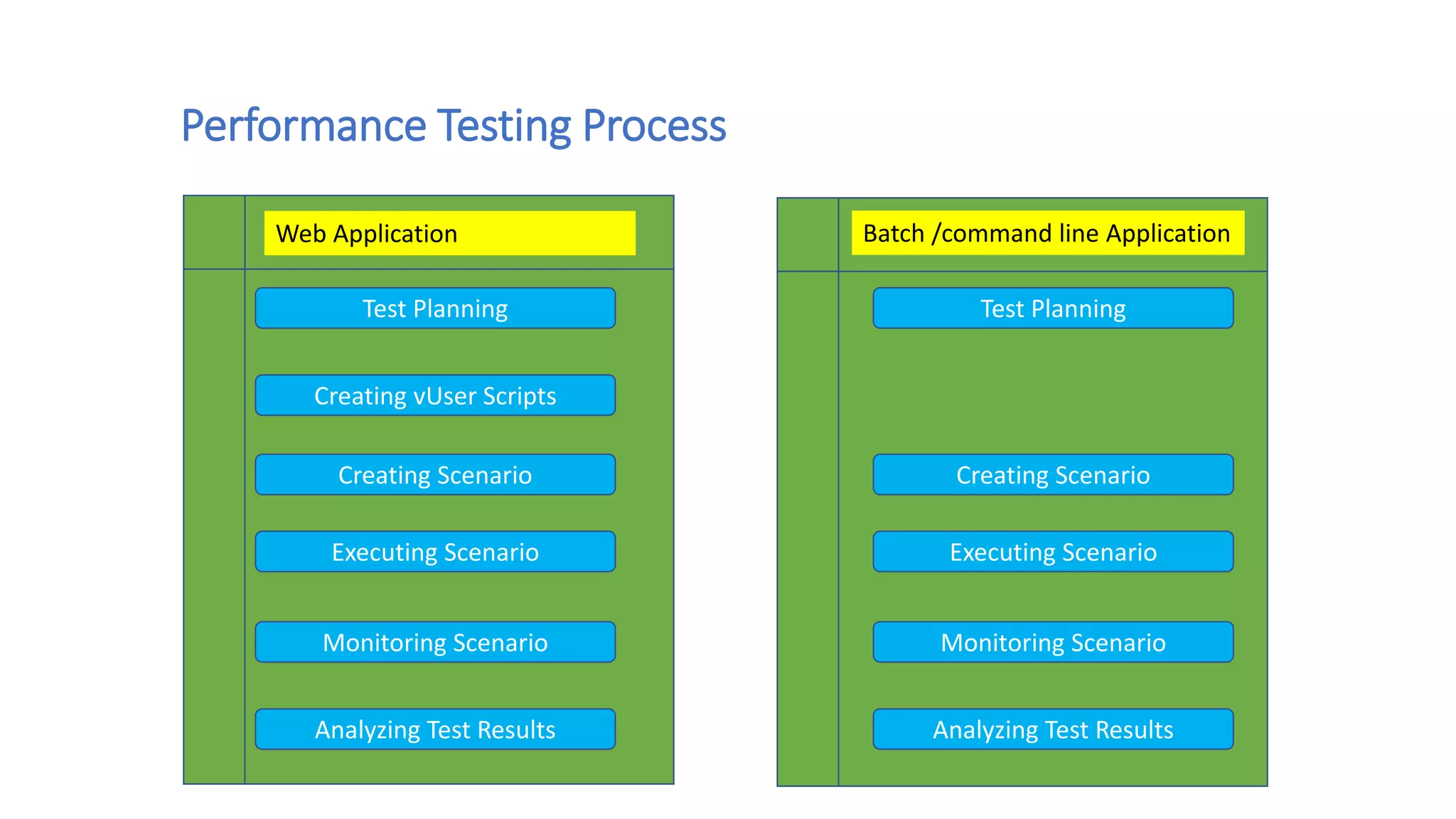
This document discusses performance engineering for batch and web applications. It begins by outlining why performance testing is important. Key factors that influence performance testing include response time, throughput, tuning, and benchmarking. Throughput represents the number of transactions processed in a given time period and should increase linearly with load. Response time is the duration between a request and first response. Tuning improves performance by configuring parameters without changing code. The performance testing process involves test planning, creating test scripts, executing tests, monitoring tests, and analyzing results. Methods for analyzing heap dumps and thread dumps to identify bottlenecks are also provided. The document concludes with tips for optimizing PostgreSQL performance by adjusting the shared_buffers configuration parameter.







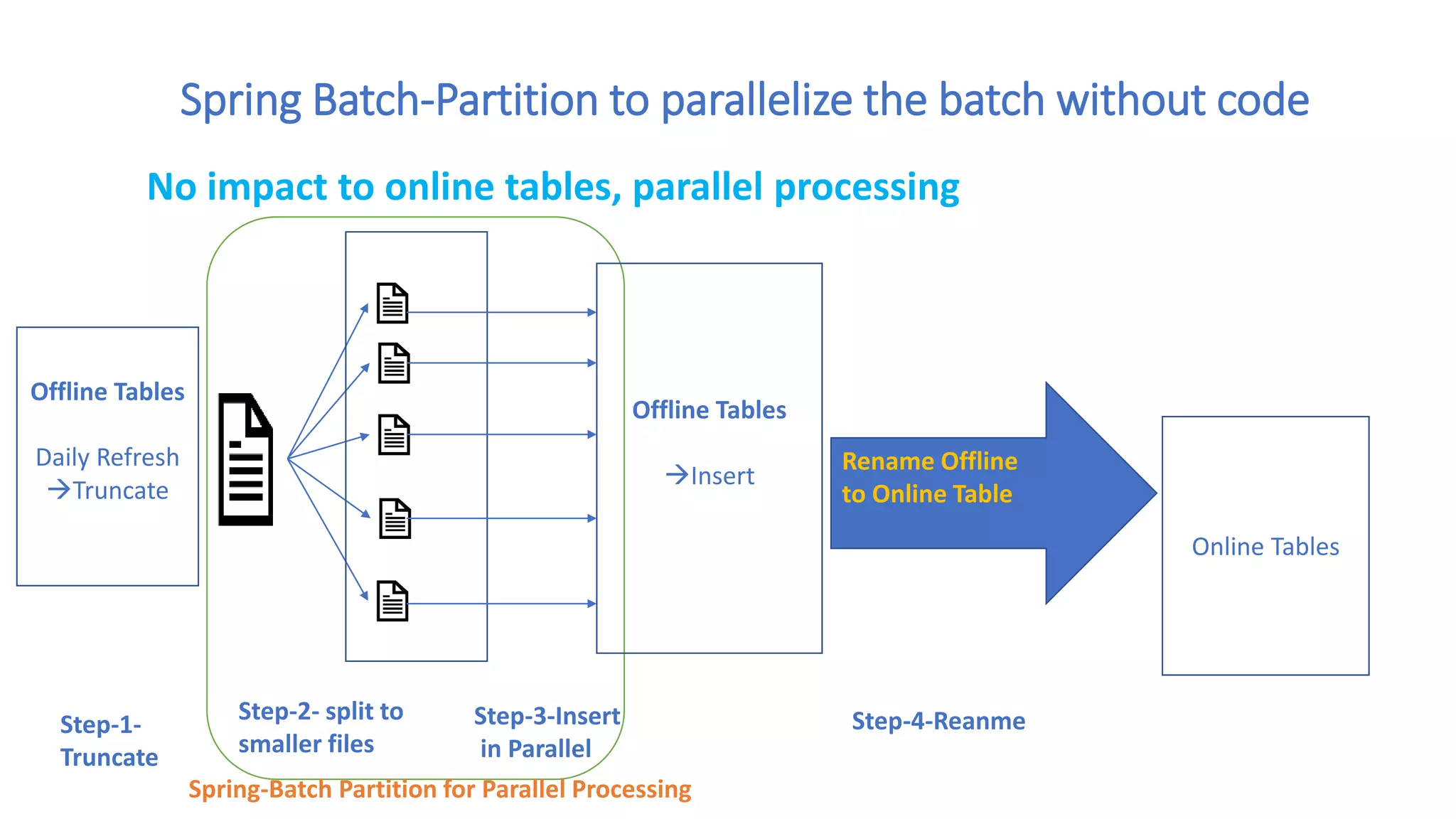
![Schematic of Batch APP
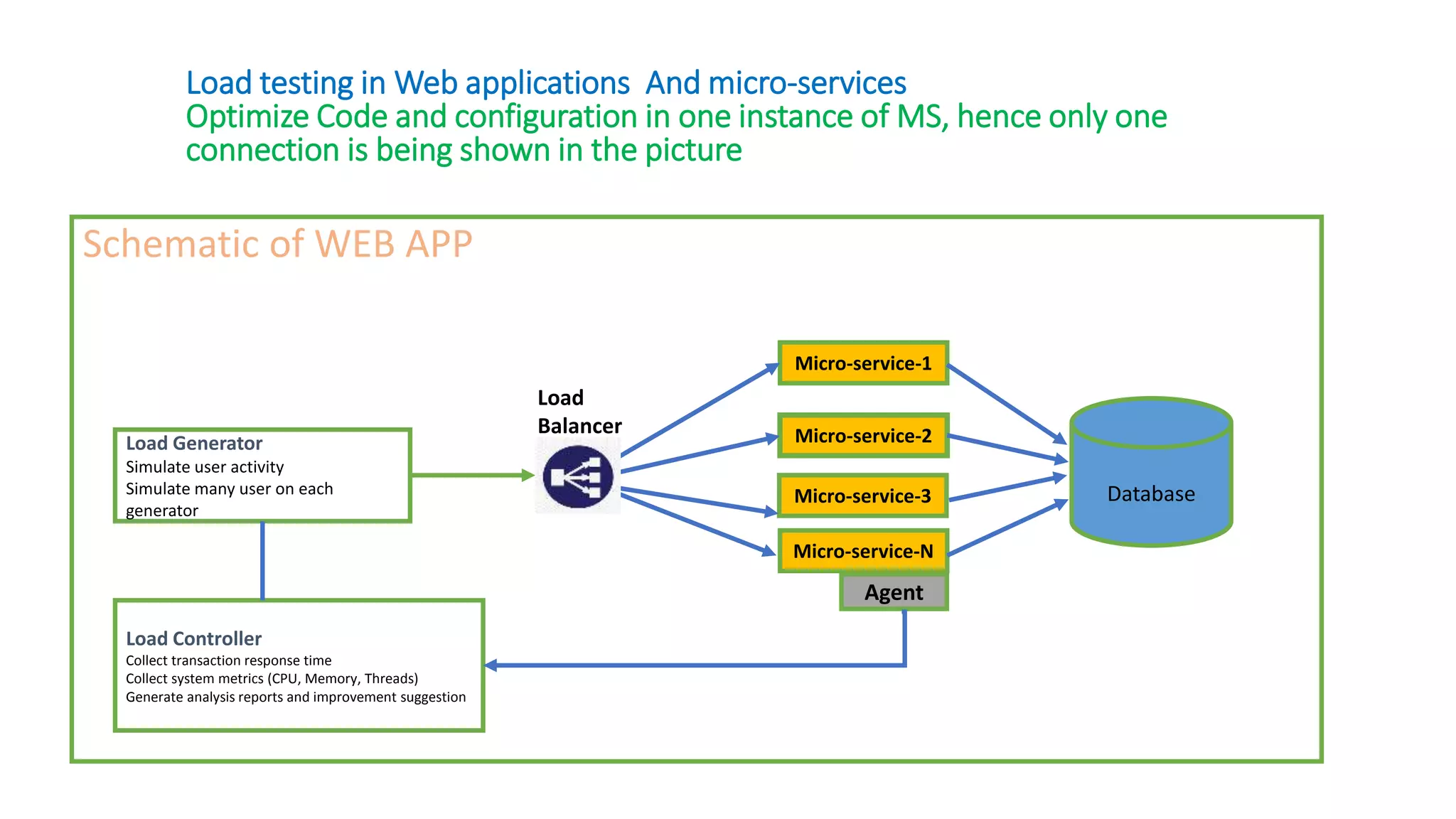
Load testing in Batch applications
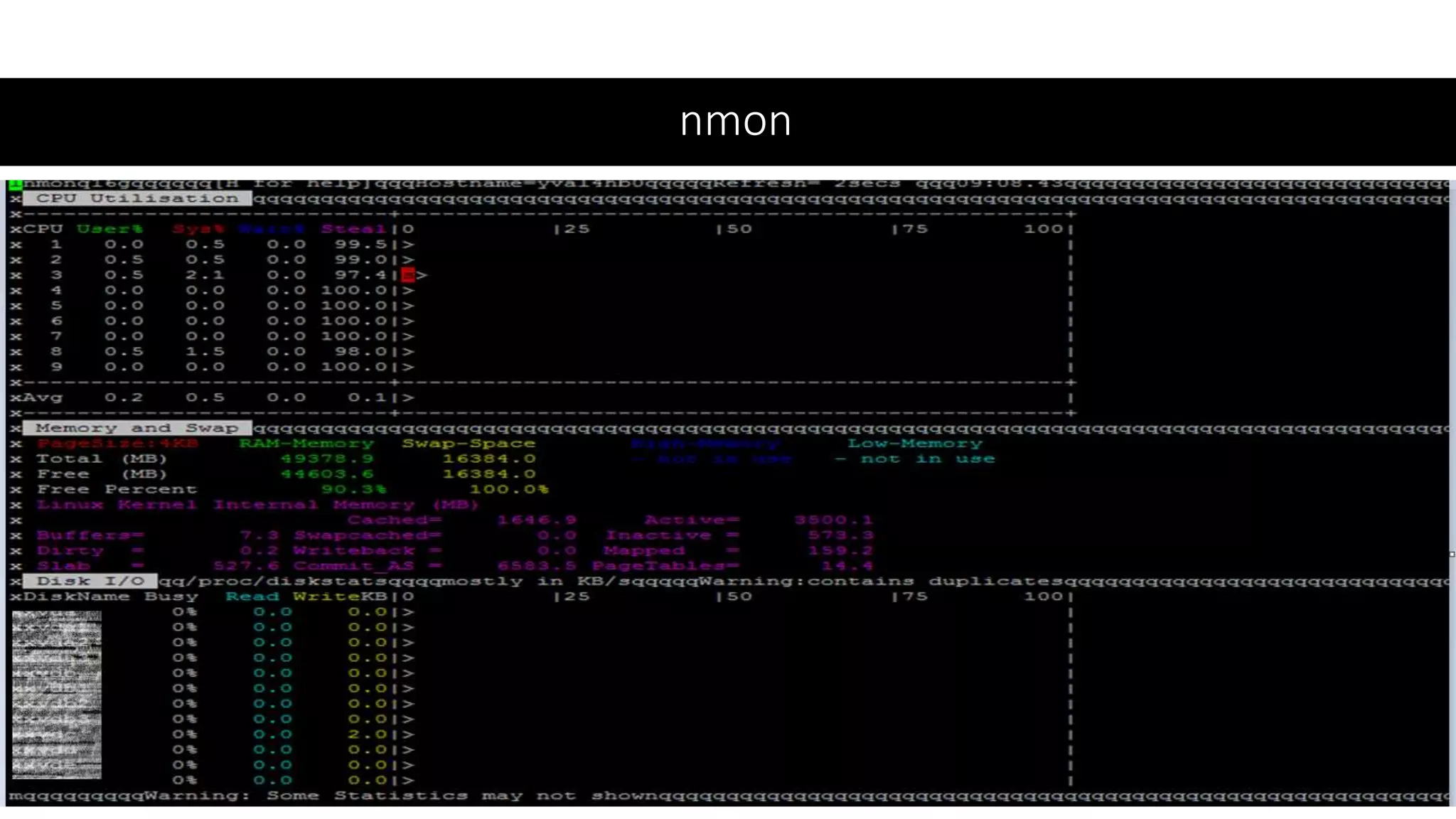
NMON System metric like CPU, Memory, Disk Usage for VM hosting APP and DB
Agent Base Code and Database drill down, Slow code and DB query identification
Batch
Application Database
Load Controller [Introscope, AppDynamics,
DynaTrace]
Collect transaction response time
Collect system metrics (CPU, Memory, Threads)
Generate analysis reports and improvement suggestion
Agent
Test File
System Metric
Collector
NMON
VM running Batch App VM hosting Database
System Metric
Collector
NMON](https://image.slidesharecdn.com/performanceeng-prakash-191013164501/75/Performance-eng-prakash-sahu-12-2048.jpg)