Downloaded 134 times




























![Coherence Server Lifecycle WLS MBean’s Node Manager Client Node Manager WebLogic Admin Server WLS Console WLST, JMX Domain Directory - Coherence Cluster - tangosol-coherence-override.xml - Coherence Server Coherence Server(s) Machine A Node Manager Coherence Server(s) Machine B [Lifecycle, HA] Pack / Unpack](https://image.slidesharecdn.com/2-session2-coherenceandjpa-110413110645-phpapp02/75/JPA-and-Coherence-with-TopLink-Grid-61-2048.jpg)


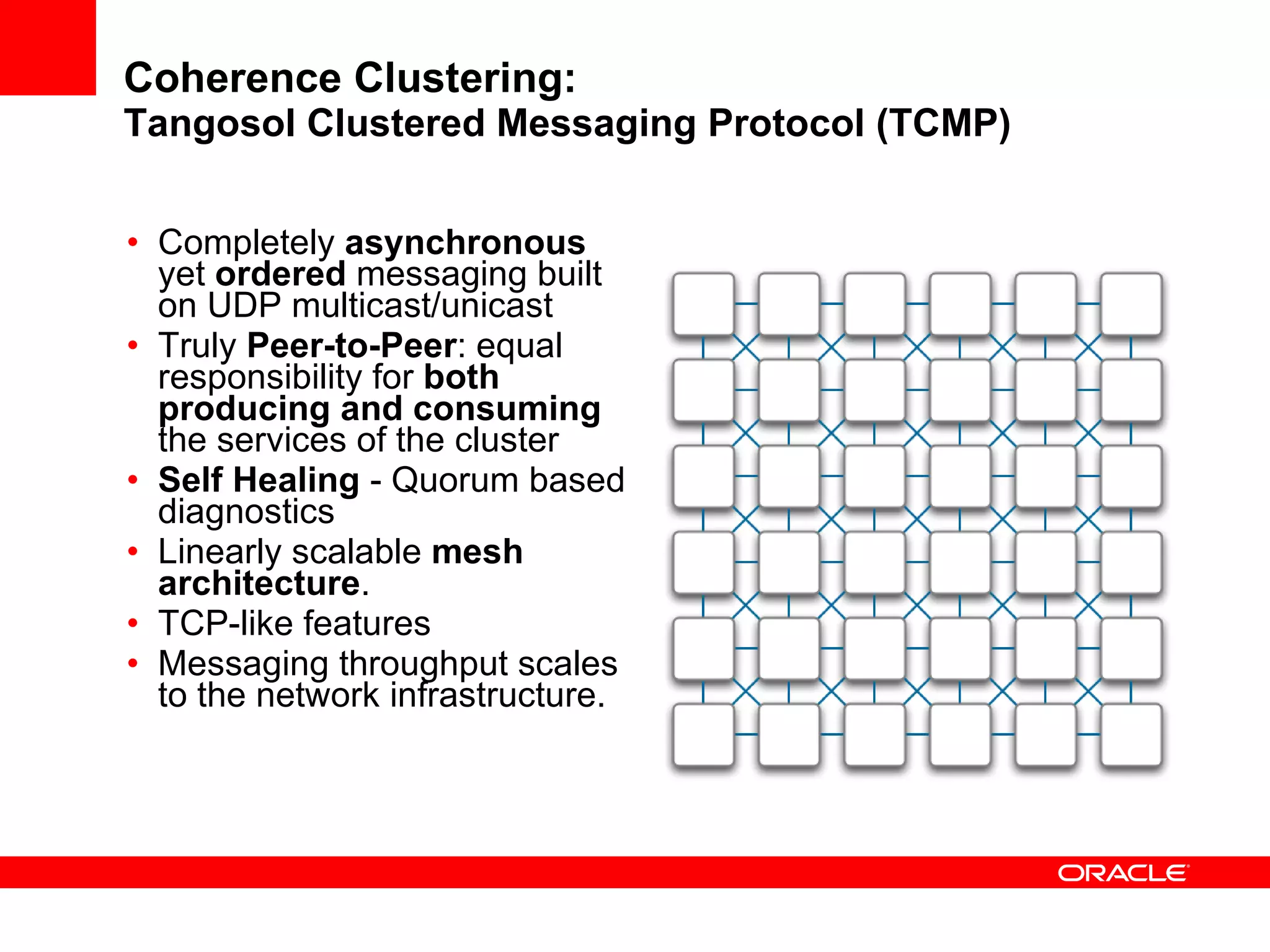
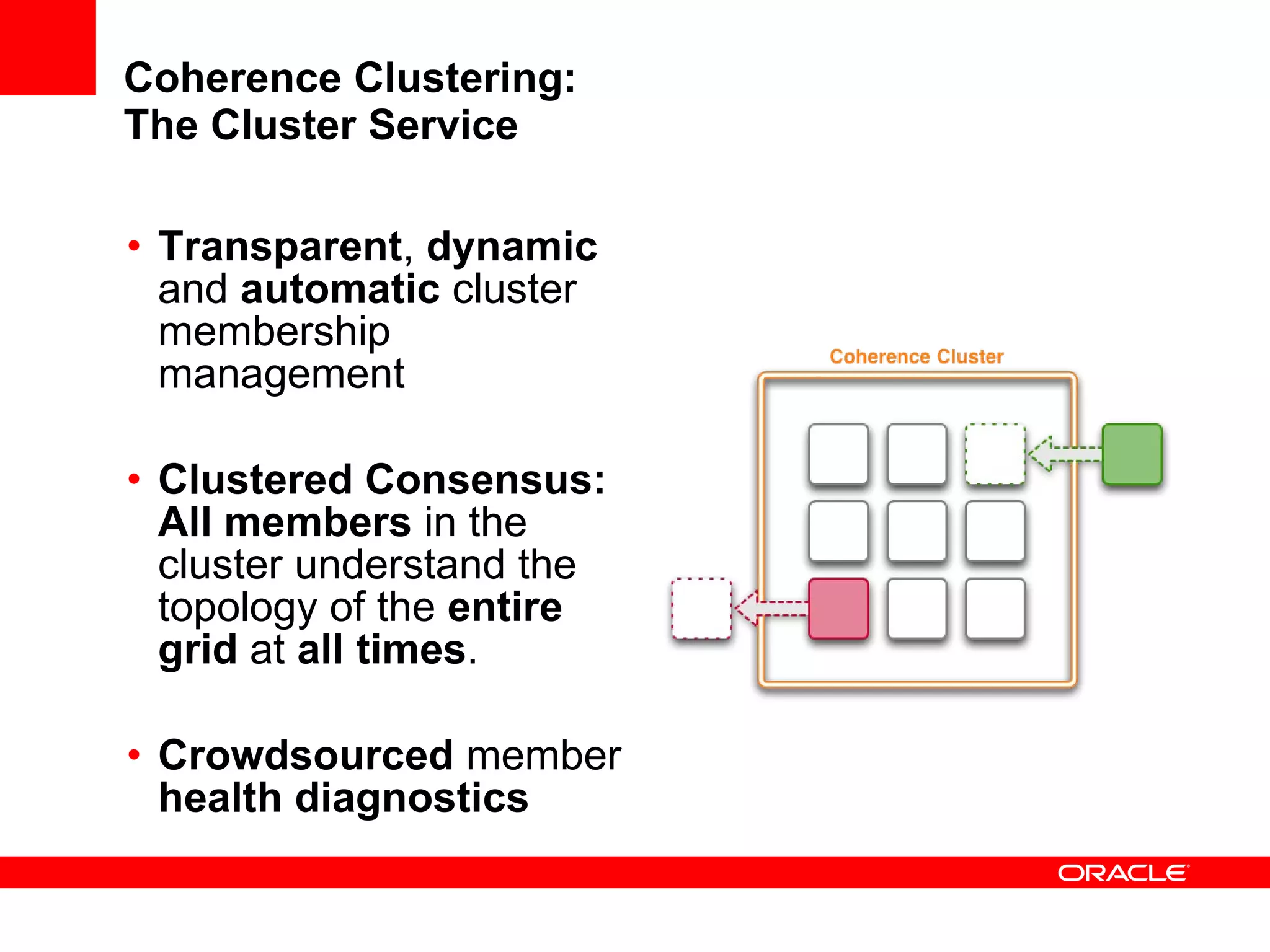
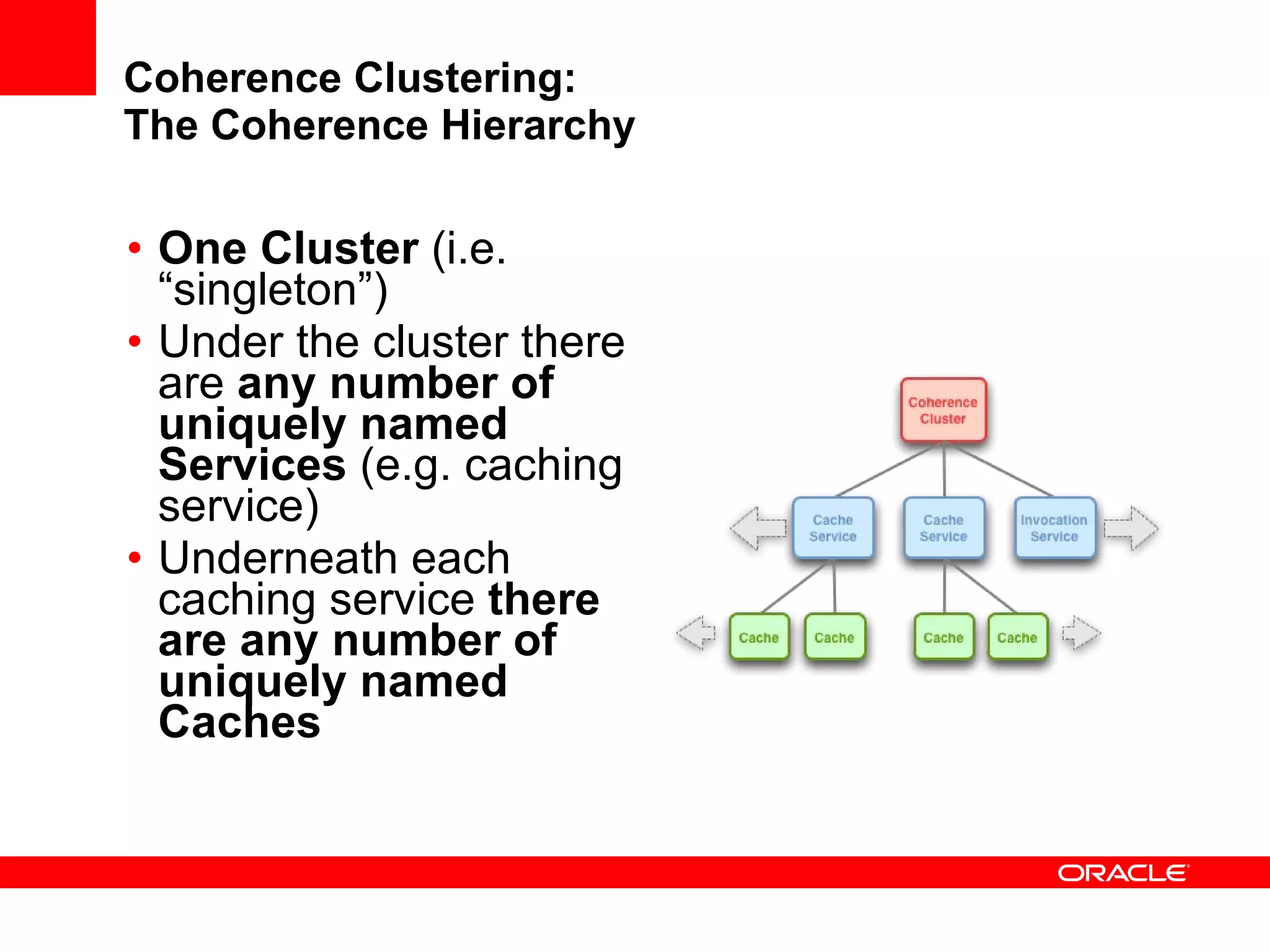
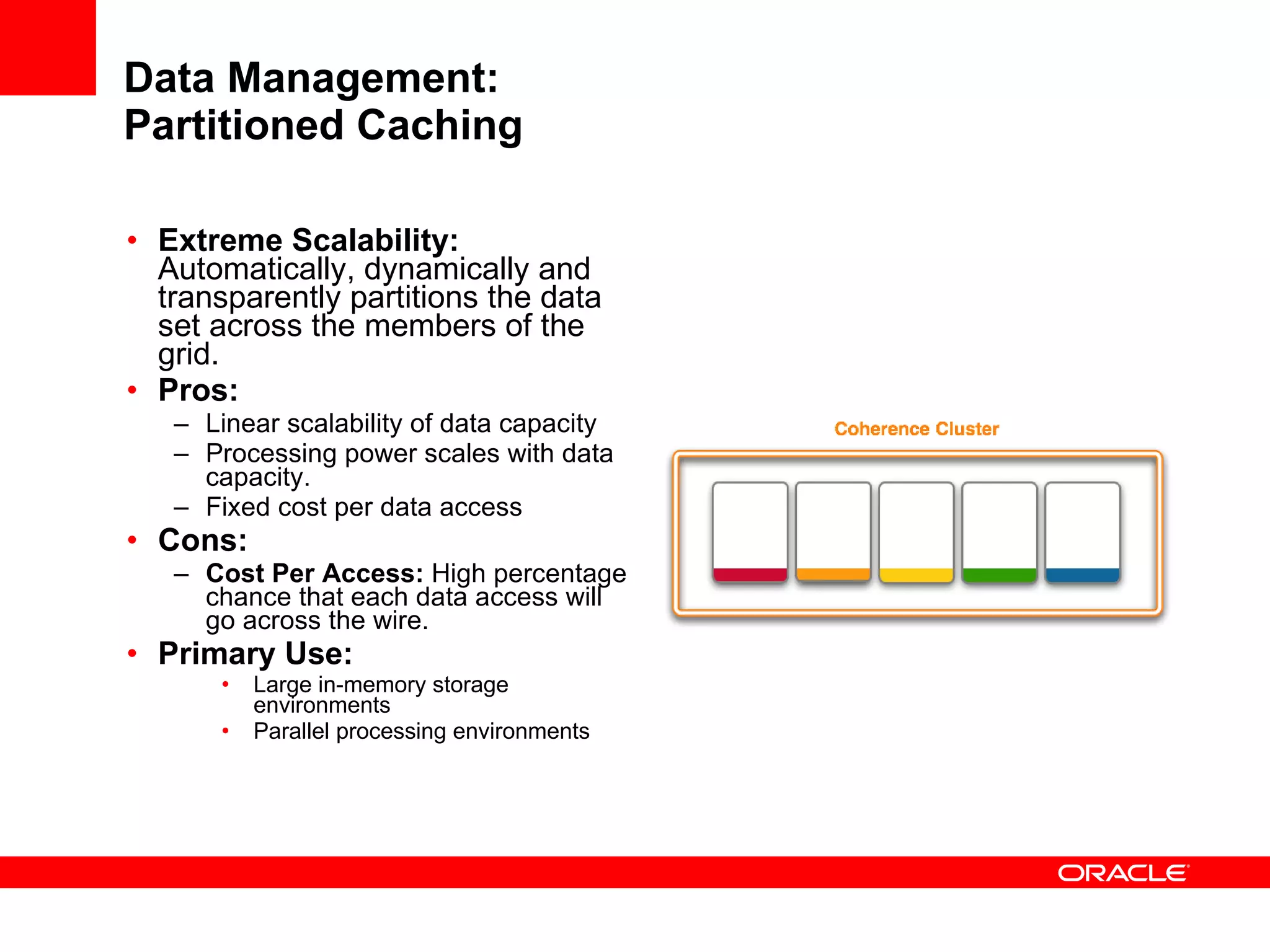
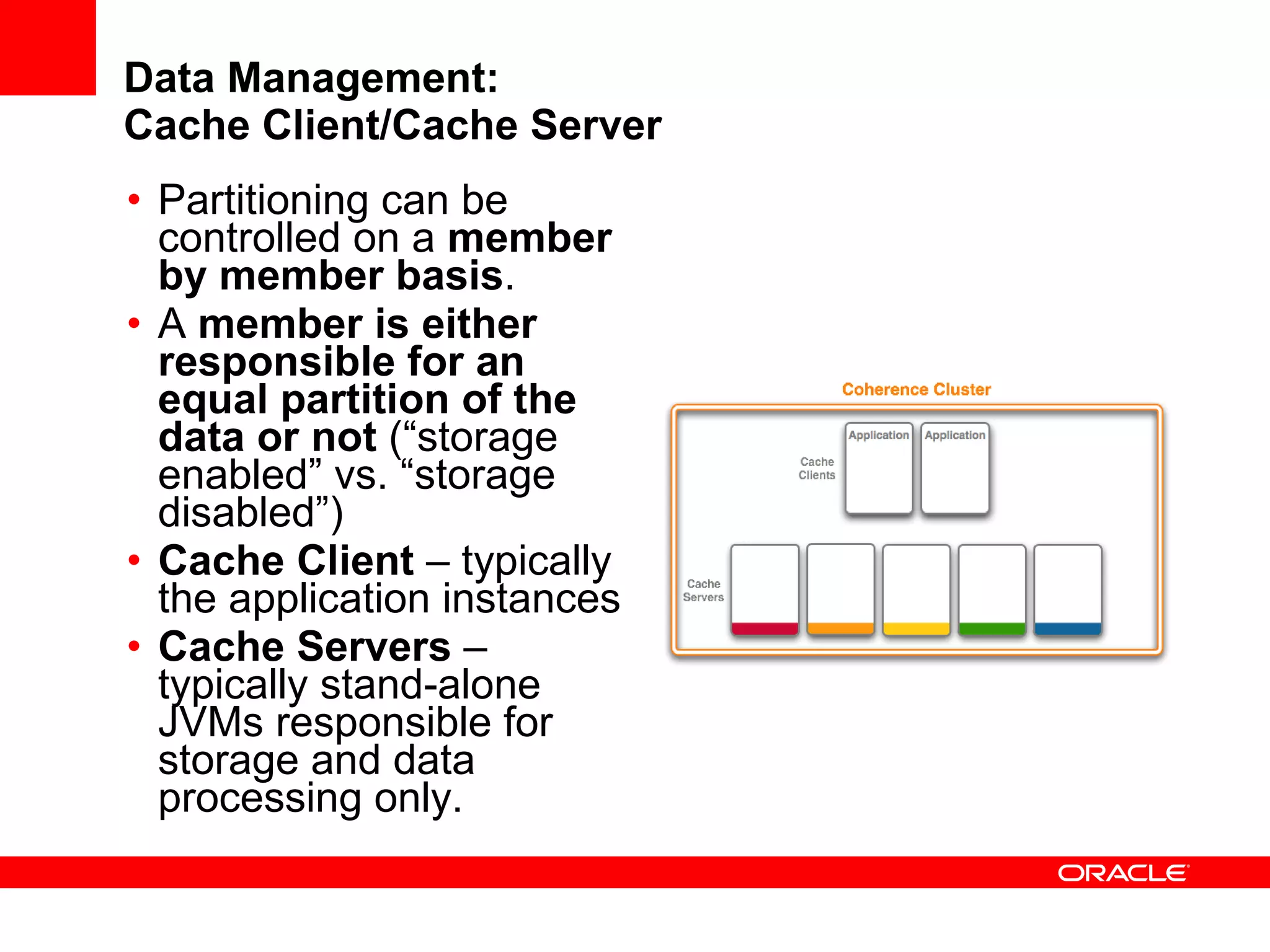
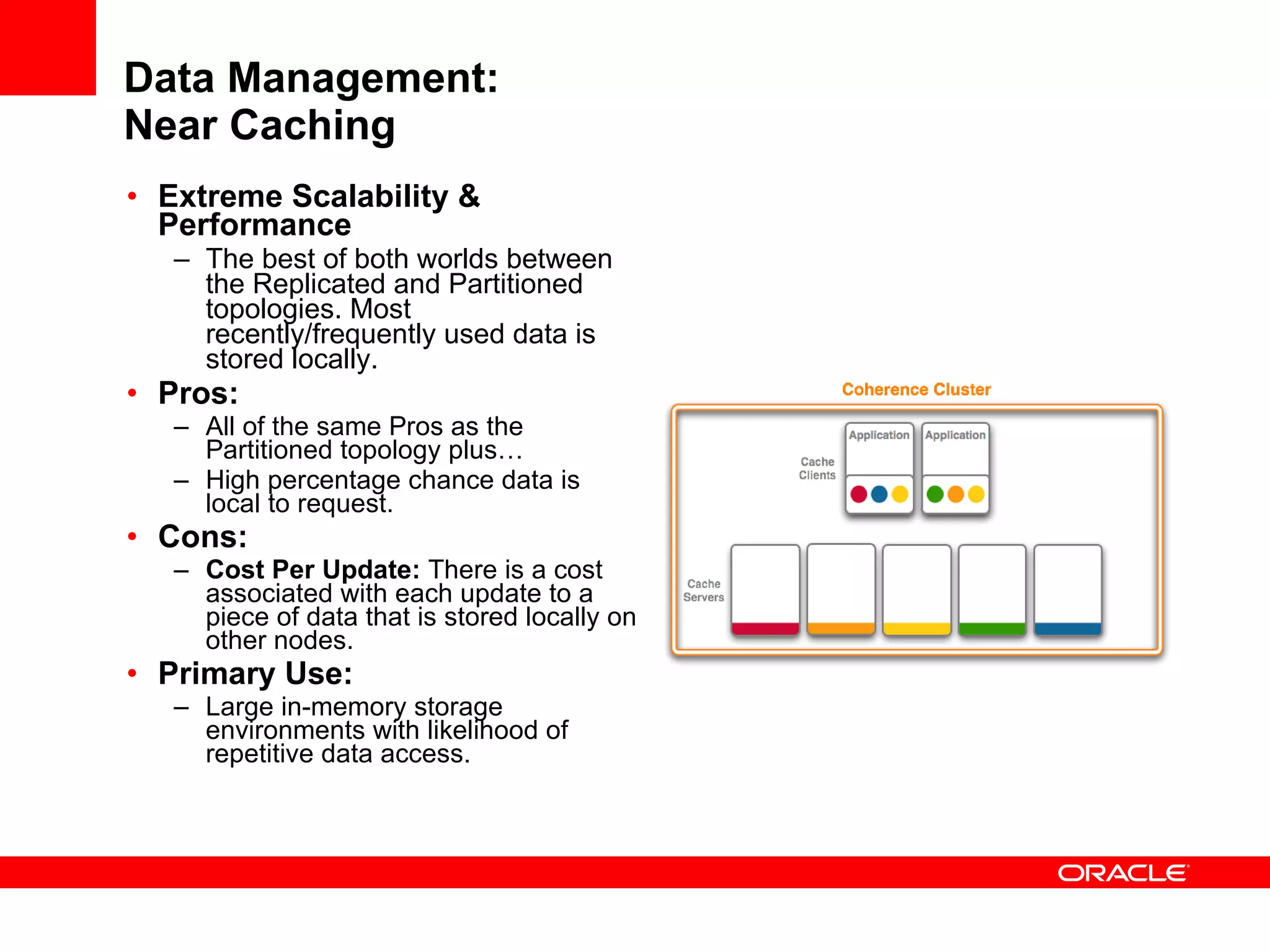
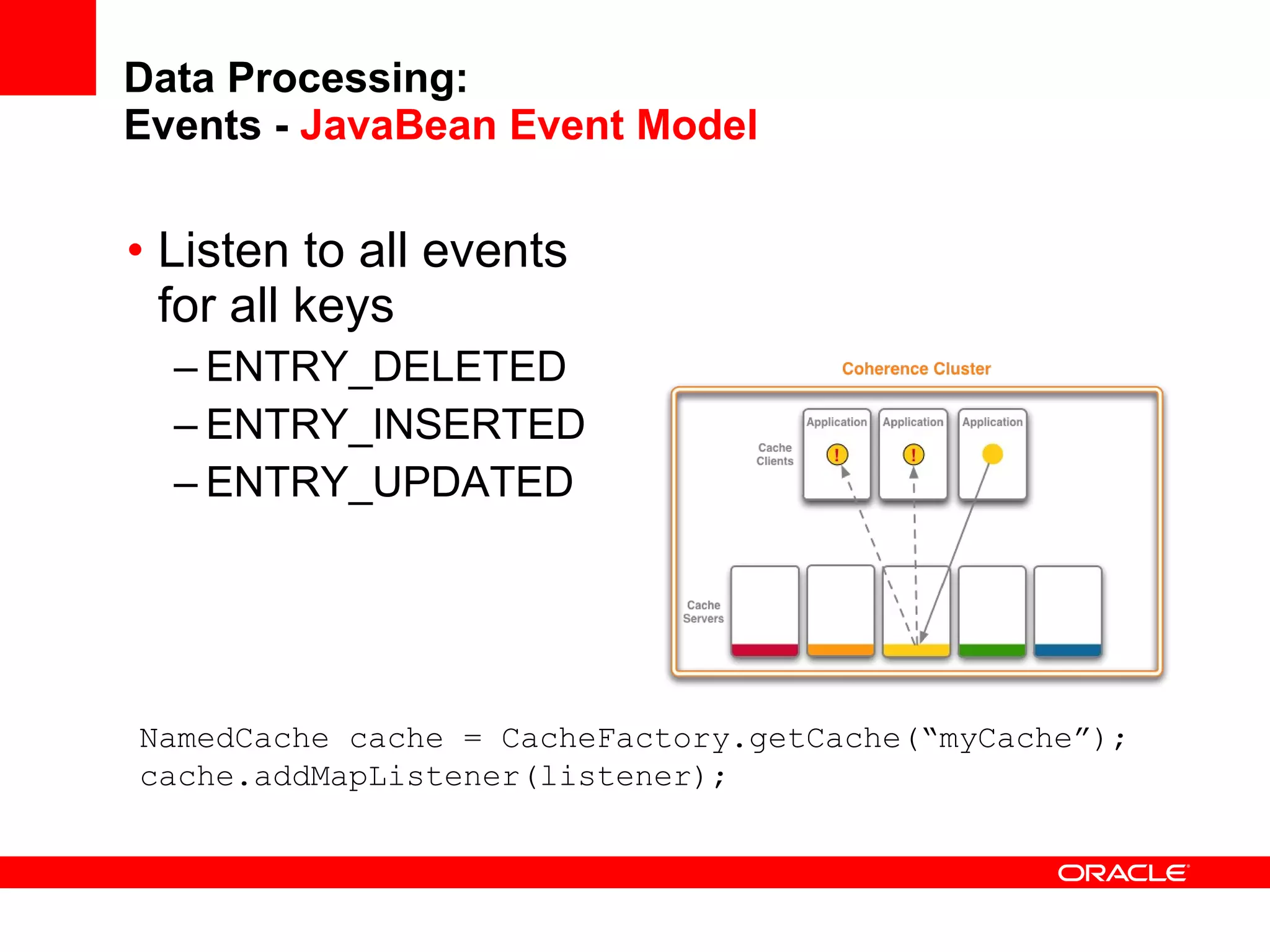
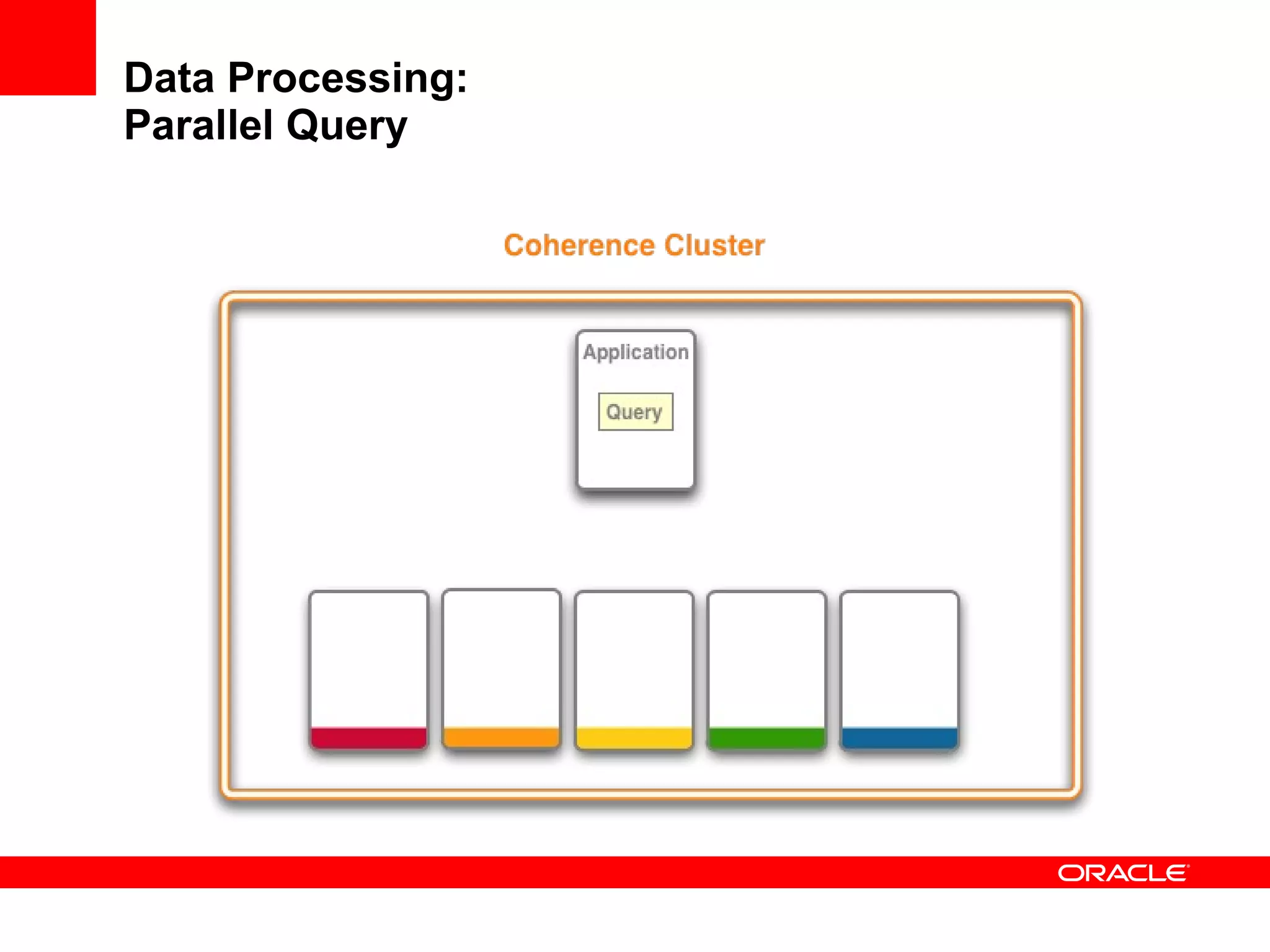
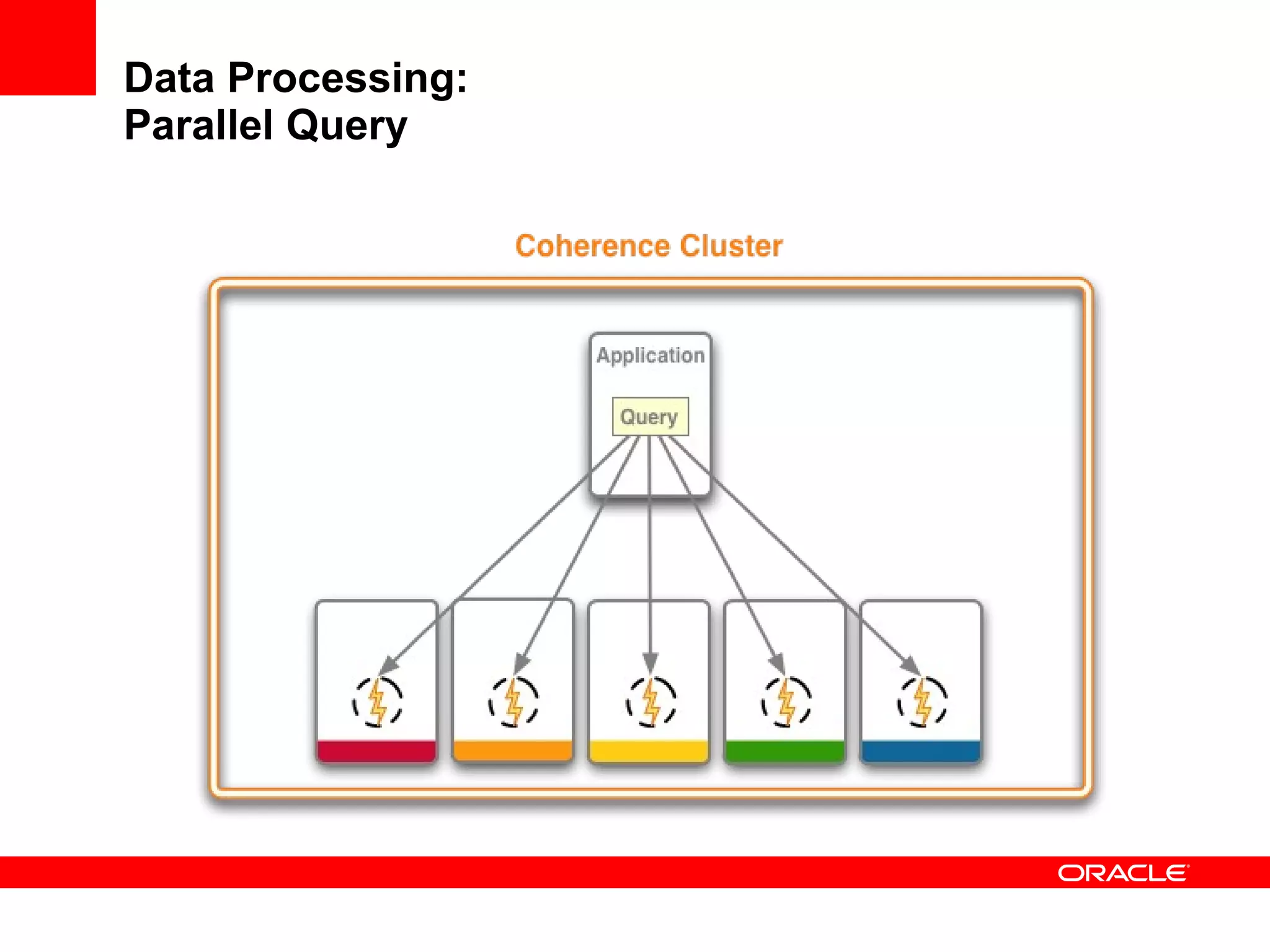
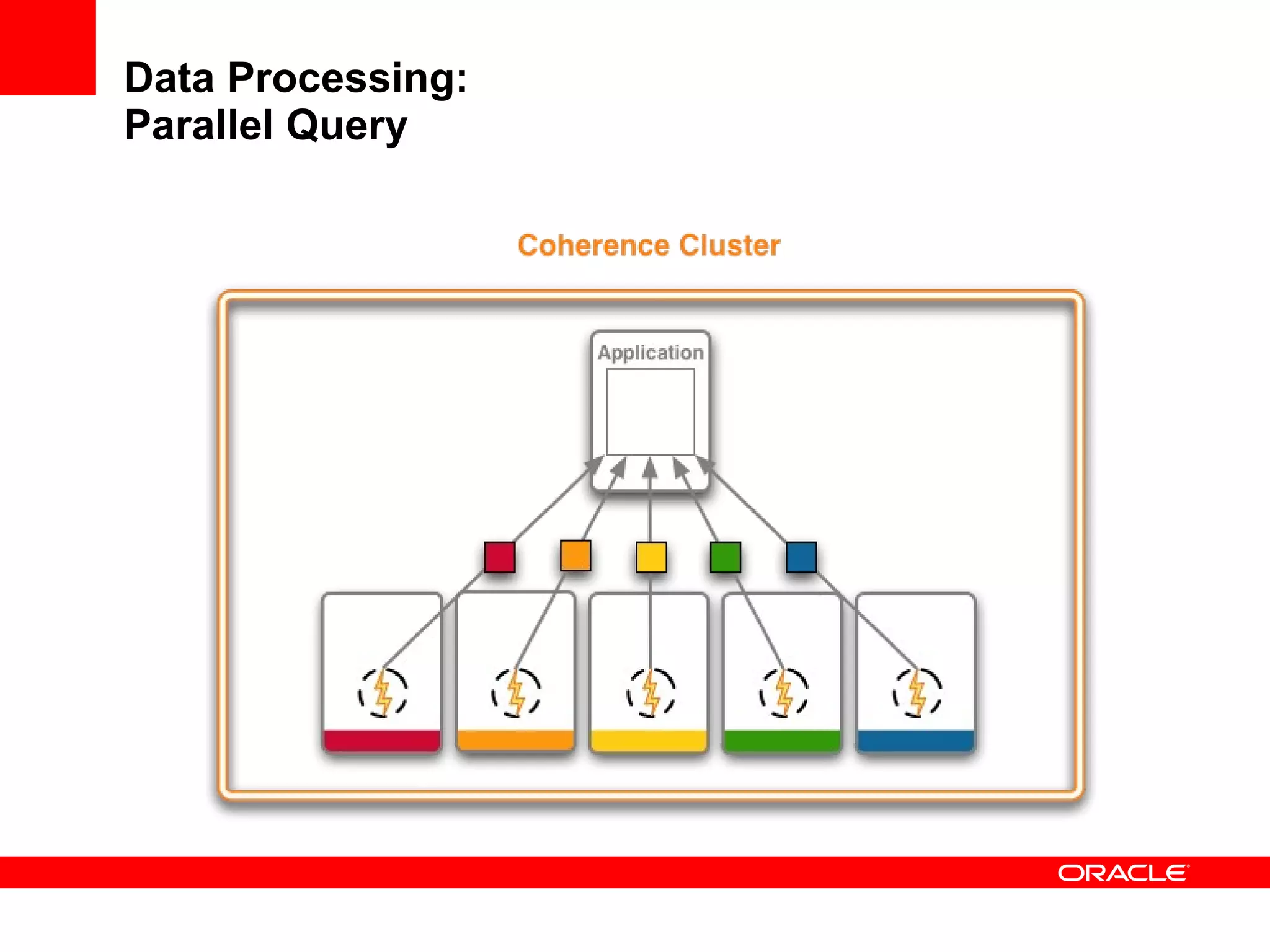
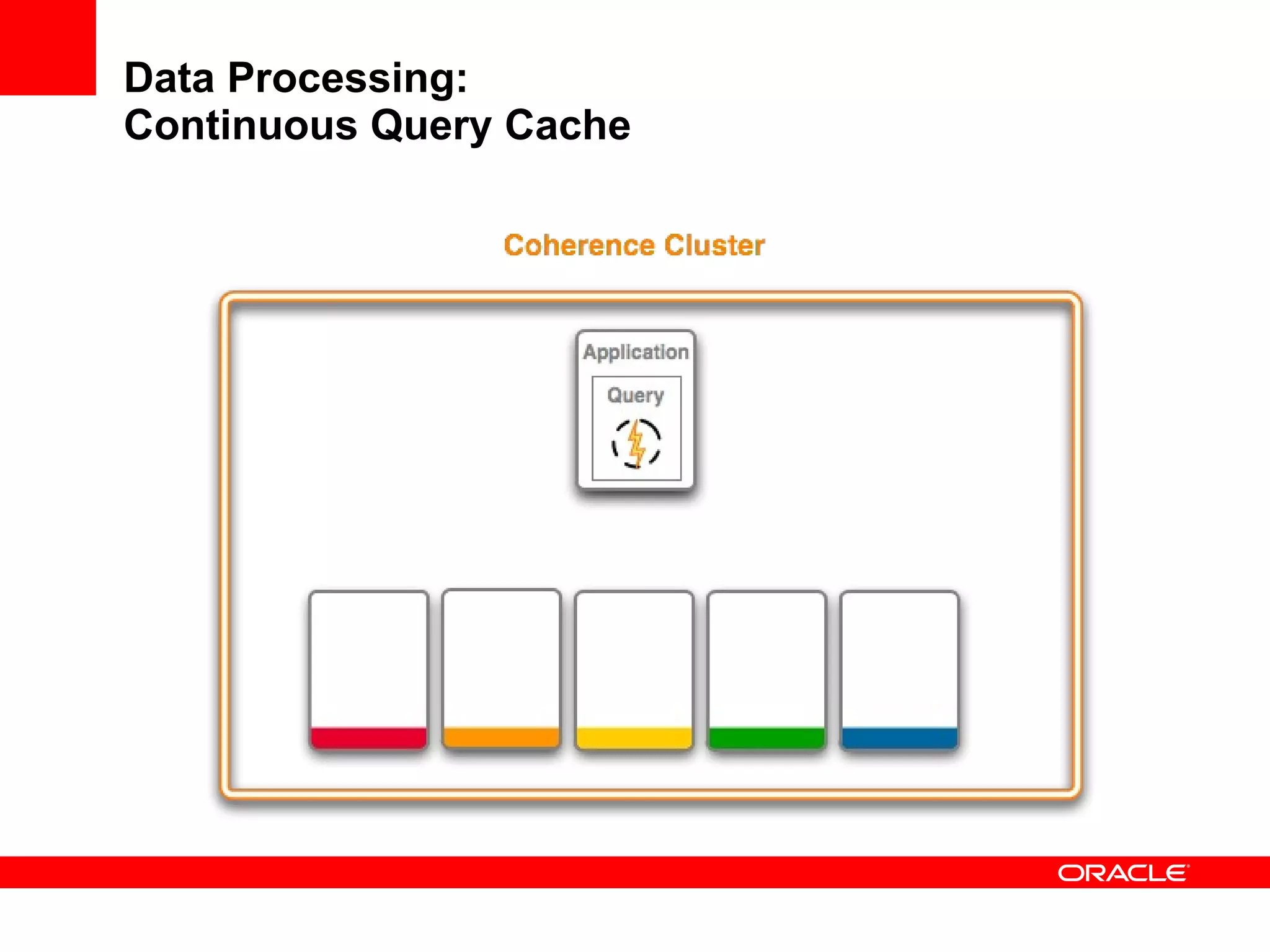
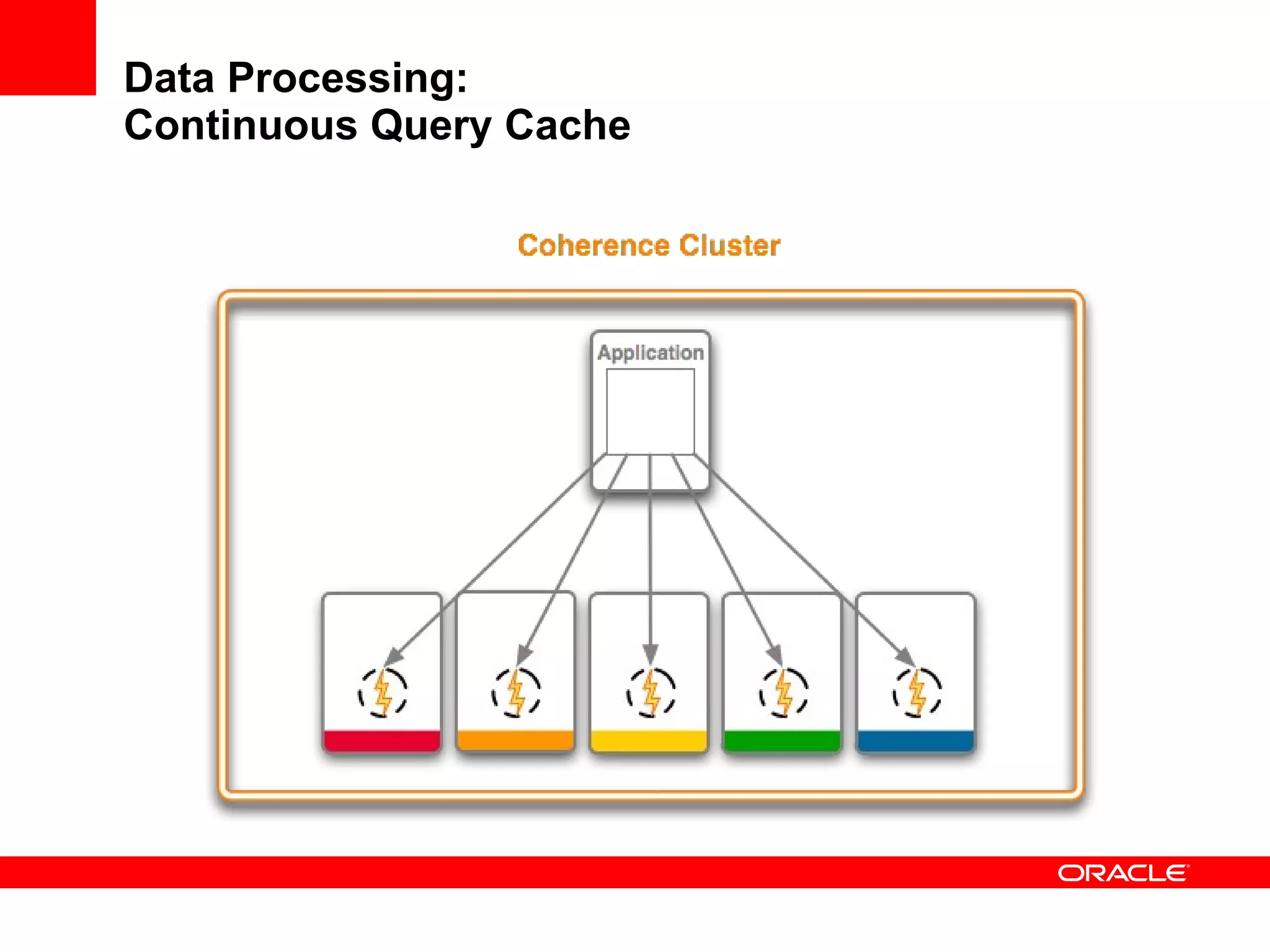
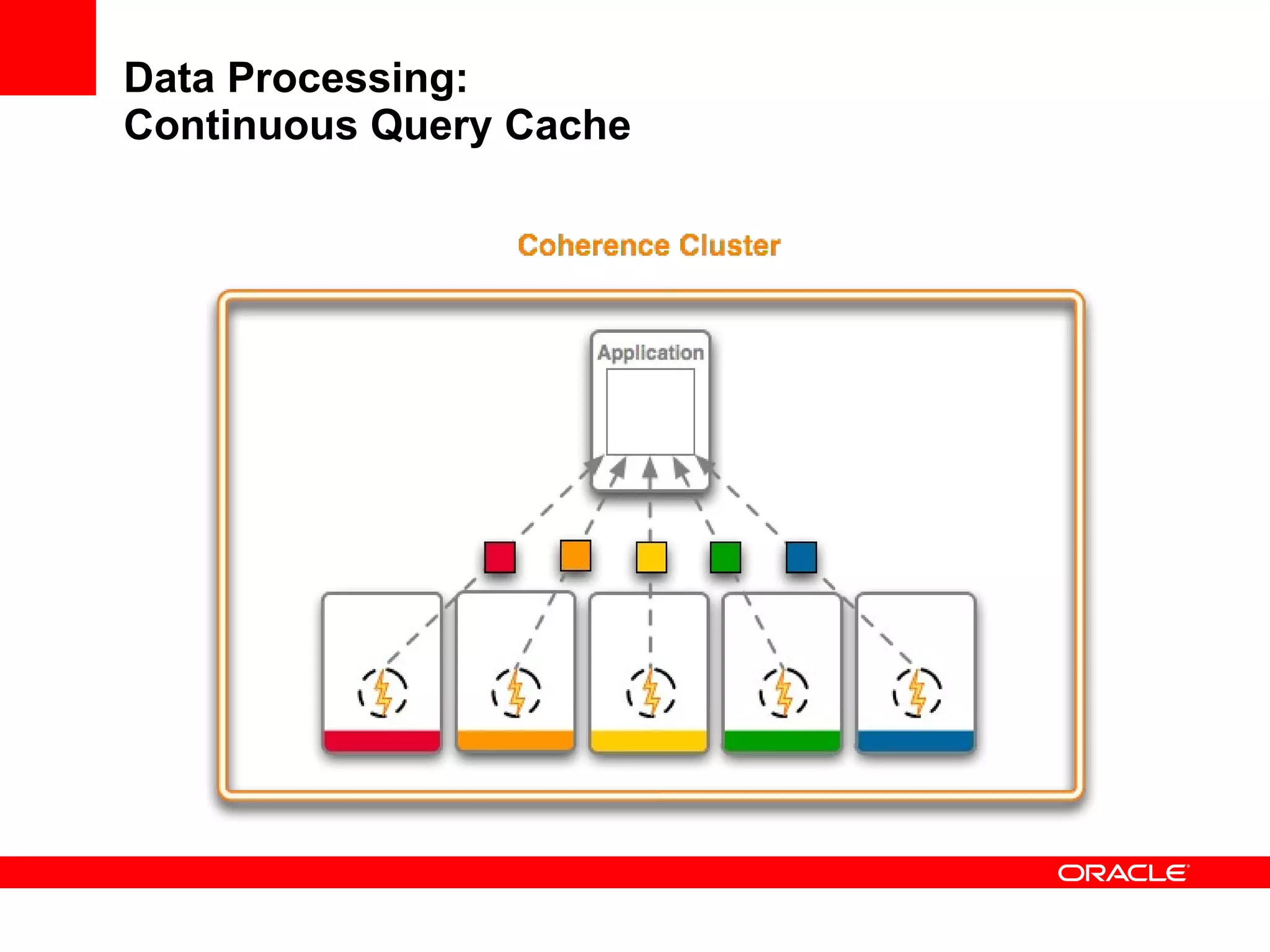
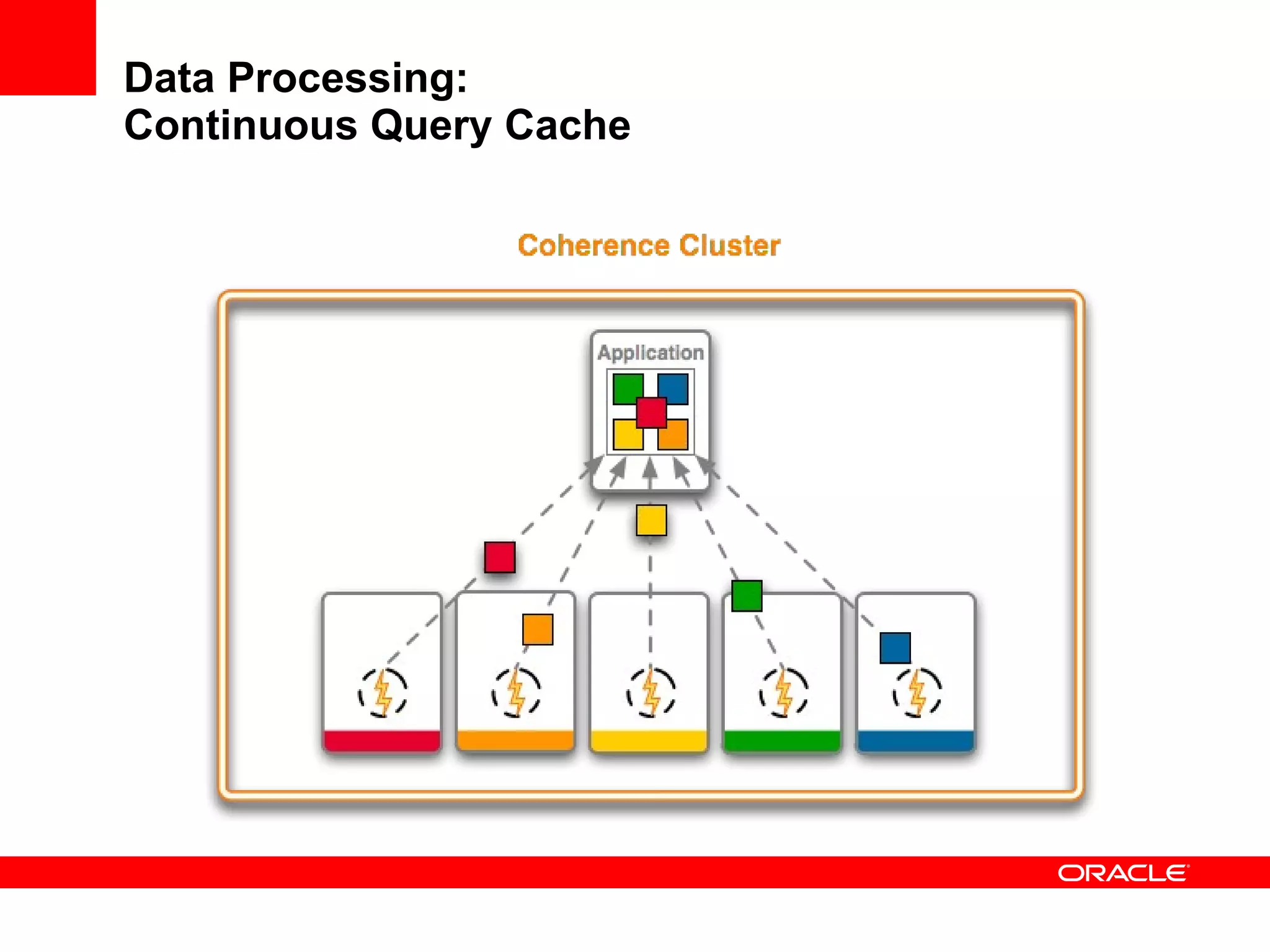
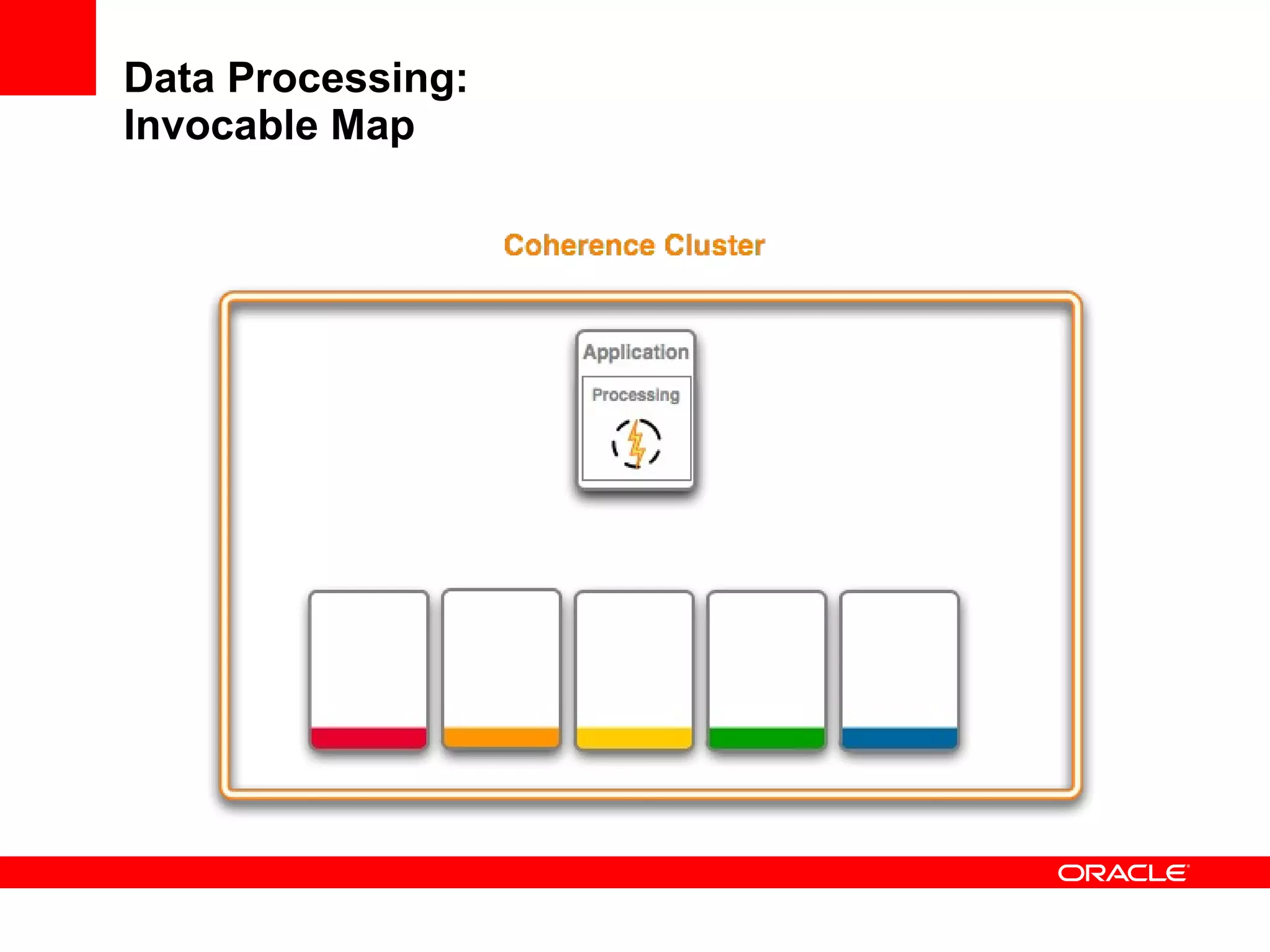
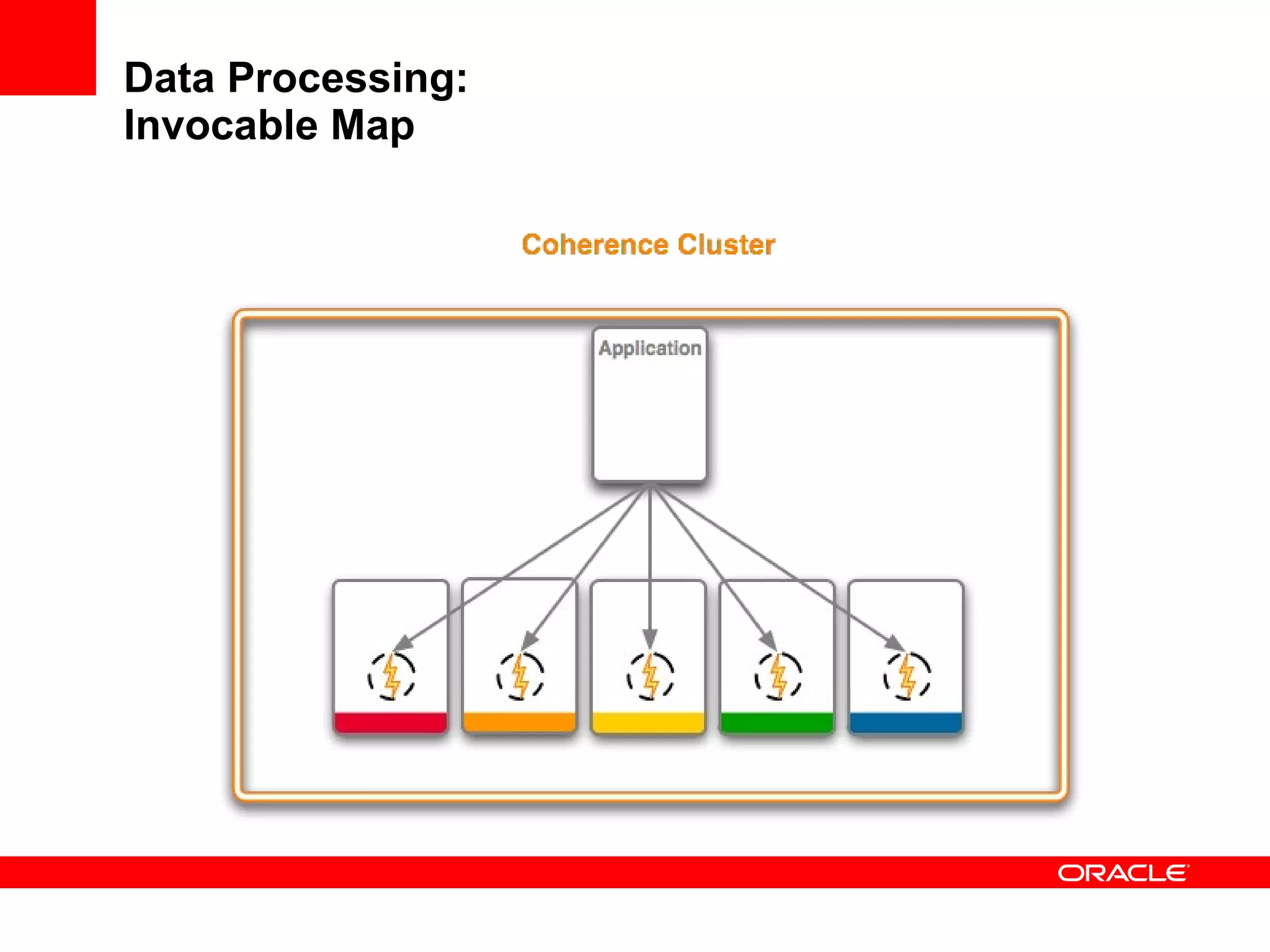
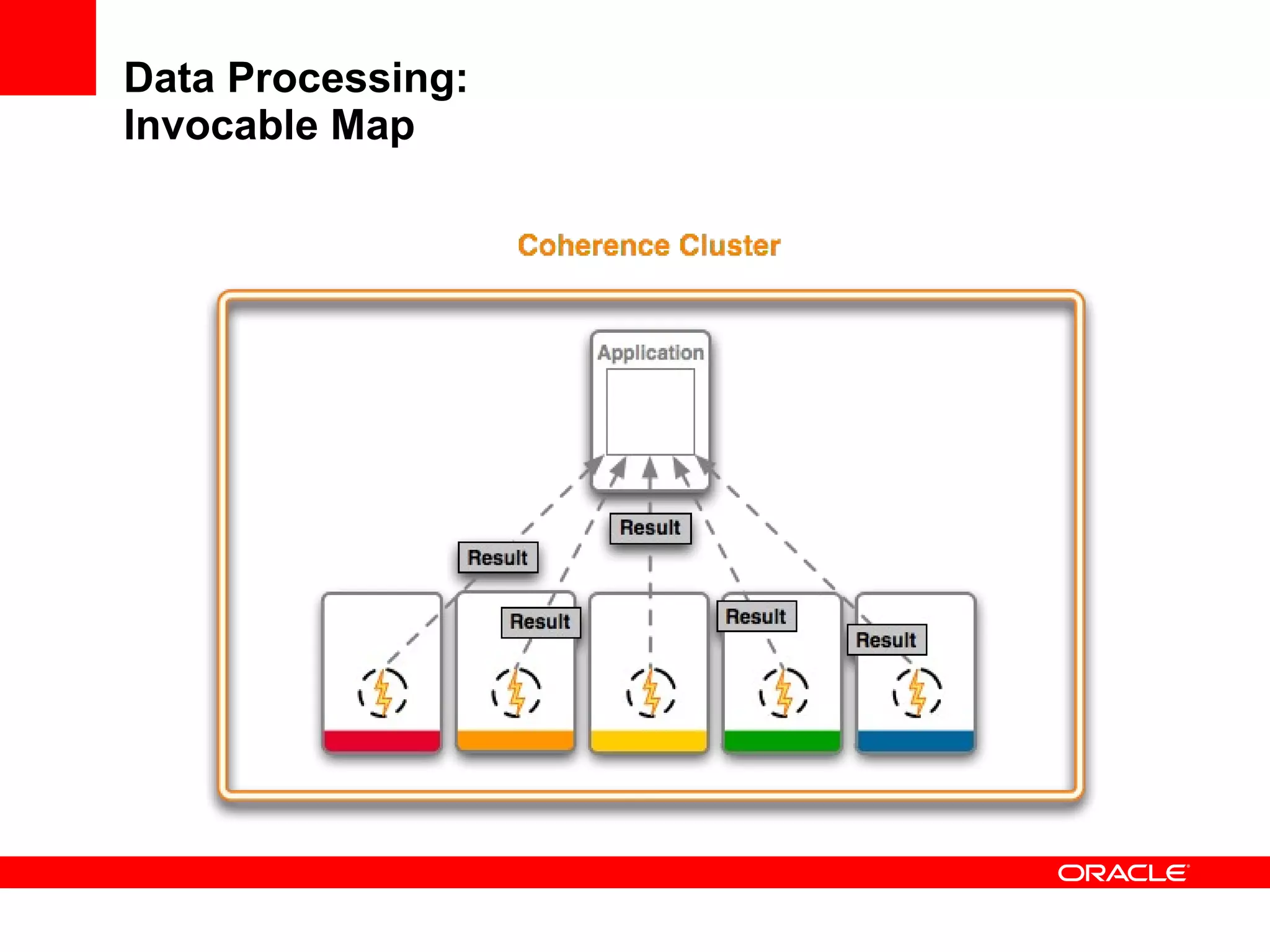
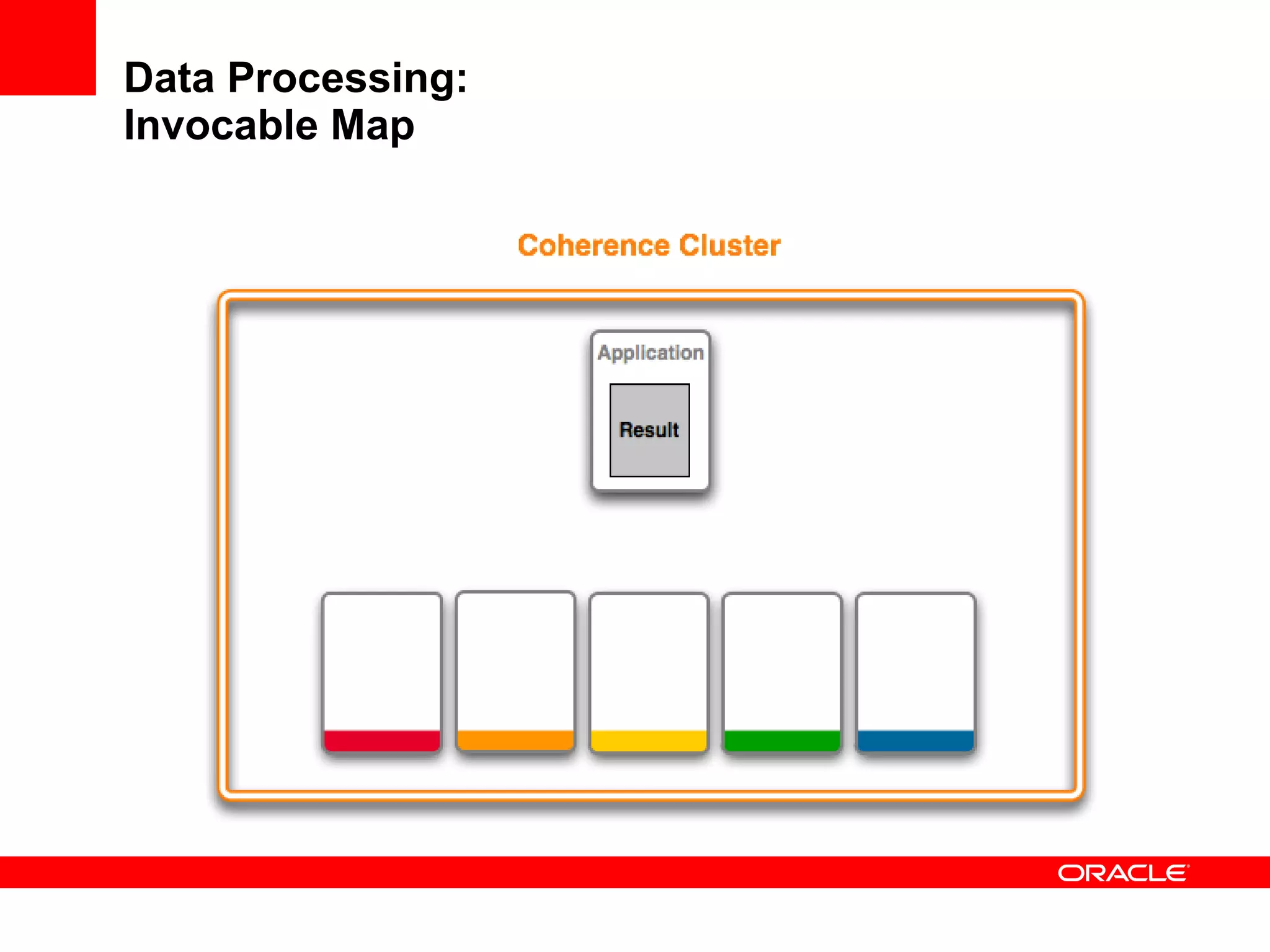
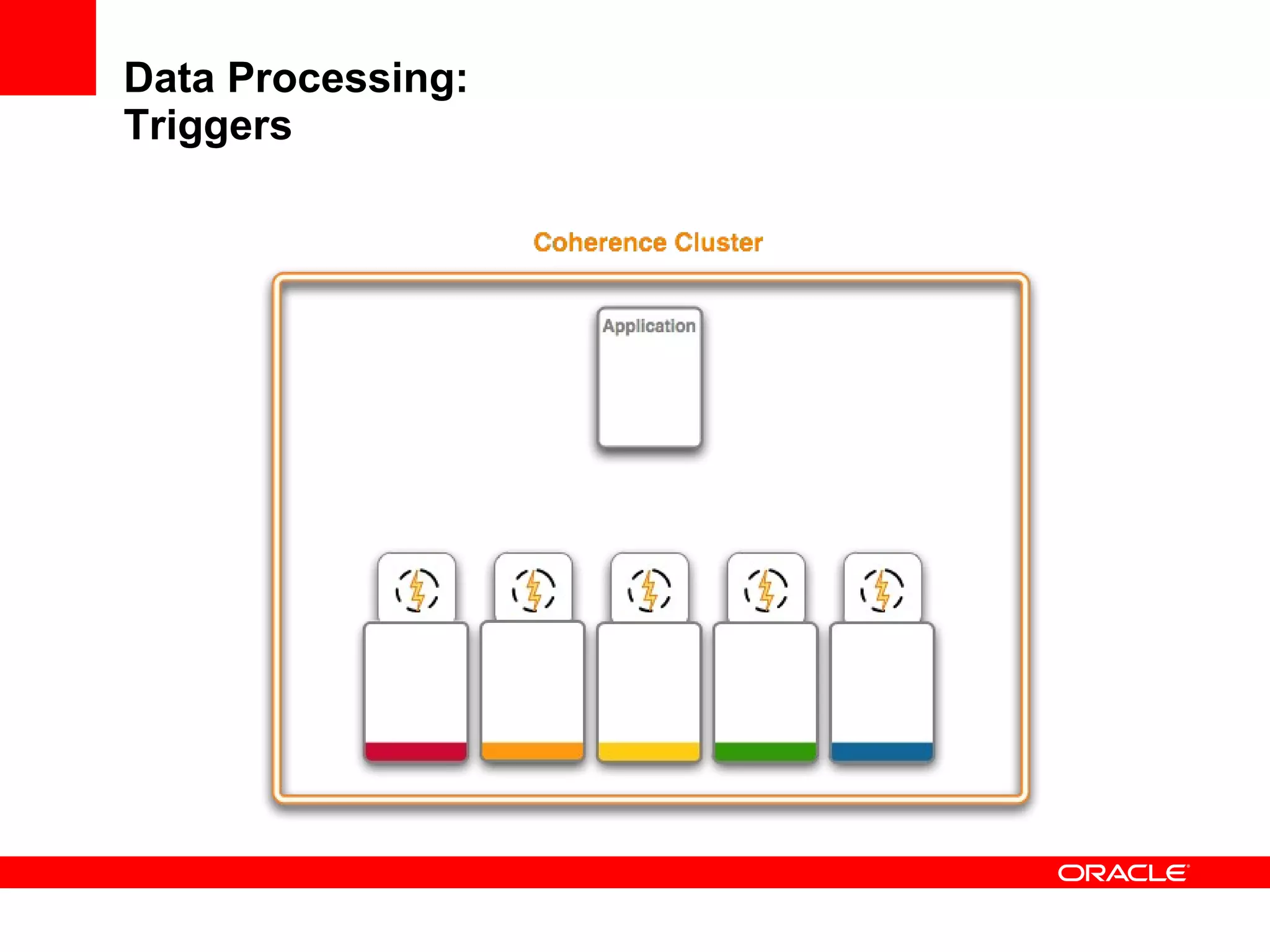
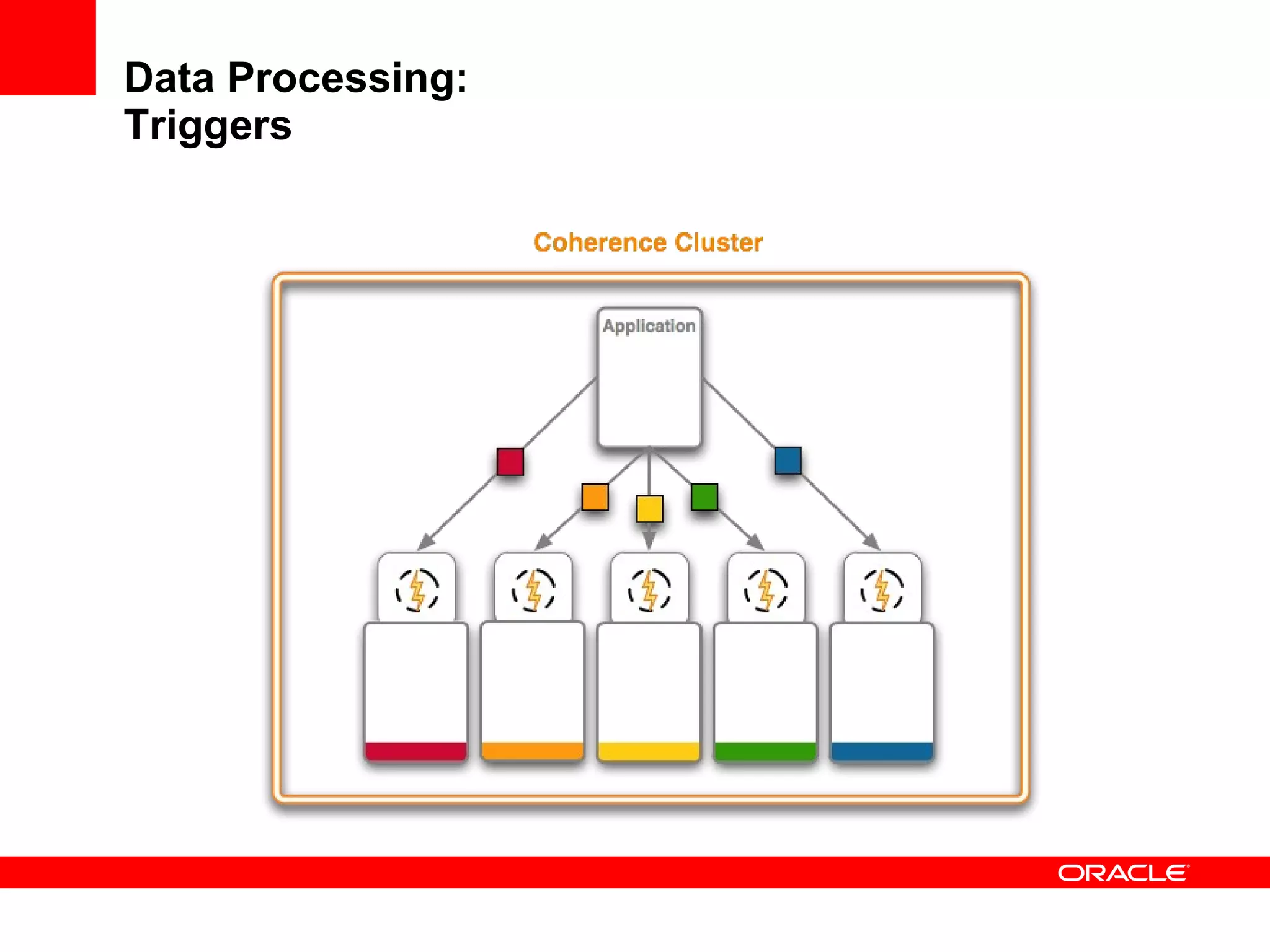
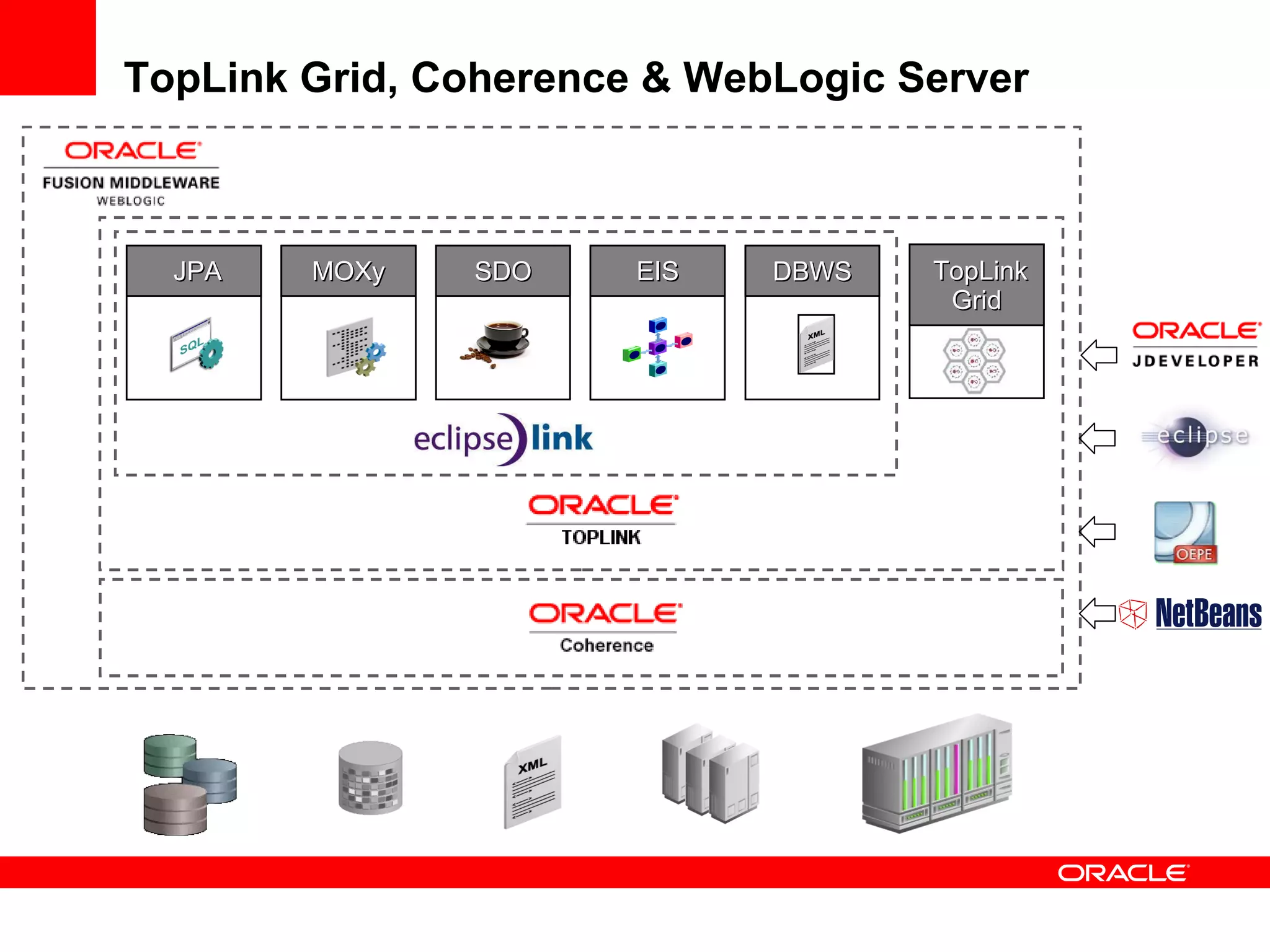
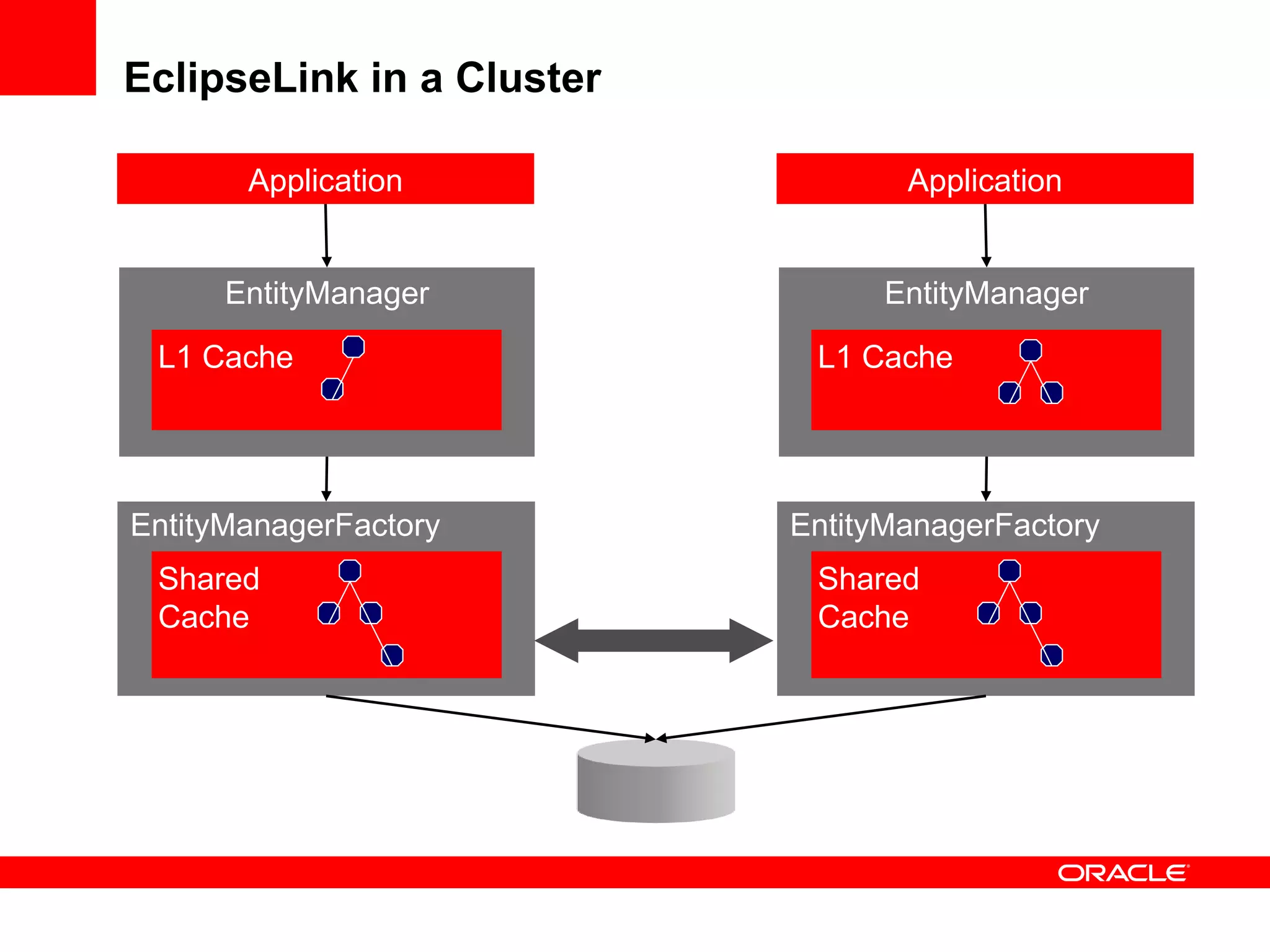
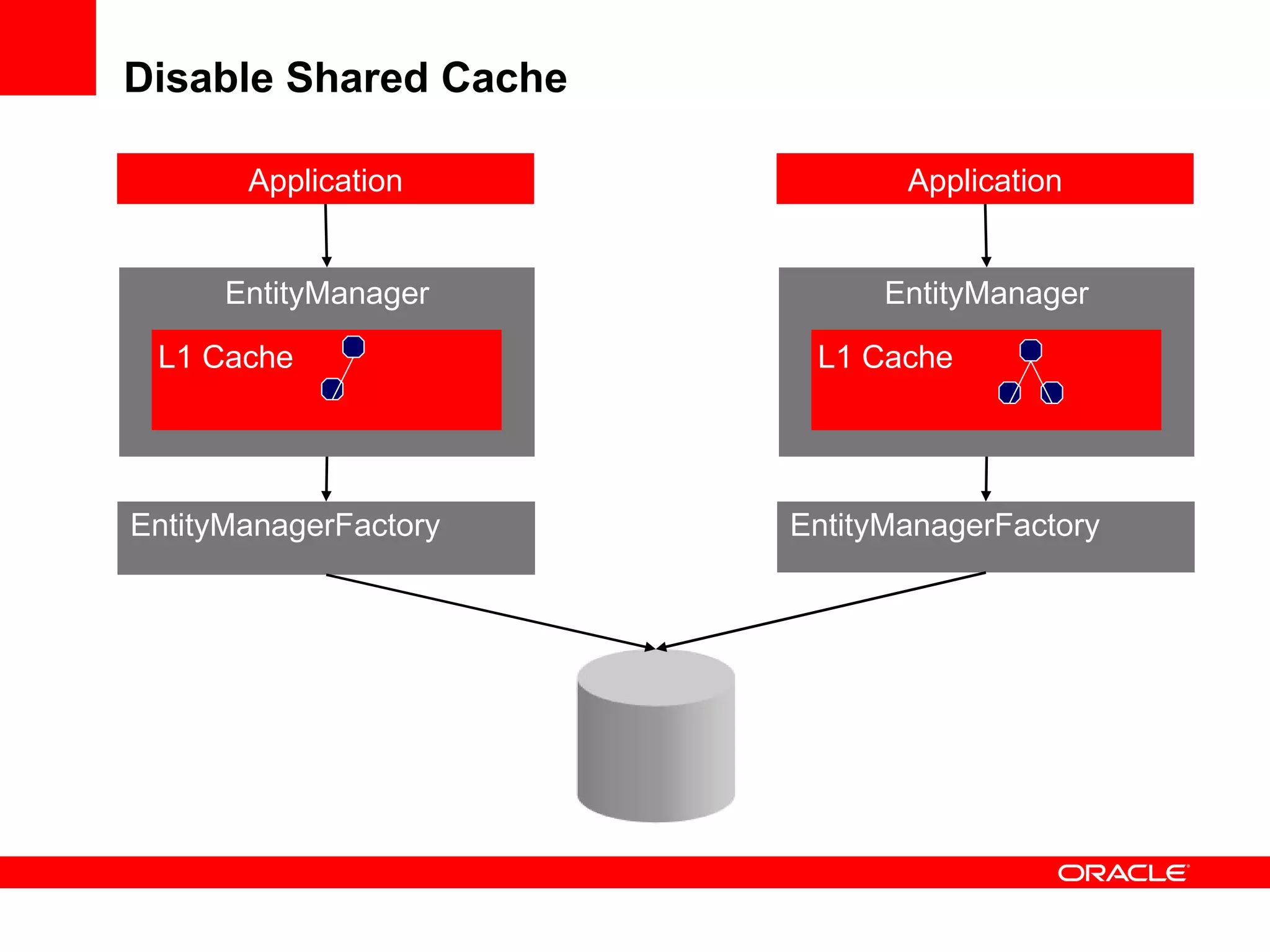
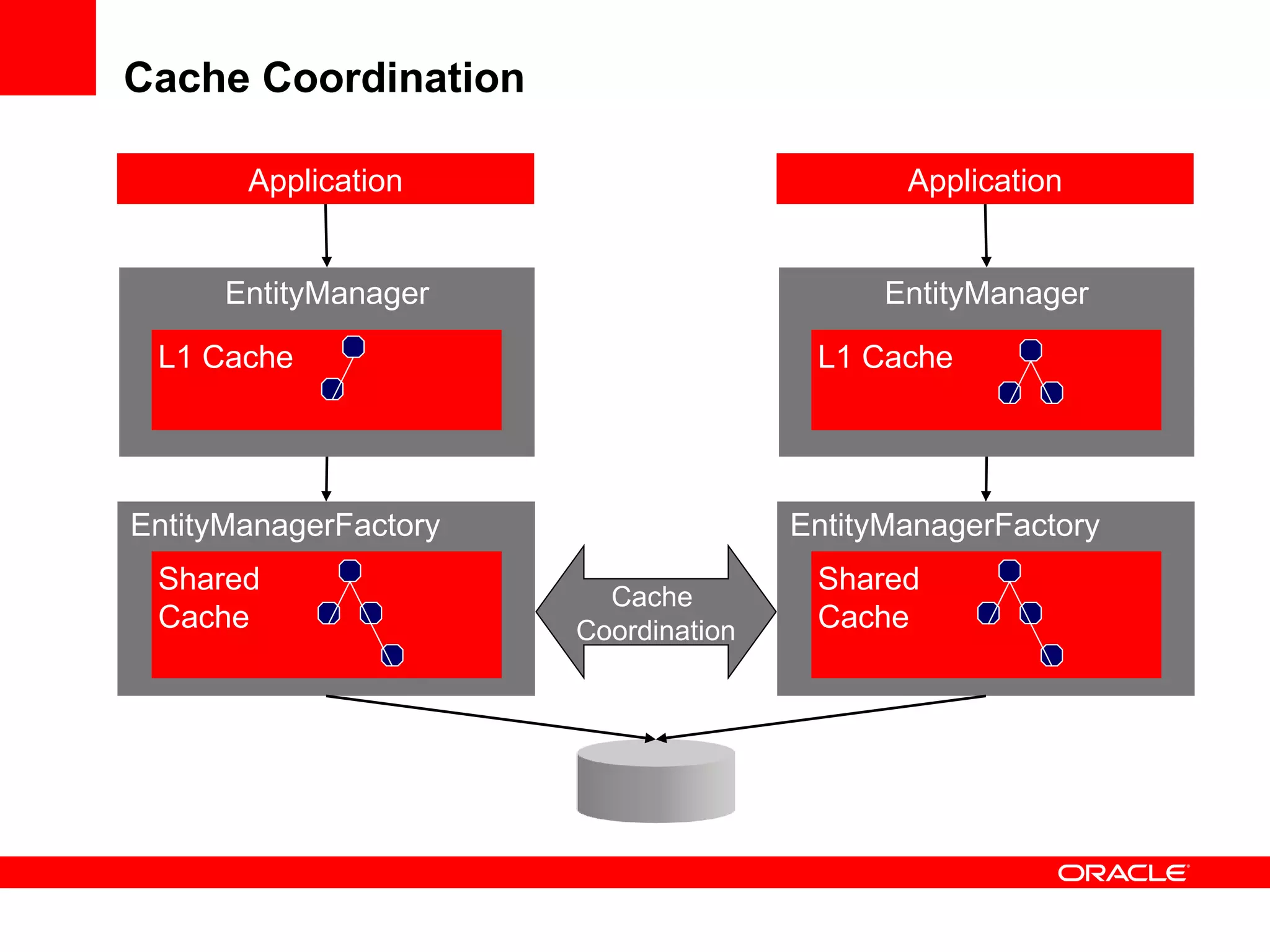
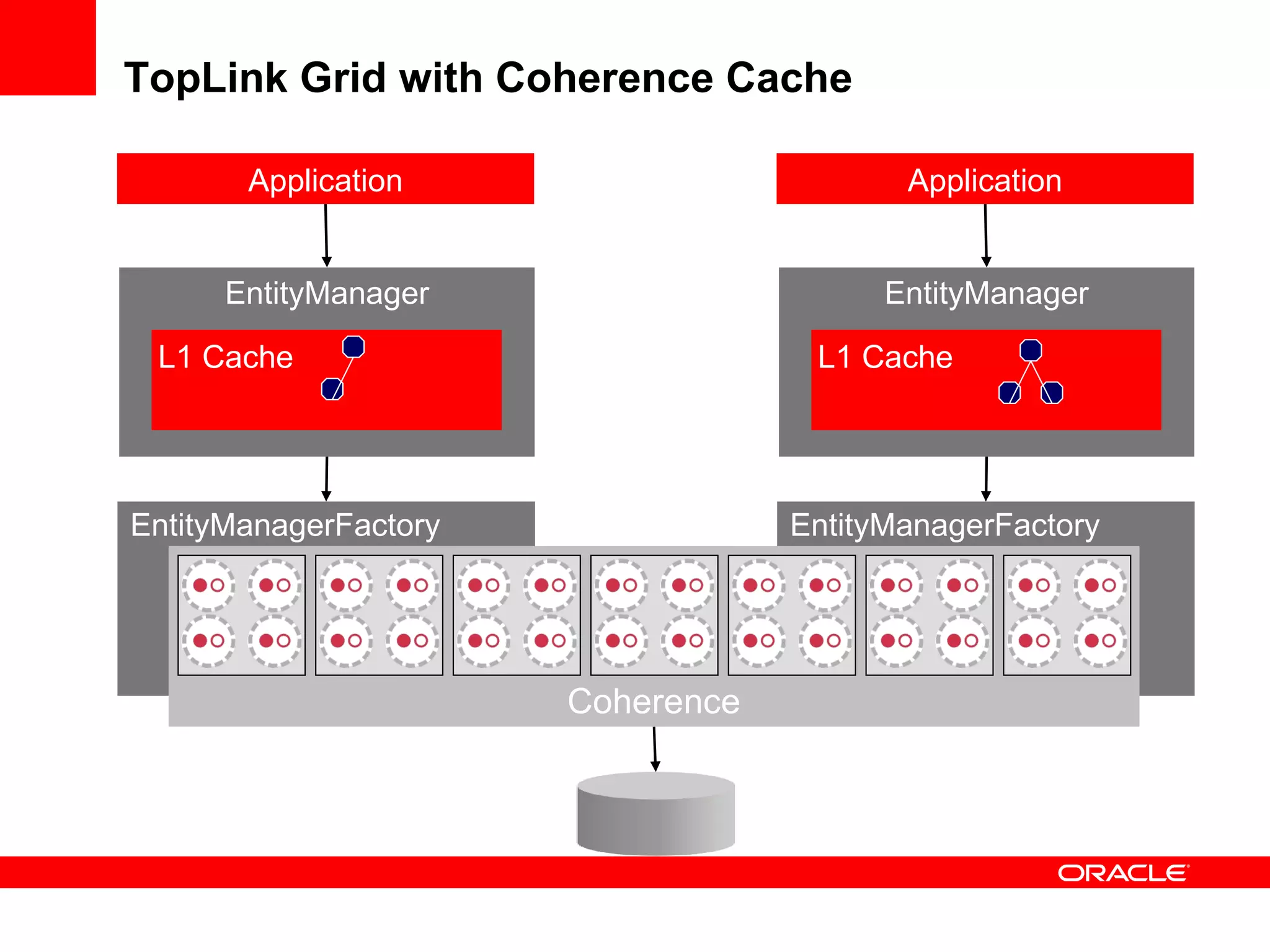
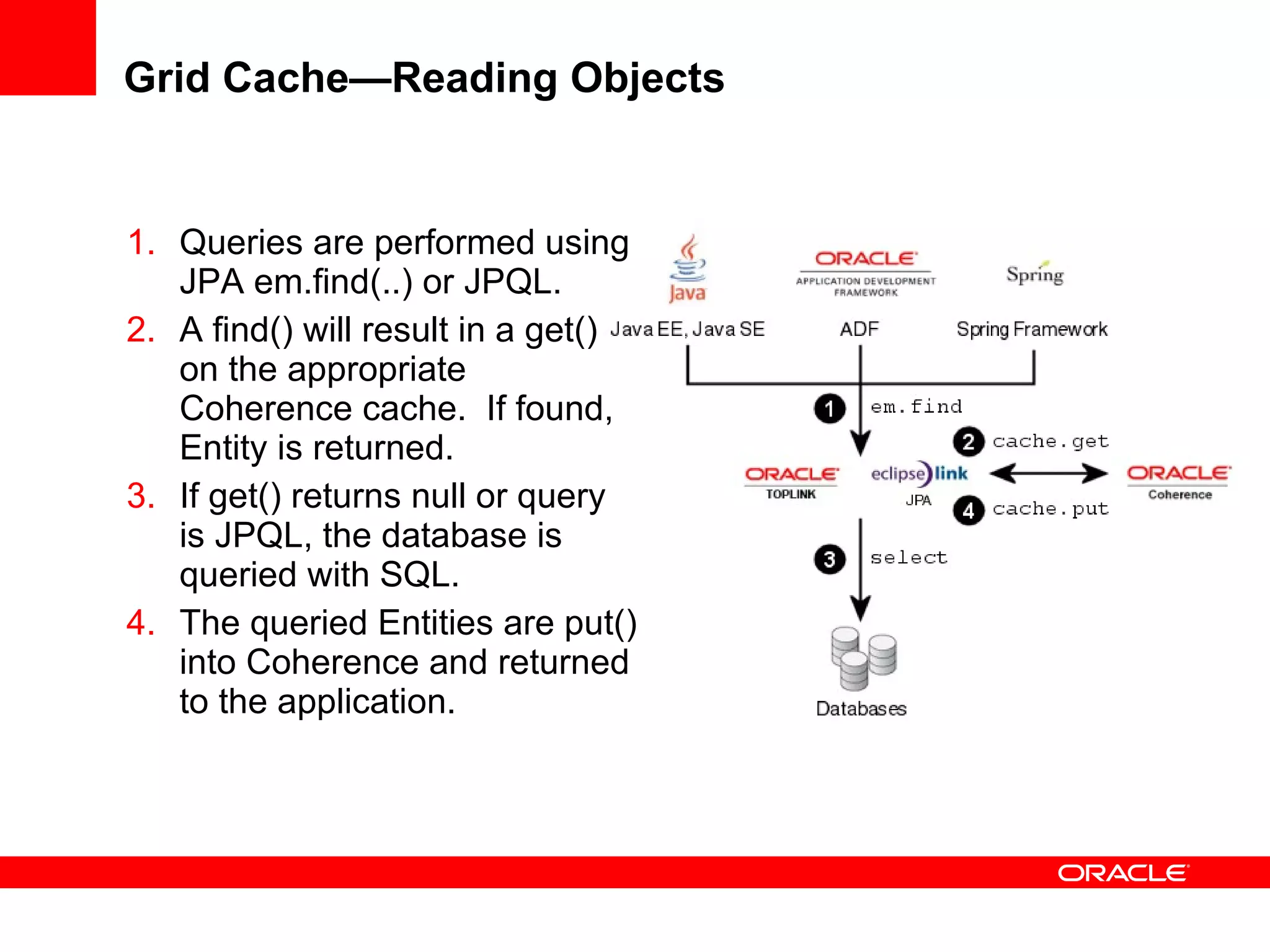
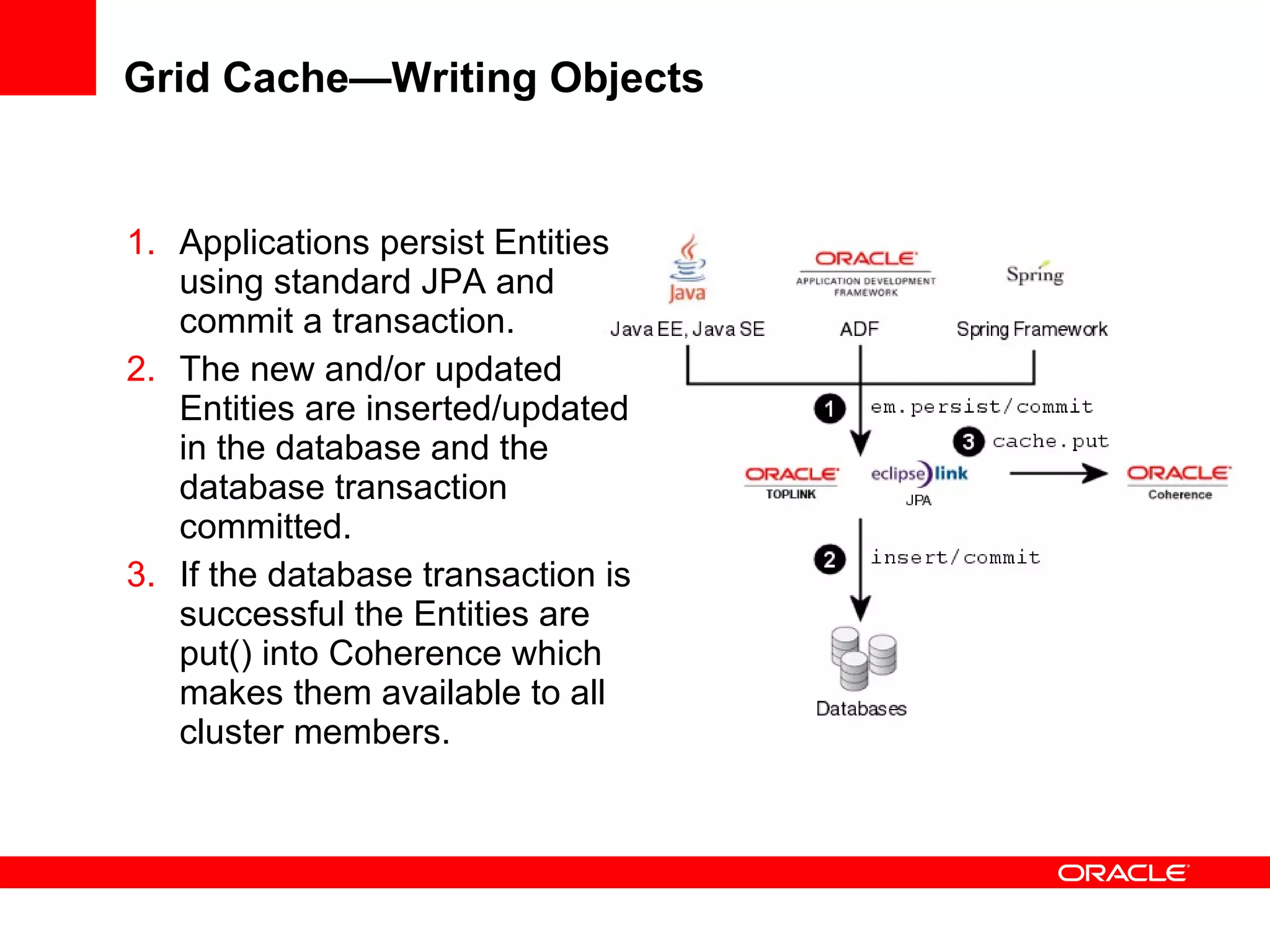
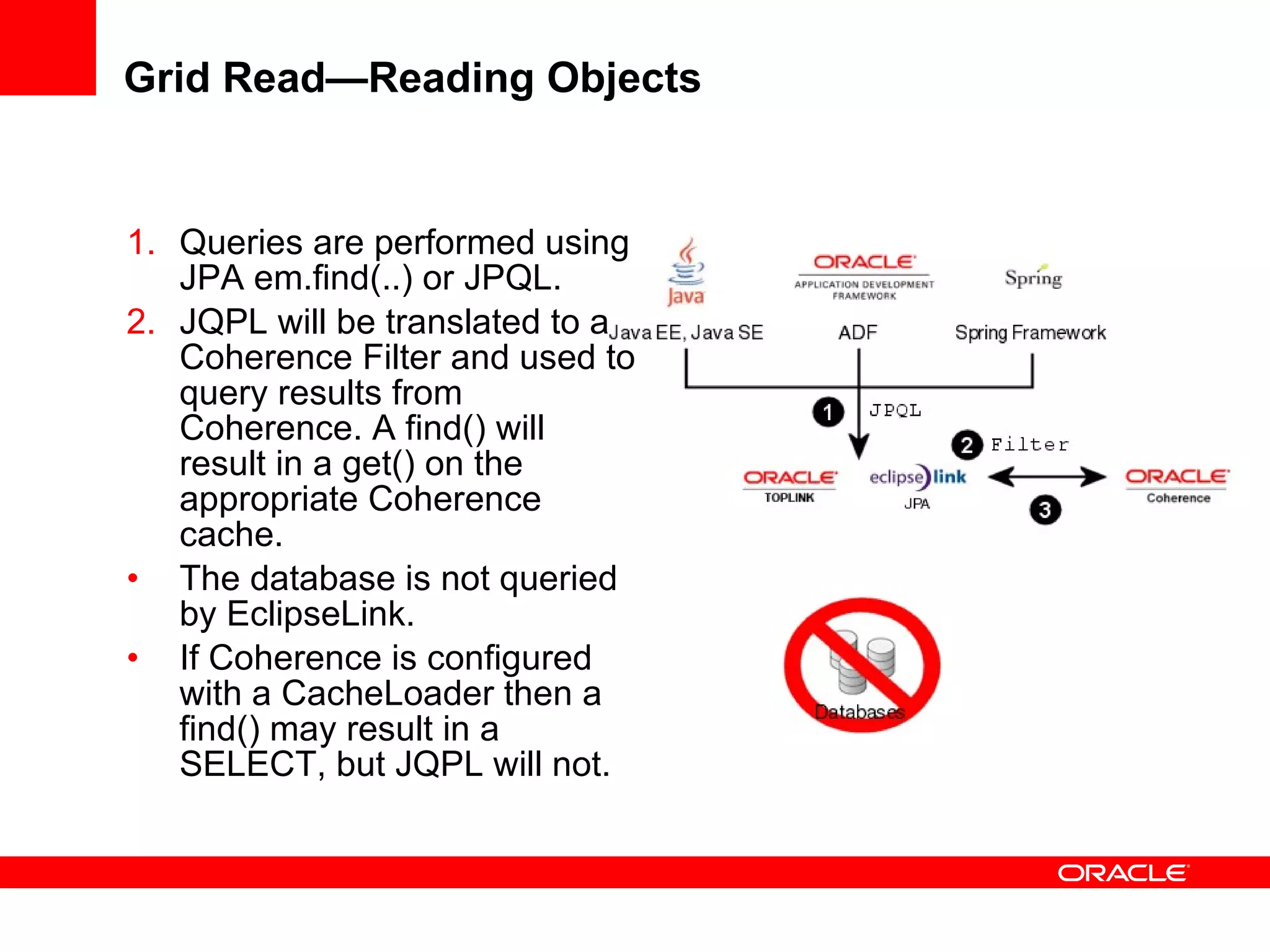
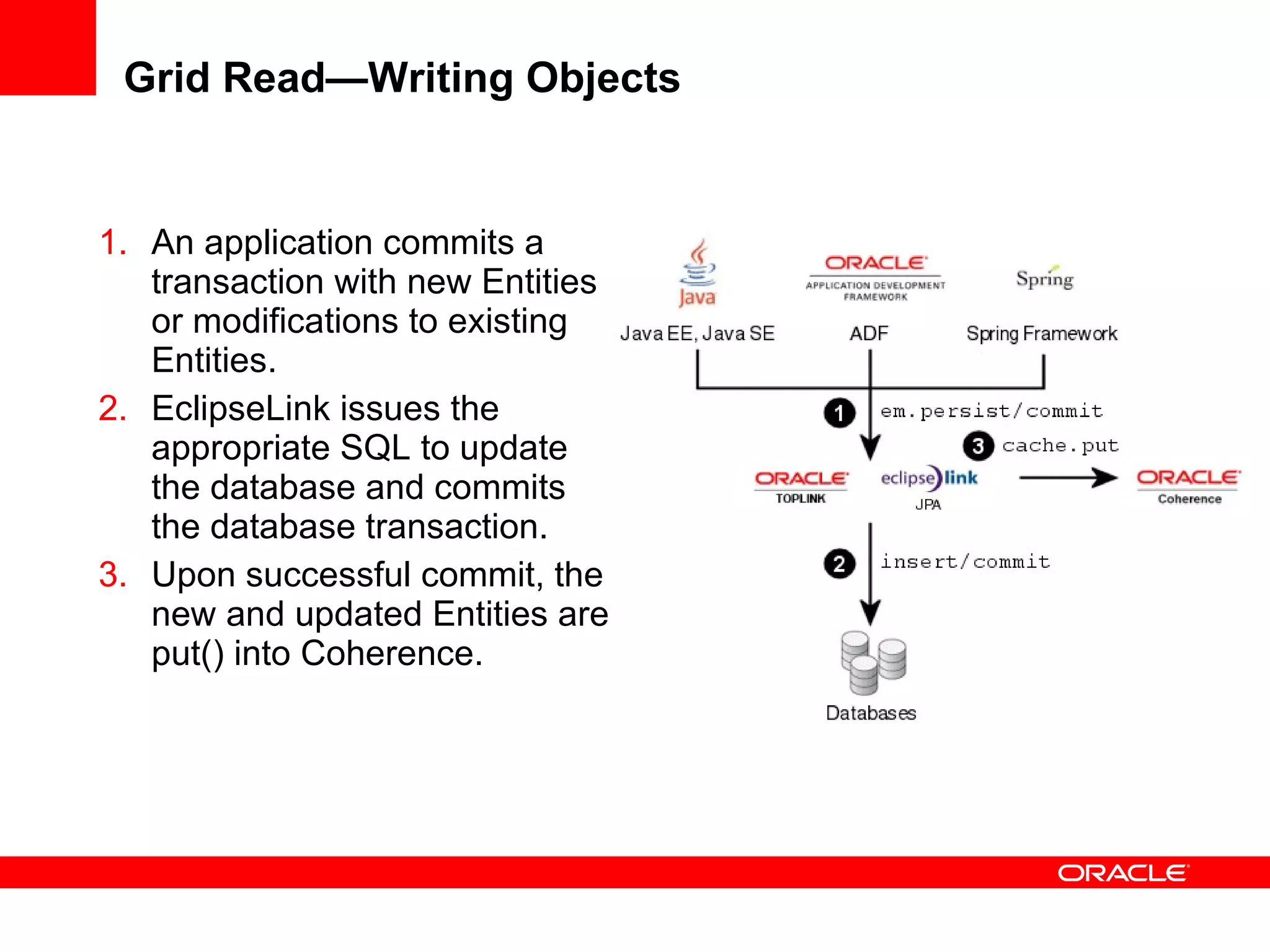
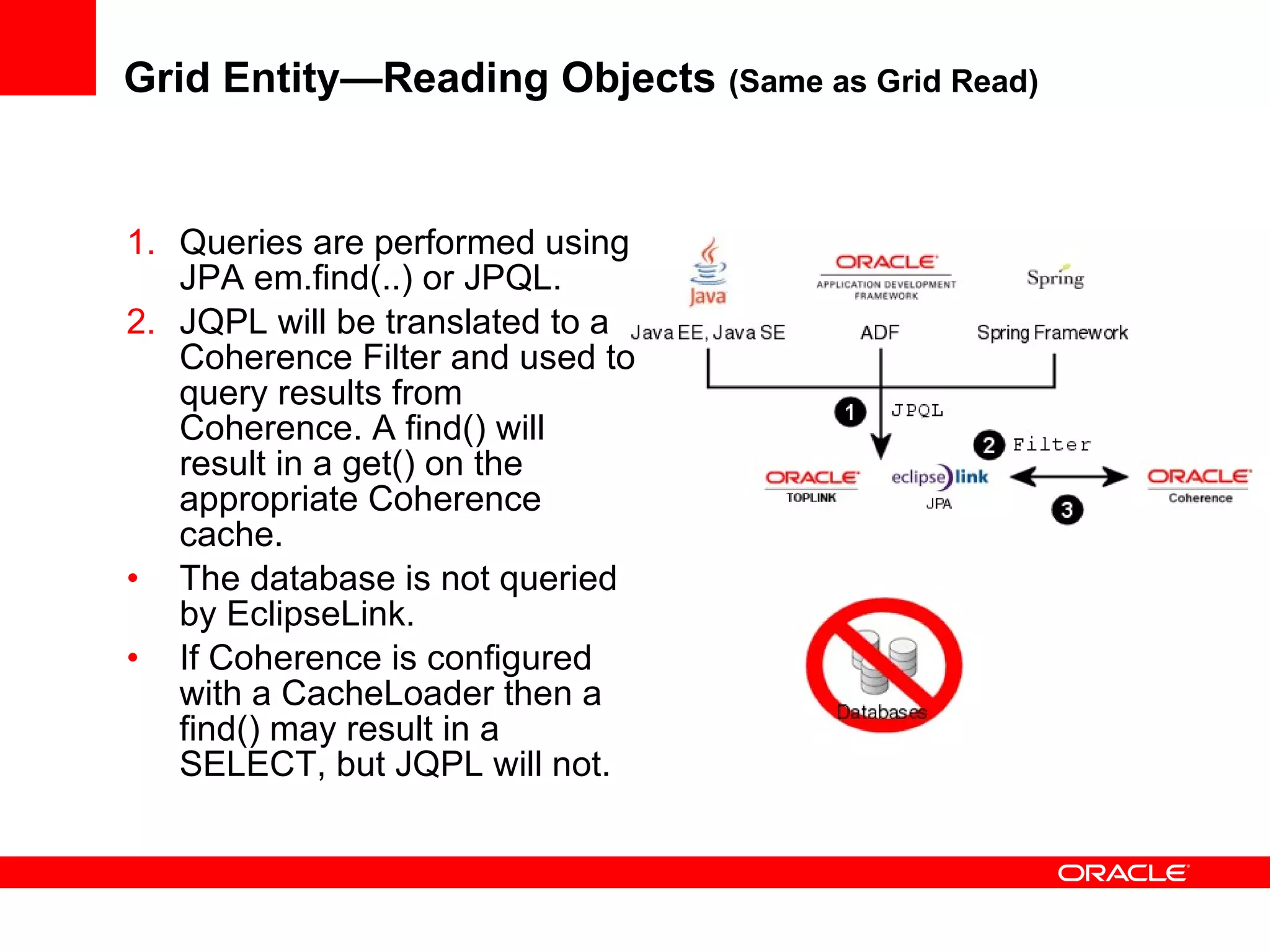
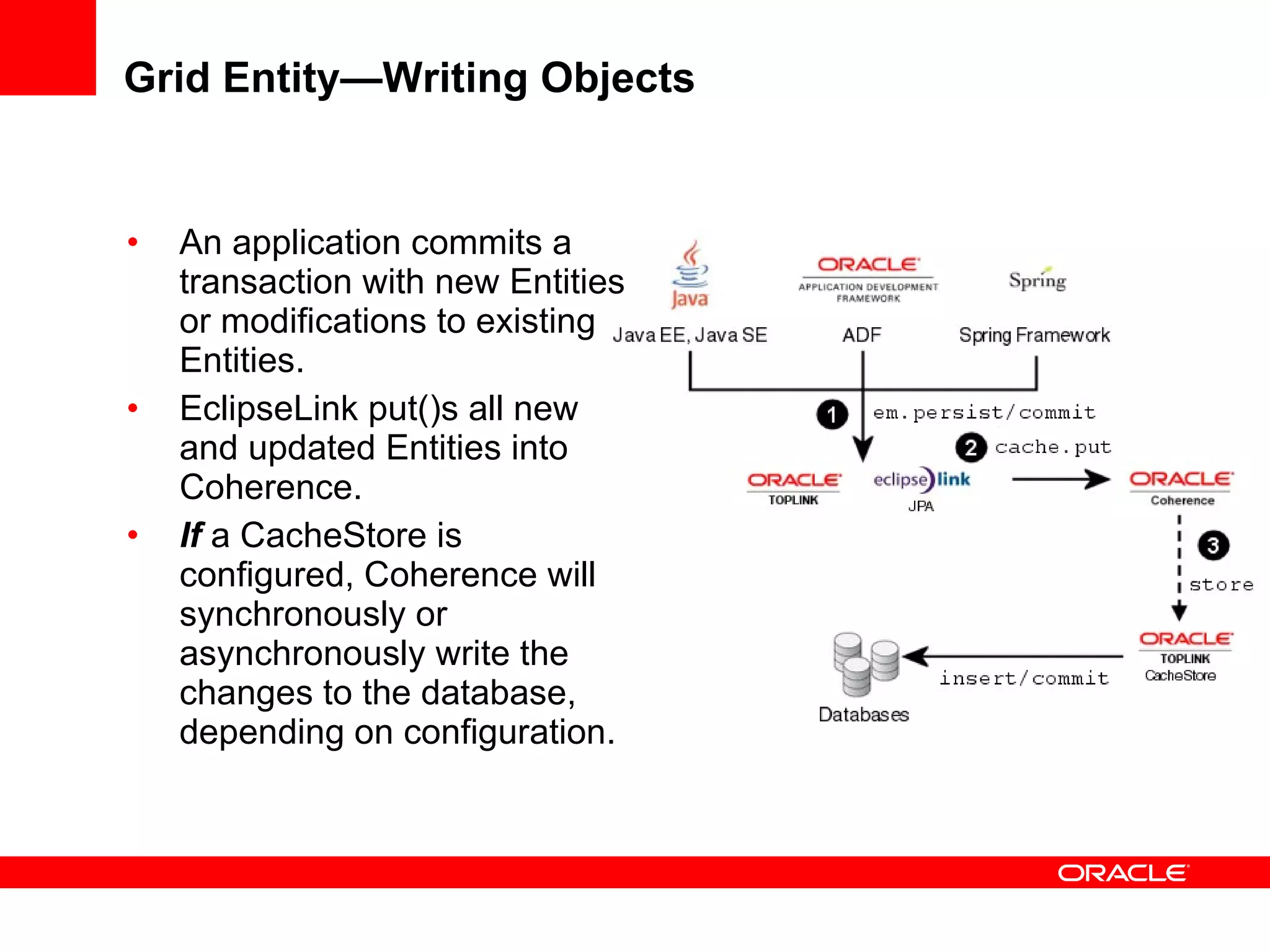
The document provides an overview of distributed caching with Coherence, JPA with TopLink Grid, and integrating Coherence with WebLogic Server. It discusses Coherence clustering, data management options like partitioned caching, data processing options like events and queries, how TopLink Grid allows scaling JPA applications using the Coherence data grid, and how Coherence servers integrate with the WebLogic lifecycle.



























































![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)


