Download to read offline







![dashDBdashDB
Predictive Analytics With R In dashDB 1/3
• Built-in R runtime
& R Studio
• ibmdbR package
Data frames logically representing data physically residing in dashDB tables
> con <- idaConnect("BLUDB", "", "")
> idaInit(con)
> sysusage<-ida.data.frame('DB2INST1.SHOWCASE_SYSUSAGE')
> systems<-ida.data.frame('DB2INST1.SHOWCASE_SYSTEMS')
> systypes<-ida.data.frame('DB2INST1.SHOWCASE_SYSTYPES’)
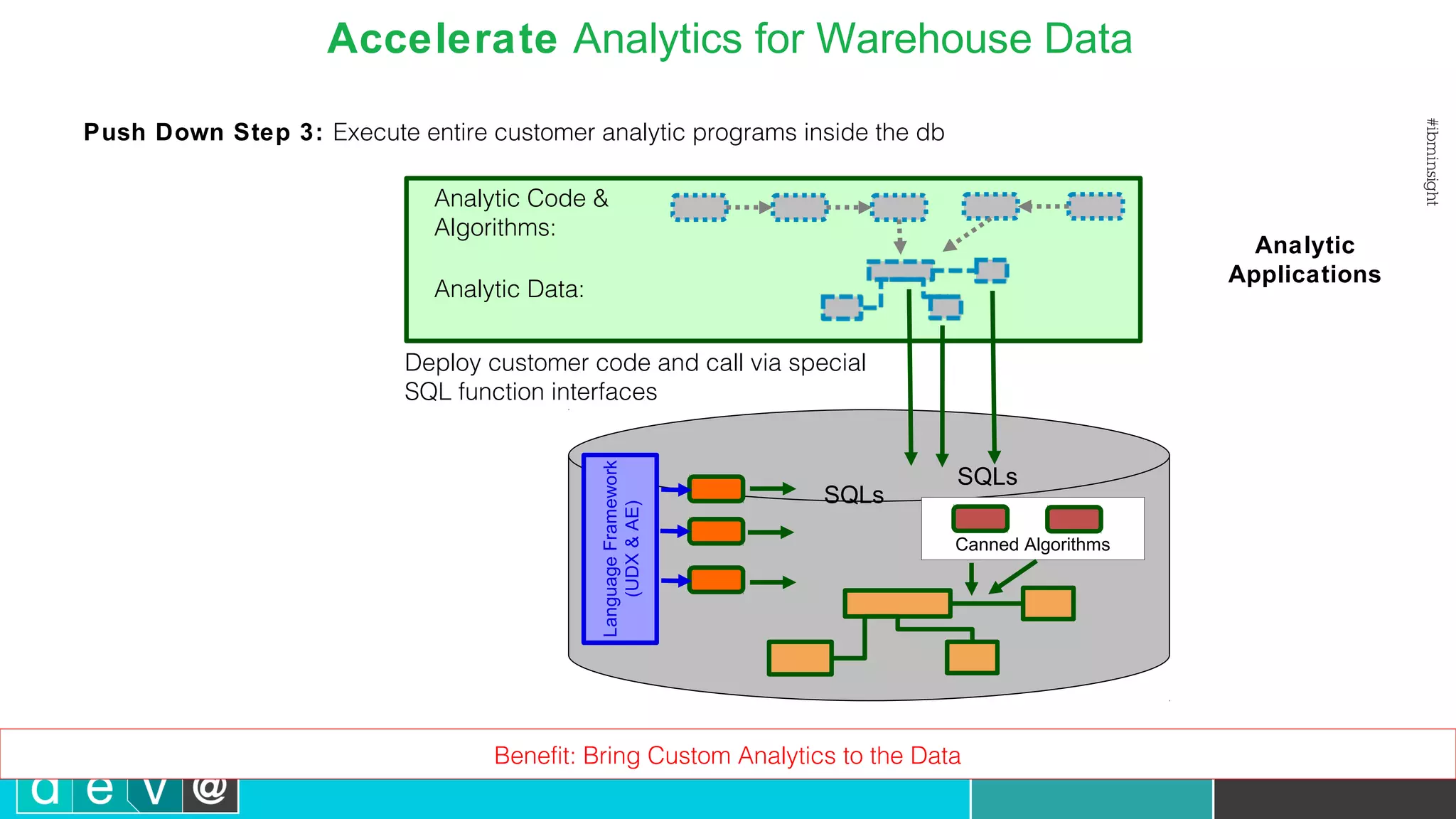
Push down of R data preparation to dashDB
> sysusage2 <- sysusage[sysusage$MEMUSED>50000,c("MEMUSED","USERS")]
> mergedSys<-idaMerge(systems, systypes, by='TYPEID')
> mergedUsage<-idaMerge(sysusage2, mergedSys, by='SID’)
Push down of analytic algorithms to in-db execution
> lm1 <- idaLm(MEMUSED~USERS, mergedUsage)
R RuntimeR Runtime
BrowserBrowser
Any R RuntimeAny R Runtime
ibmdbRibmdbR
ibmdbRibmdbR
RStudioRStudio
REST Client
REST](https://image.slidesharecdn.com/insight20151824dashdbtwitter-161204121241/75/IBM-Insight-2015-1824-Using-Bluemix-and-dashDB-for-Twitter-Analysis-12-2048.jpg)

![Predictive Analytics With R In dashDB 3/3
Store R objects in Dynamite database
> myPrivateObjects <- ida.list(type='private’)
> myPrivateObjects['series100'] <- 1:100
> x <- myPrivateObjects['series100’]
> X
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
[23] 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44
[45] 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66
[67] 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88
[89] 89 90 91 92 93 94 95 96 97 98 99 100
> names(myPrivateObjects)
[1] "series100”
> myPrivateObjects['series100'] <- NULL
Manage Dynamite tables
> idaExistTable('DB2INST1.SHOWCASE_SYSUSAGE')
[1] TRUE
> idaShowTables()
Schema Name Owner Type
1 BLUADMIN R_OBJECTS_PRIVATE BLUADMIN T
2 BLUADMIN R_OBJECTS_PRIVATE_META BLUADMIN T
3 BLUADMIN R_OBJECTS_PUBLIC BLUADMIN T
4 BLUADMIN R_OBJECTS_PUBLIC_META BLUADMIN T
> myView <- idaCreateView(myDF)
> idaIsView(myView)
[1] TRUE
> idaDropView(myView)
> idaIsView(myView)
[1] FALSE](https://image.slidesharecdn.com/insight20151824dashdbtwitter-161204121241/75/IBM-Insight-2015-1824-Using-Bluemix-and-dashDB-for-Twitter-Analysis-14-2048.jpg)

![dashDBdashDB
Predictive Analytics With Python In dashDB
• Bluemix Analytic Notebooks
• ibmdbPy package
https://pypi.python.org/pypi/ibmdbpy
Data frames logically representing data physically residing in dashDB tables
from ibmdbpy import IdaDataFrame
idadf = IdaDataFrame(idadb, "IRIS", indexer = "ID")
idadf = idadf[["ID","sepal_length", "sepal_width"]]
idadf['new'] = idadf['sepal_width'] + idadf['sepal_length'].mean()
idadf.head()
Push down of analytic algorithms to in-db execution
from ibmdbpy.learn import KMeans
kmeans = KMeans(3) # clustering with 3 clusters
kmeans.fit_predict(idadf).head()
Analytics for Spark
Notebook in Bluemix
Analytics for Spark
Notebook in Bluemix
BrowserBrowser
Any Python RuntimeAny Python Runtime
ibmdbPyibmdbPy
ibmdbPyibmdbPy](https://image.slidesharecdn.com/insight20151824dashdbtwitter-161204121241/75/IBM-Insight-2015-1824-Using-Bluemix-and-dashDB-for-Twitter-Analysis-16-2048.jpg)
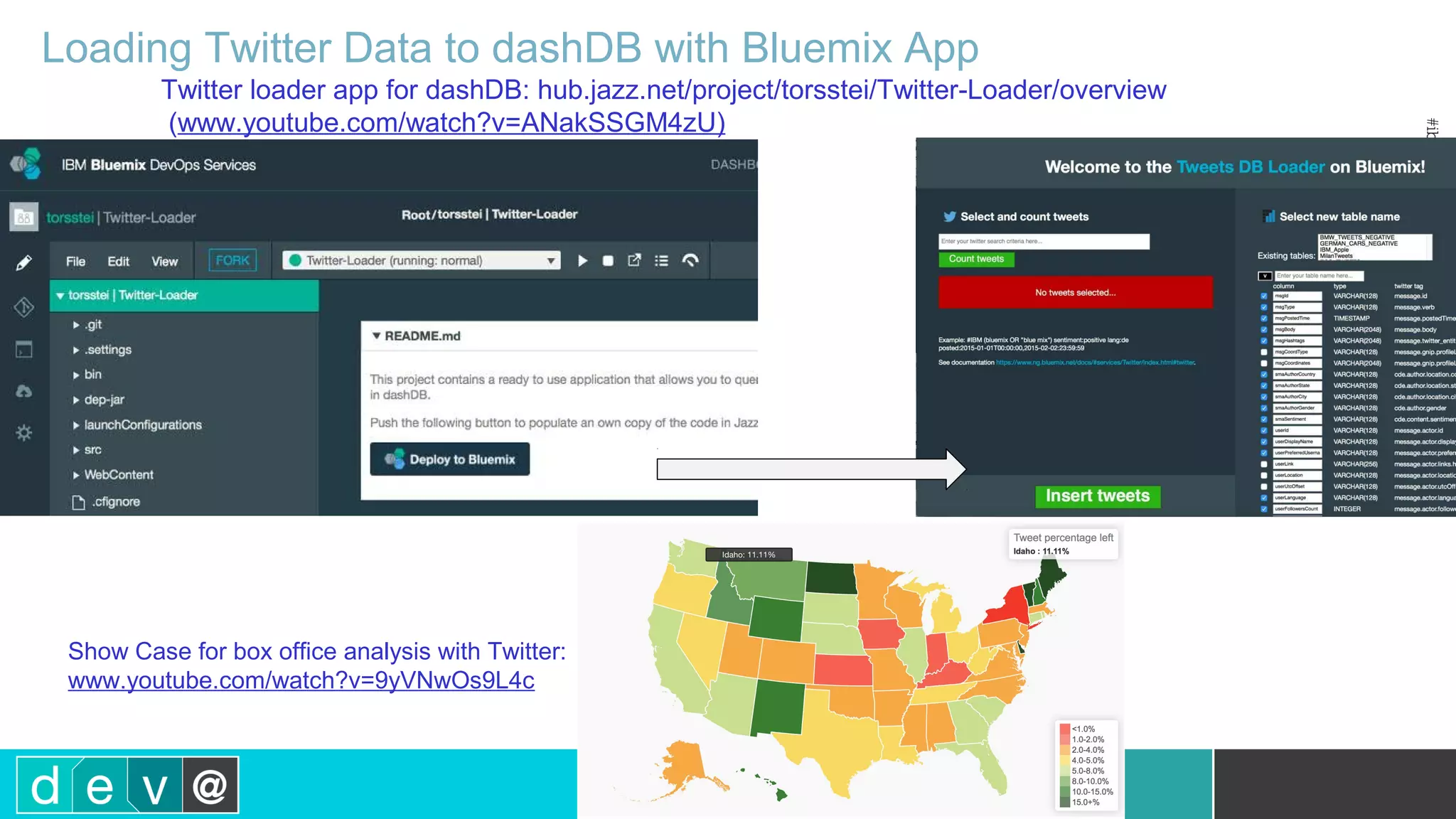
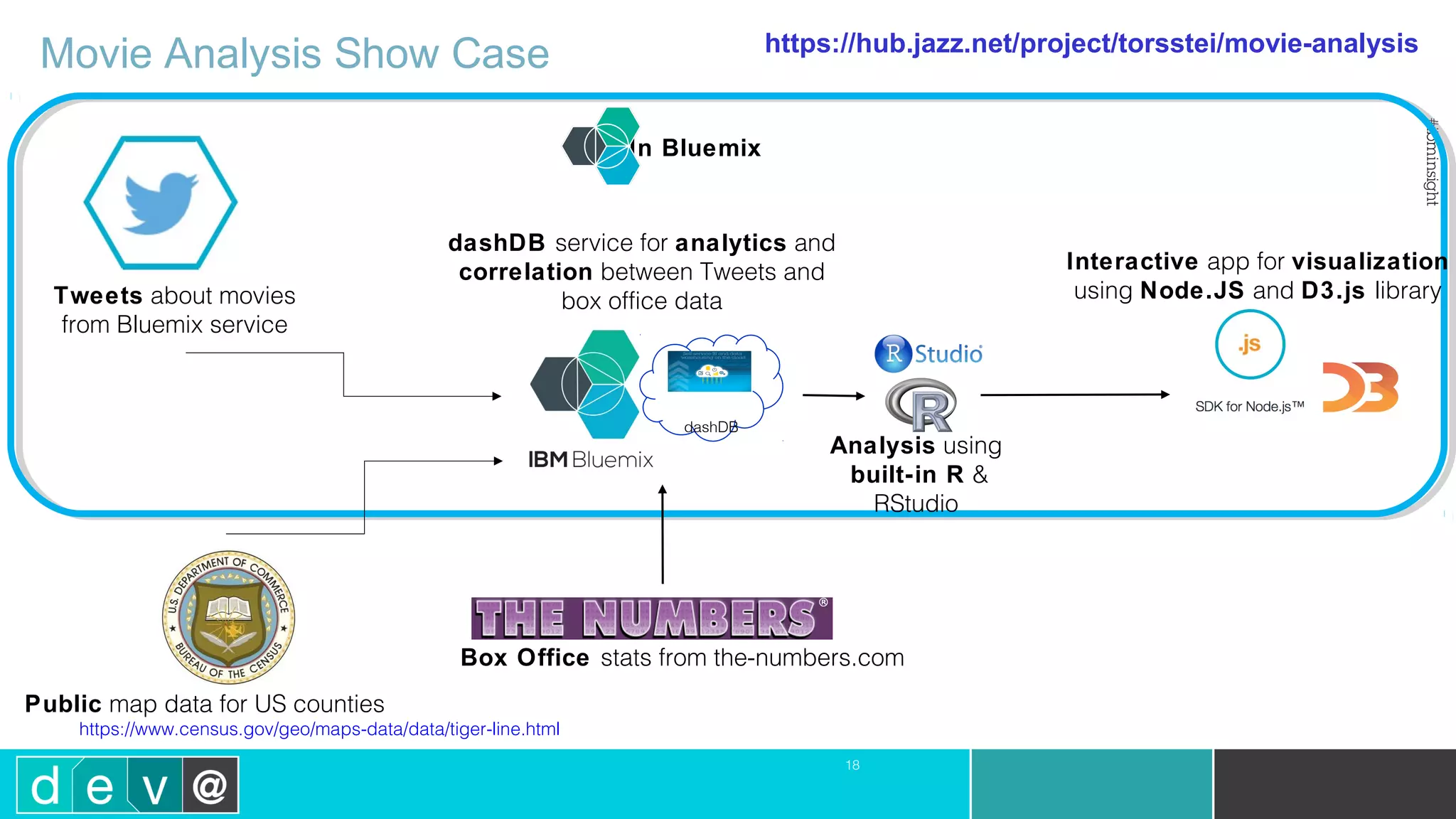
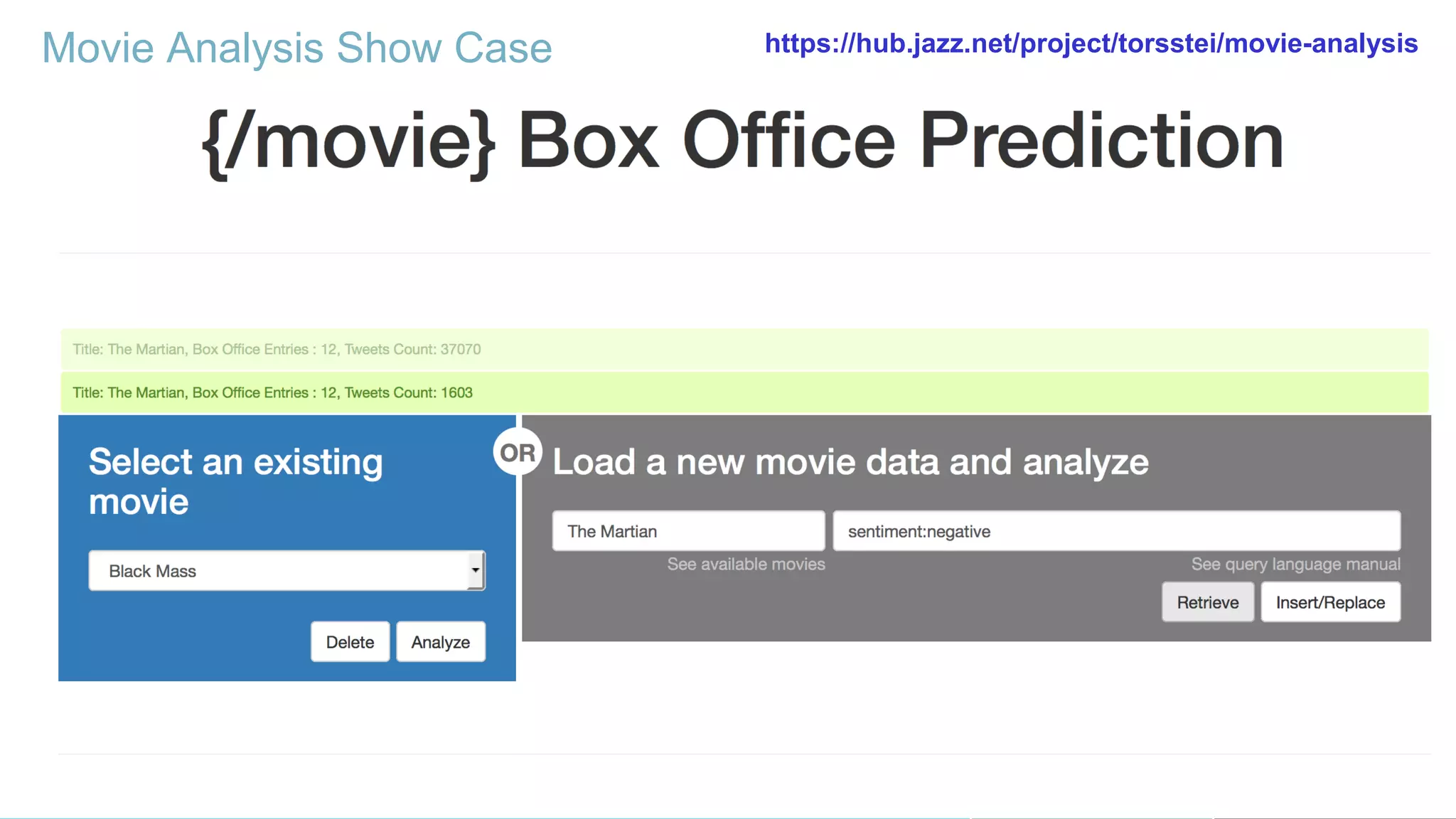
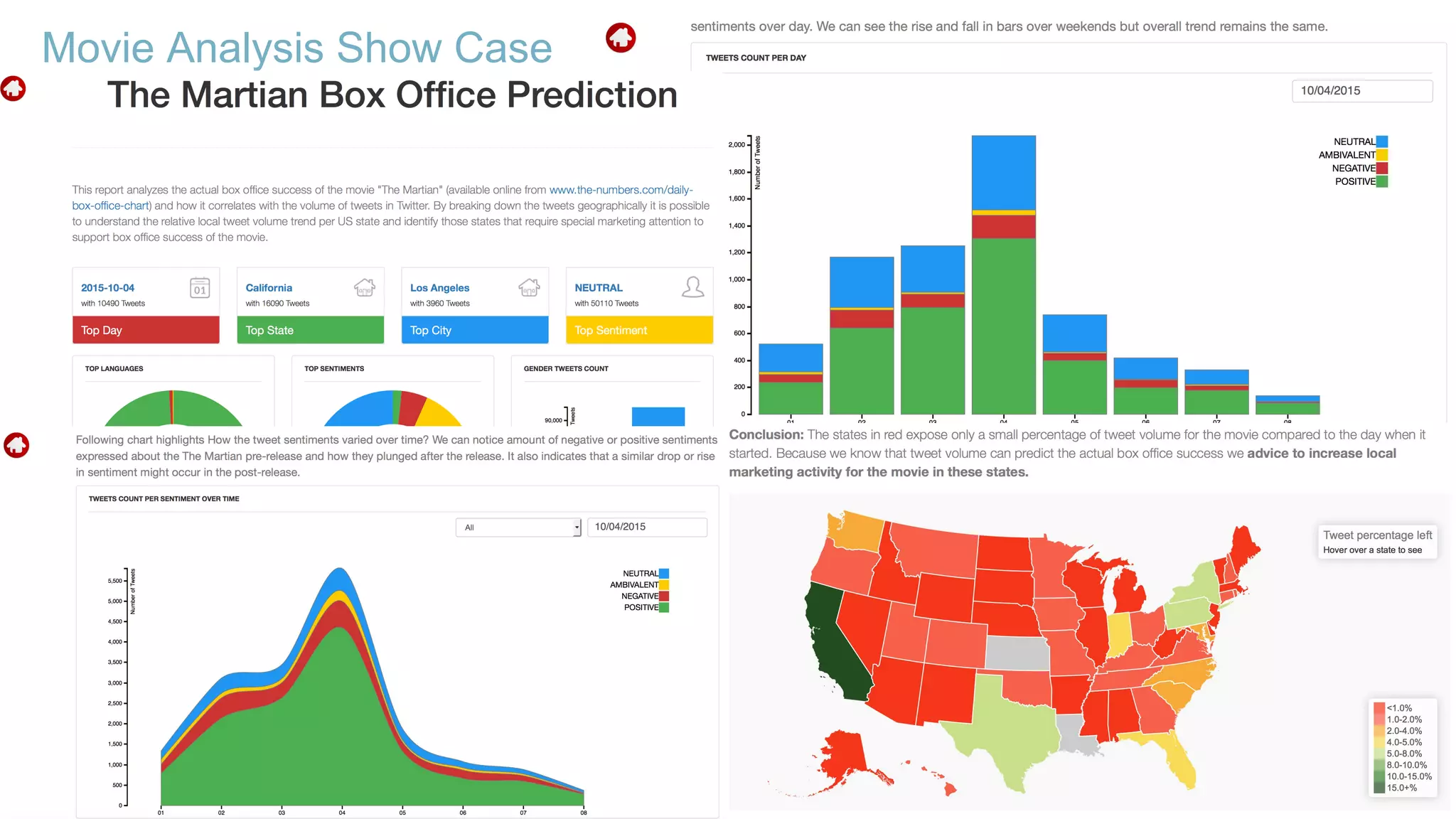
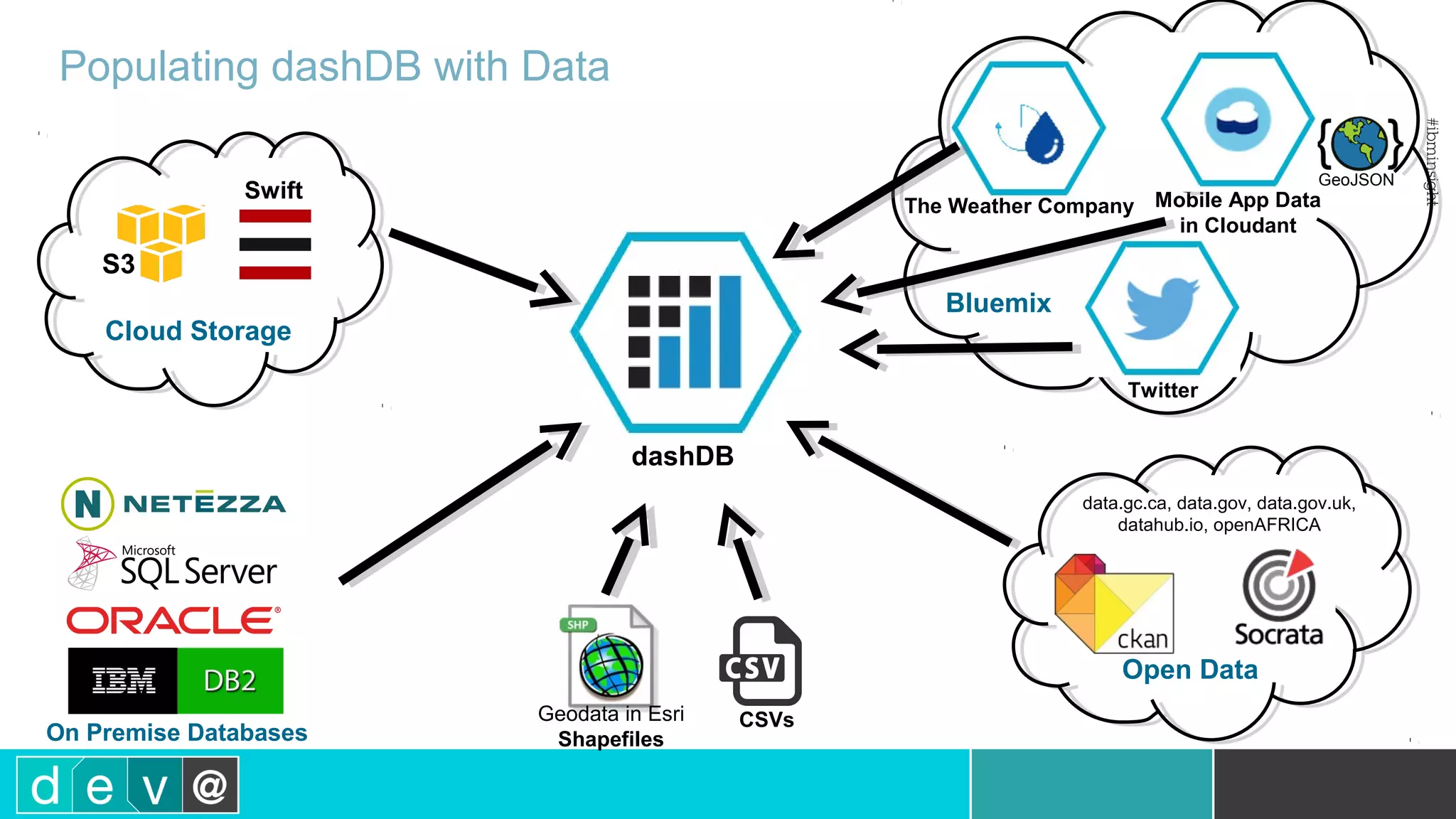
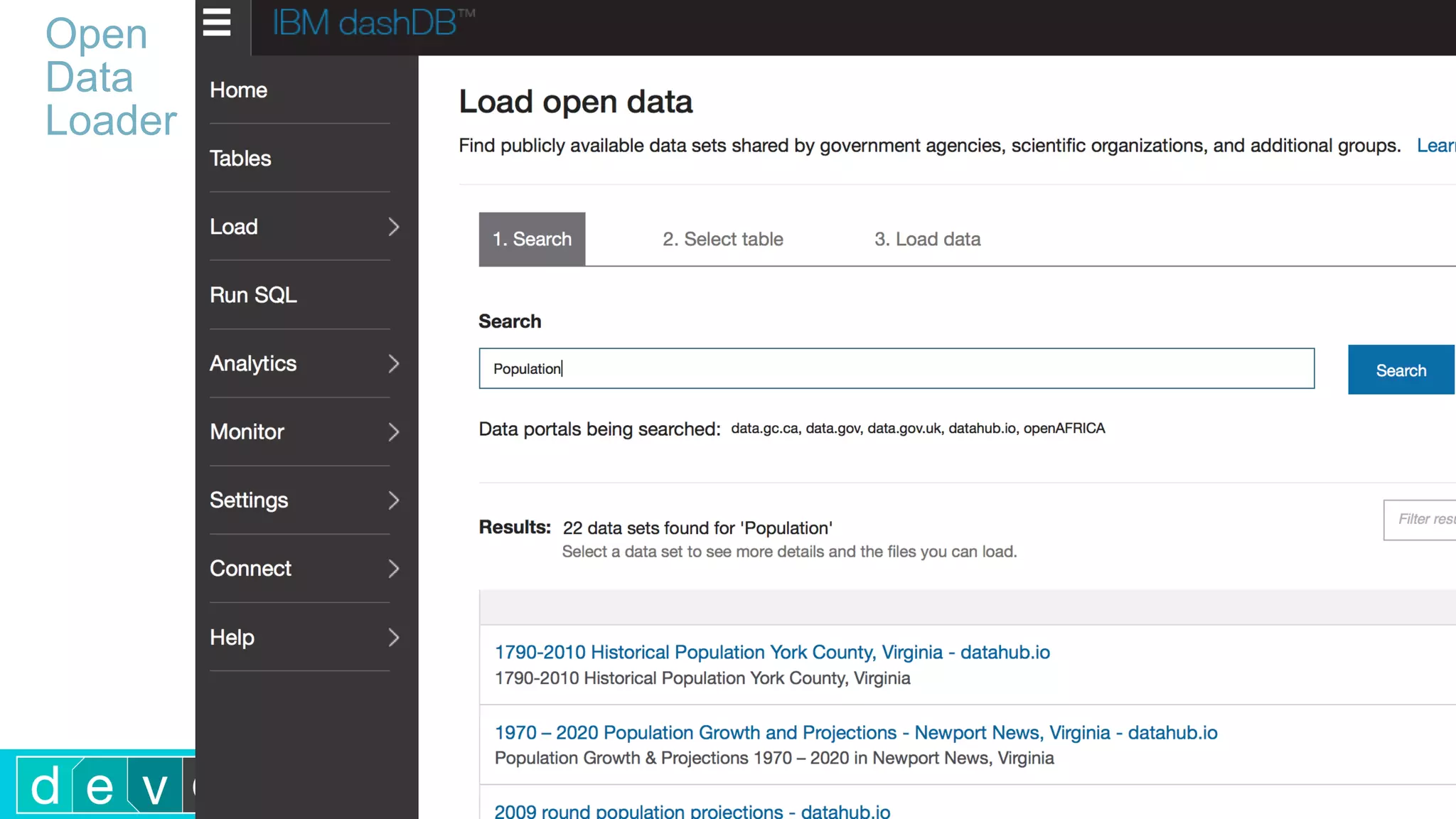
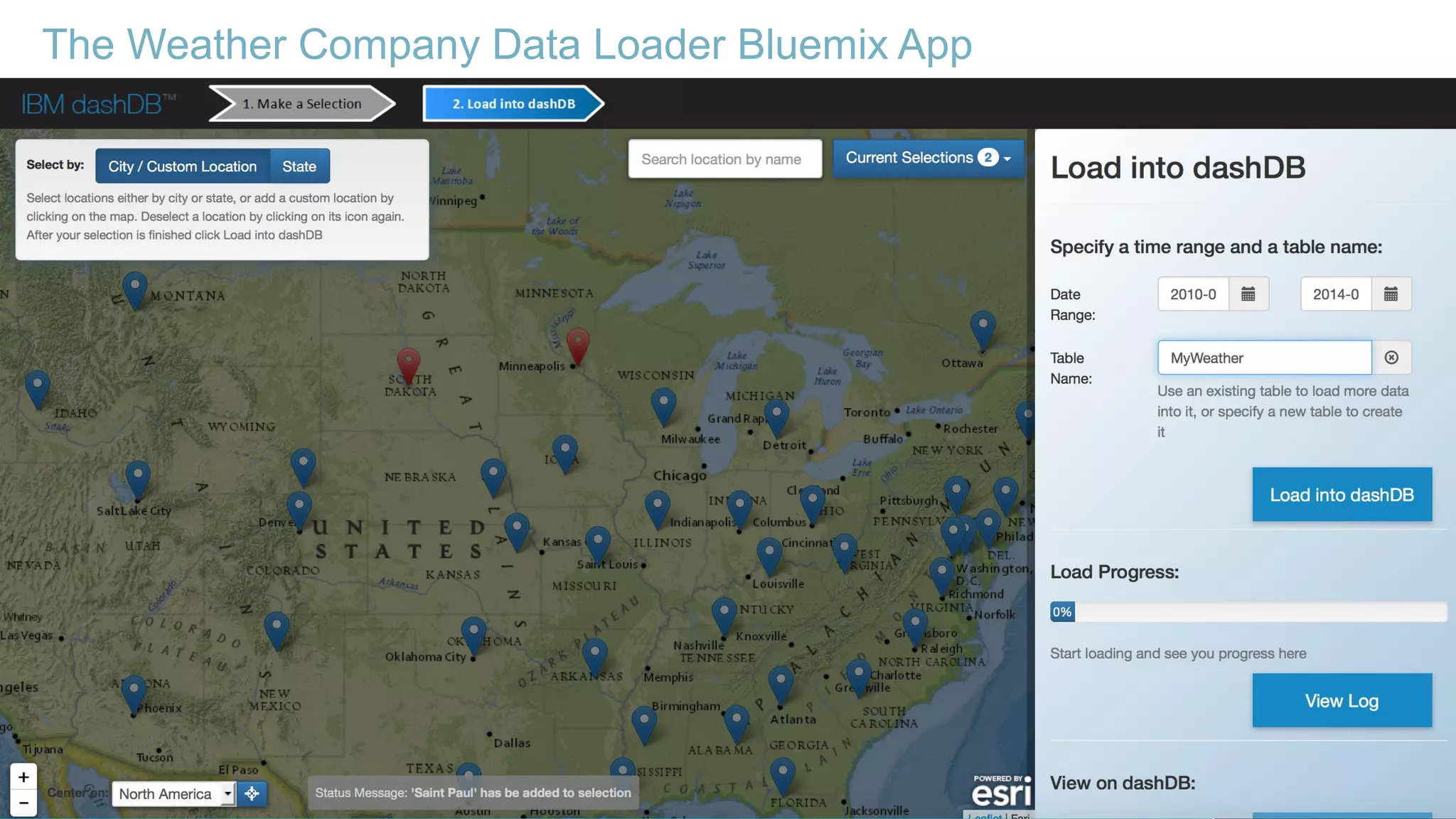

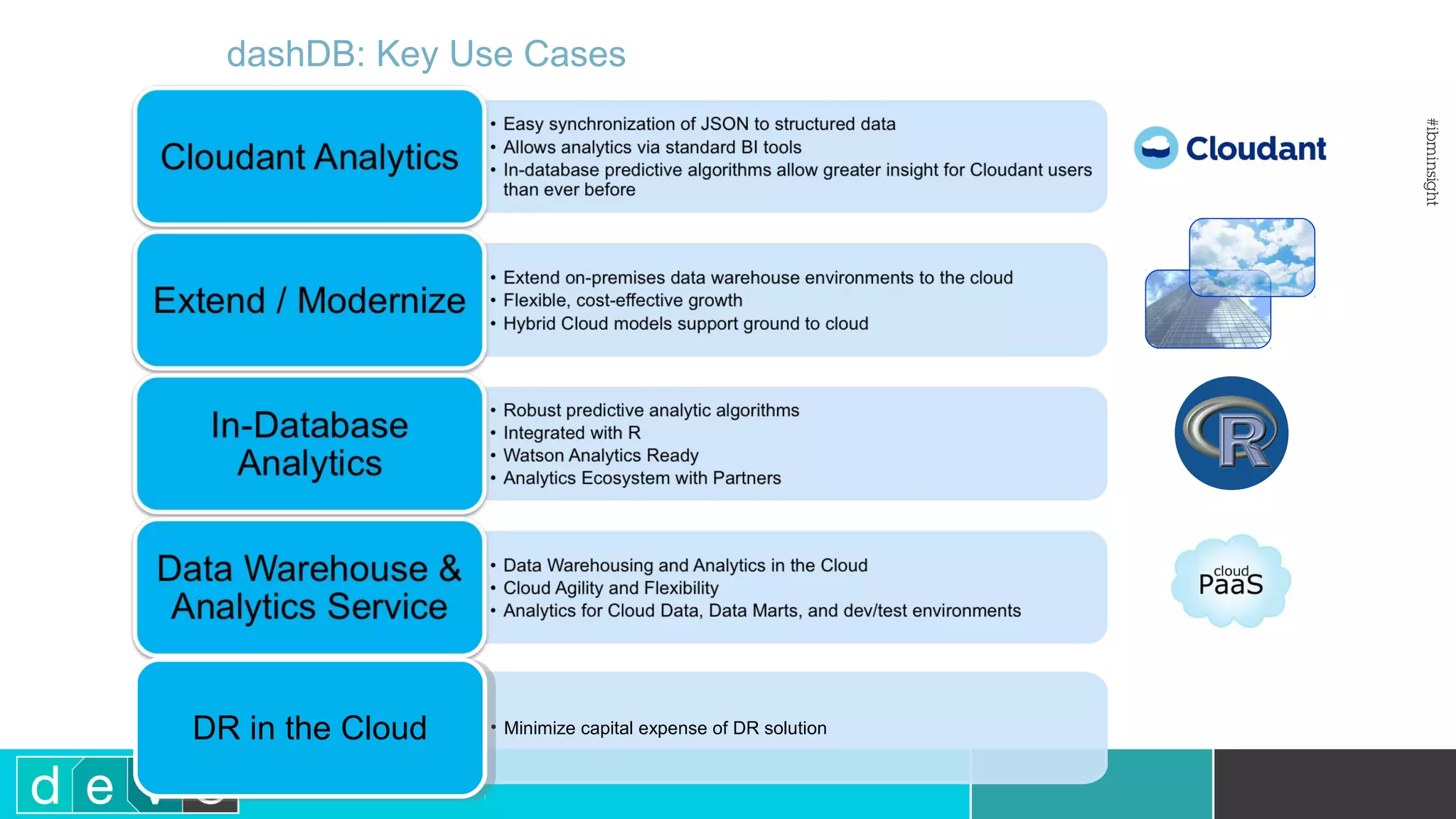
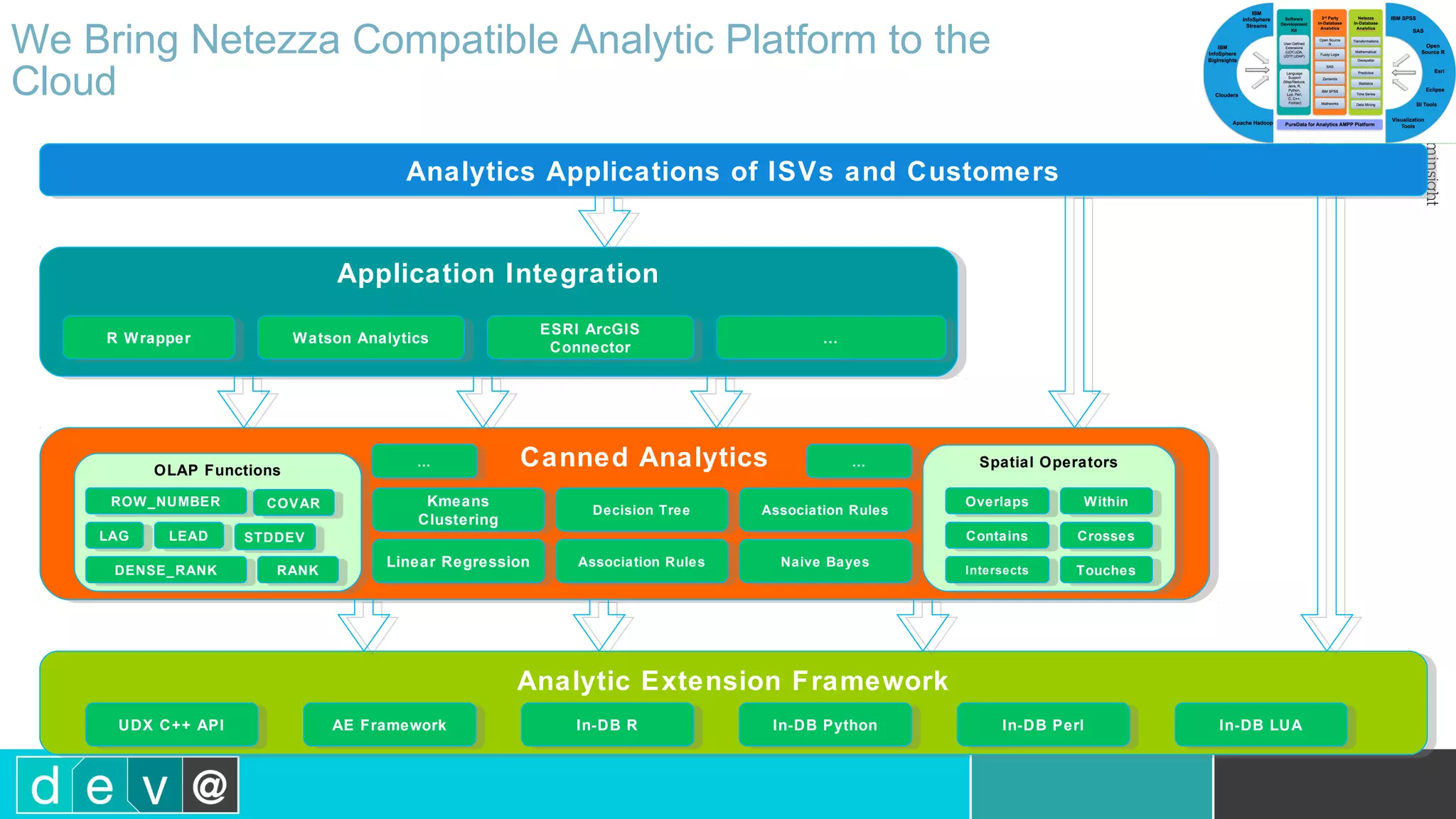
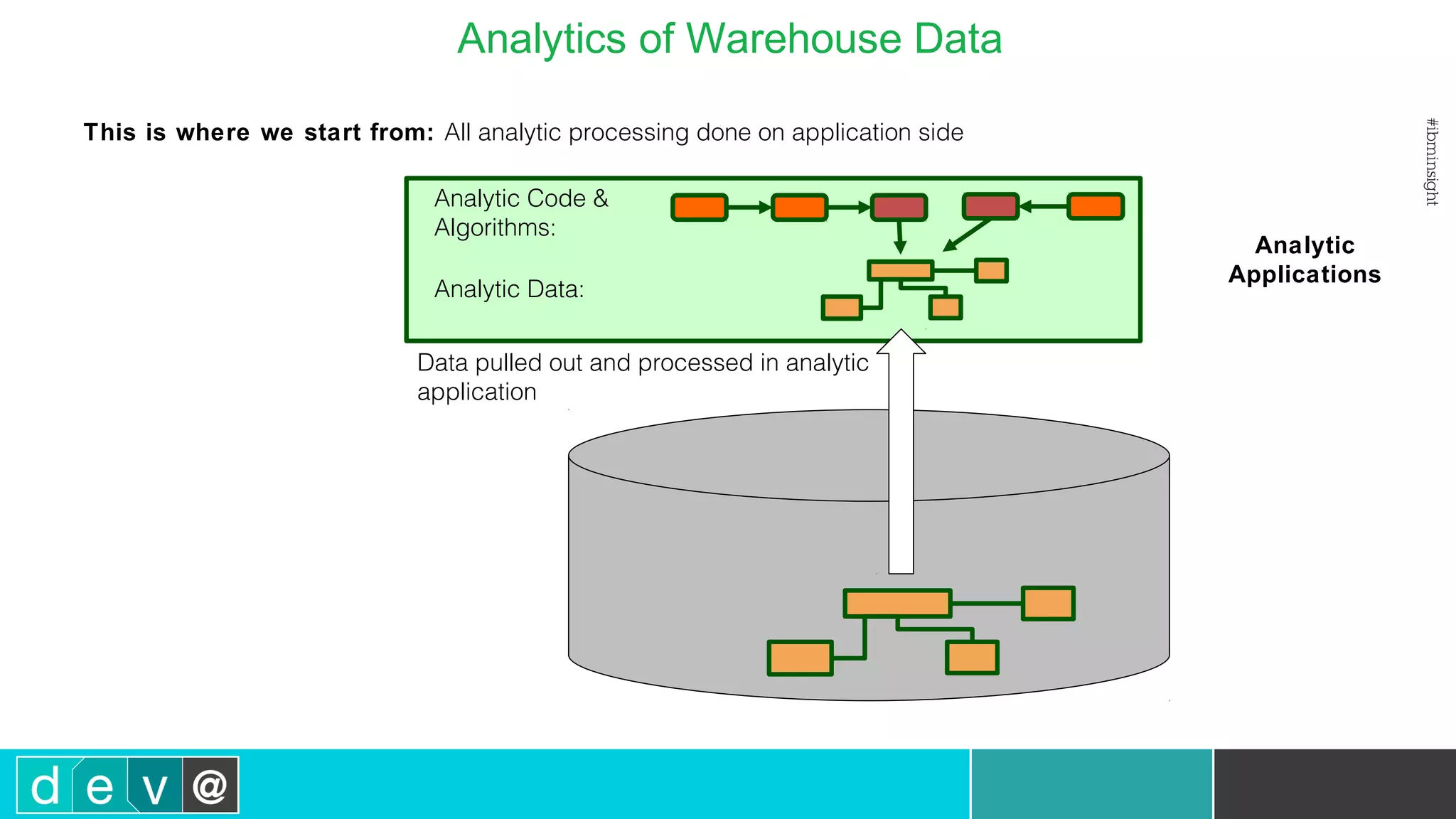
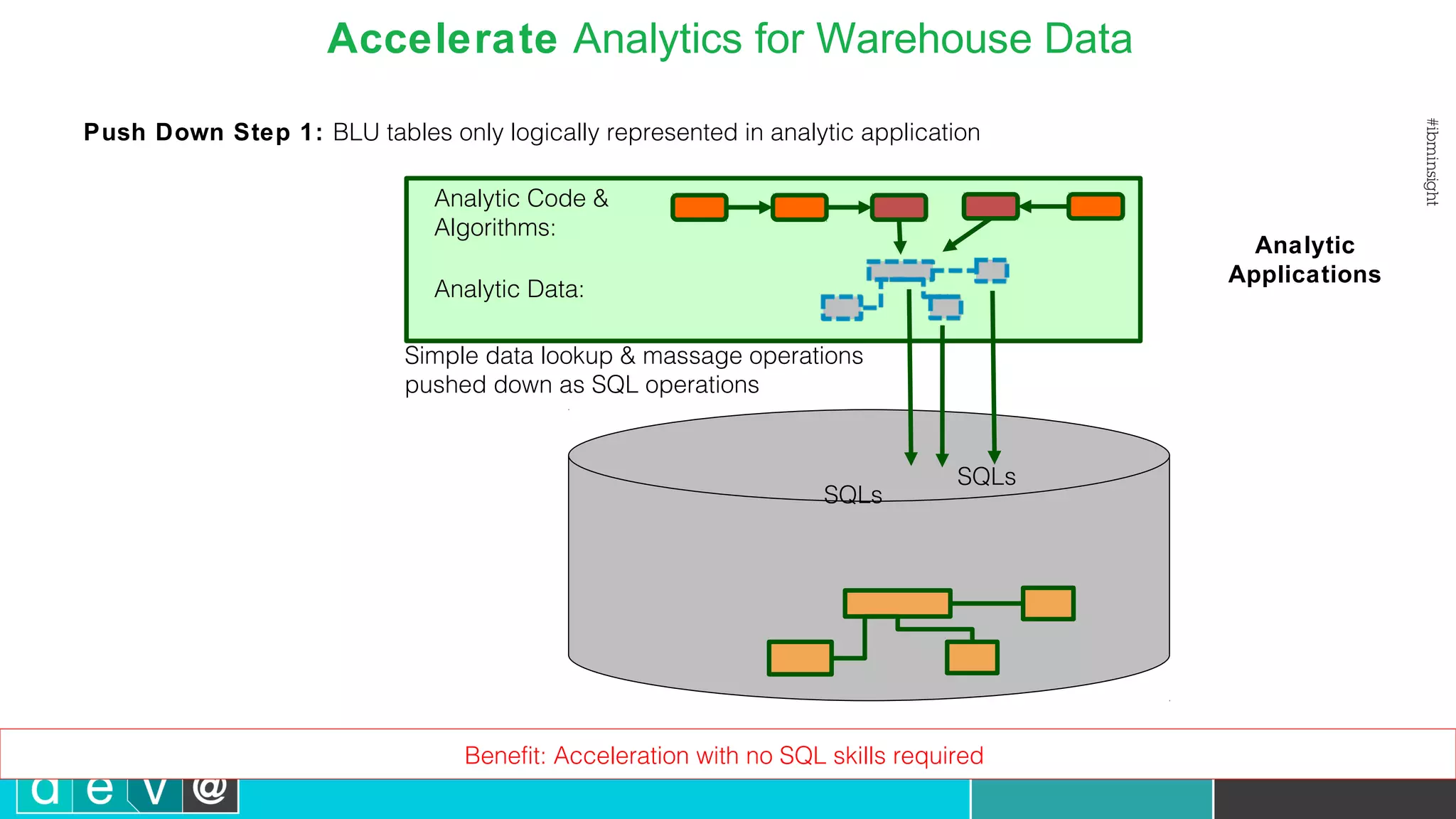
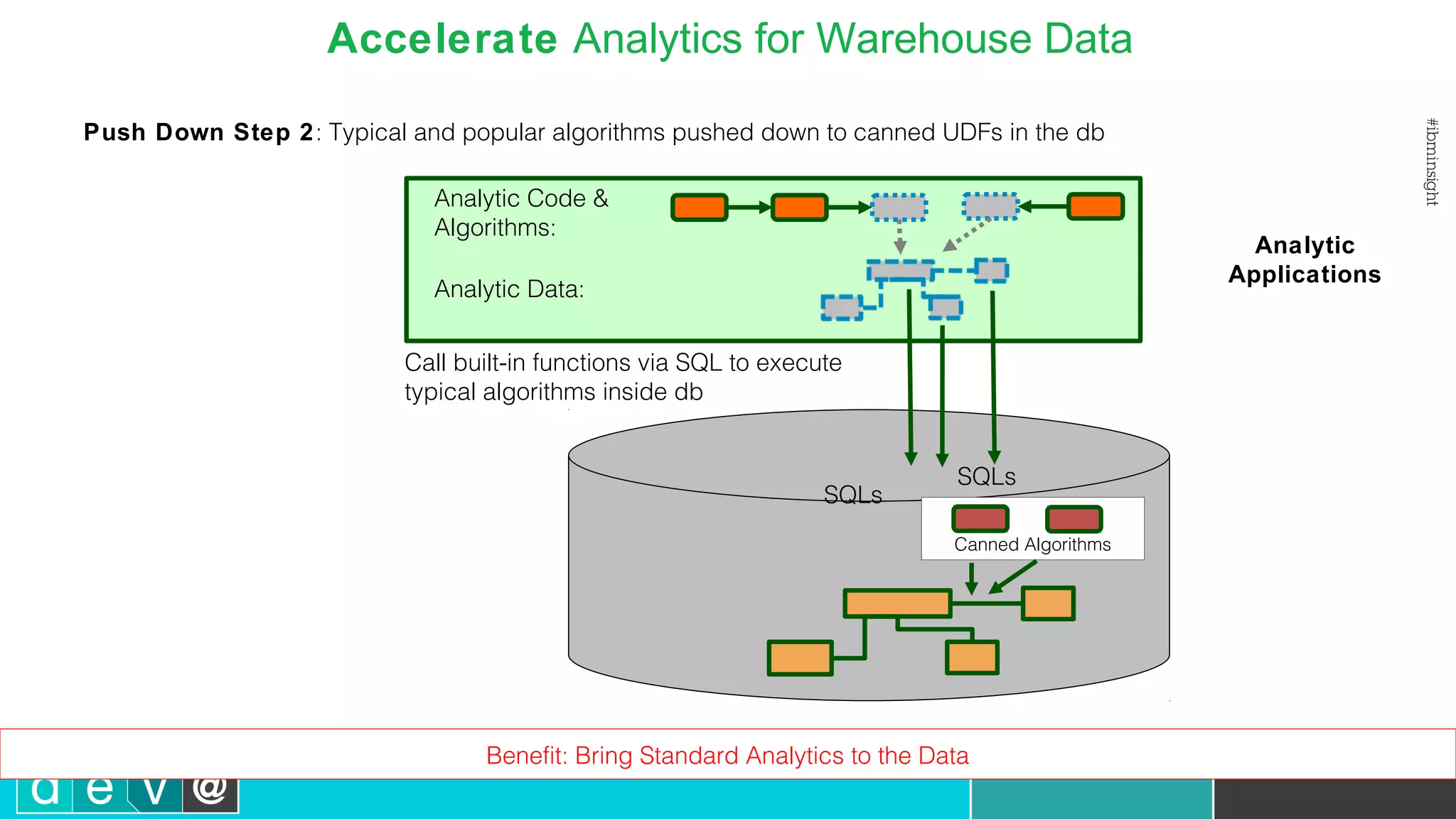





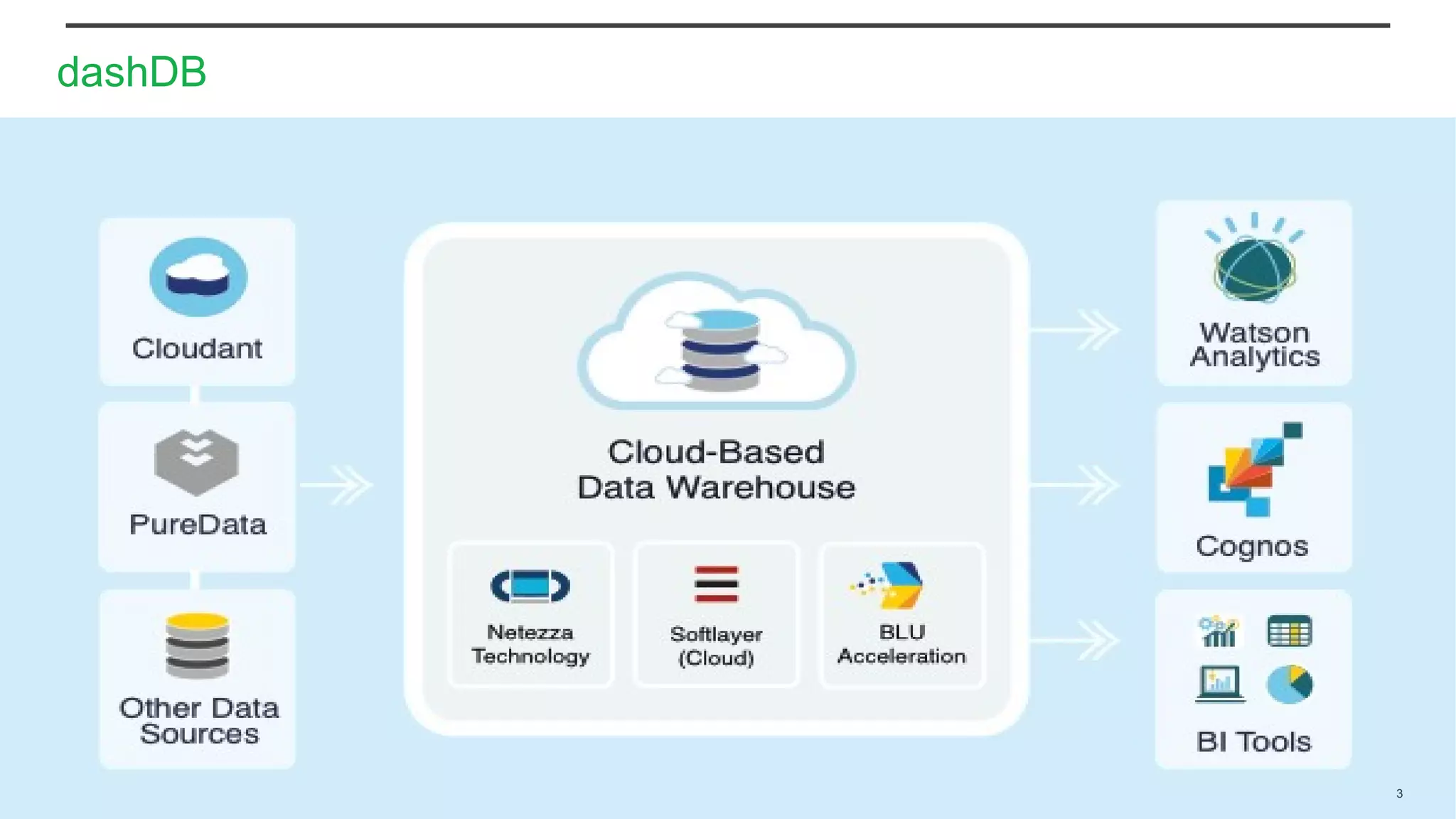
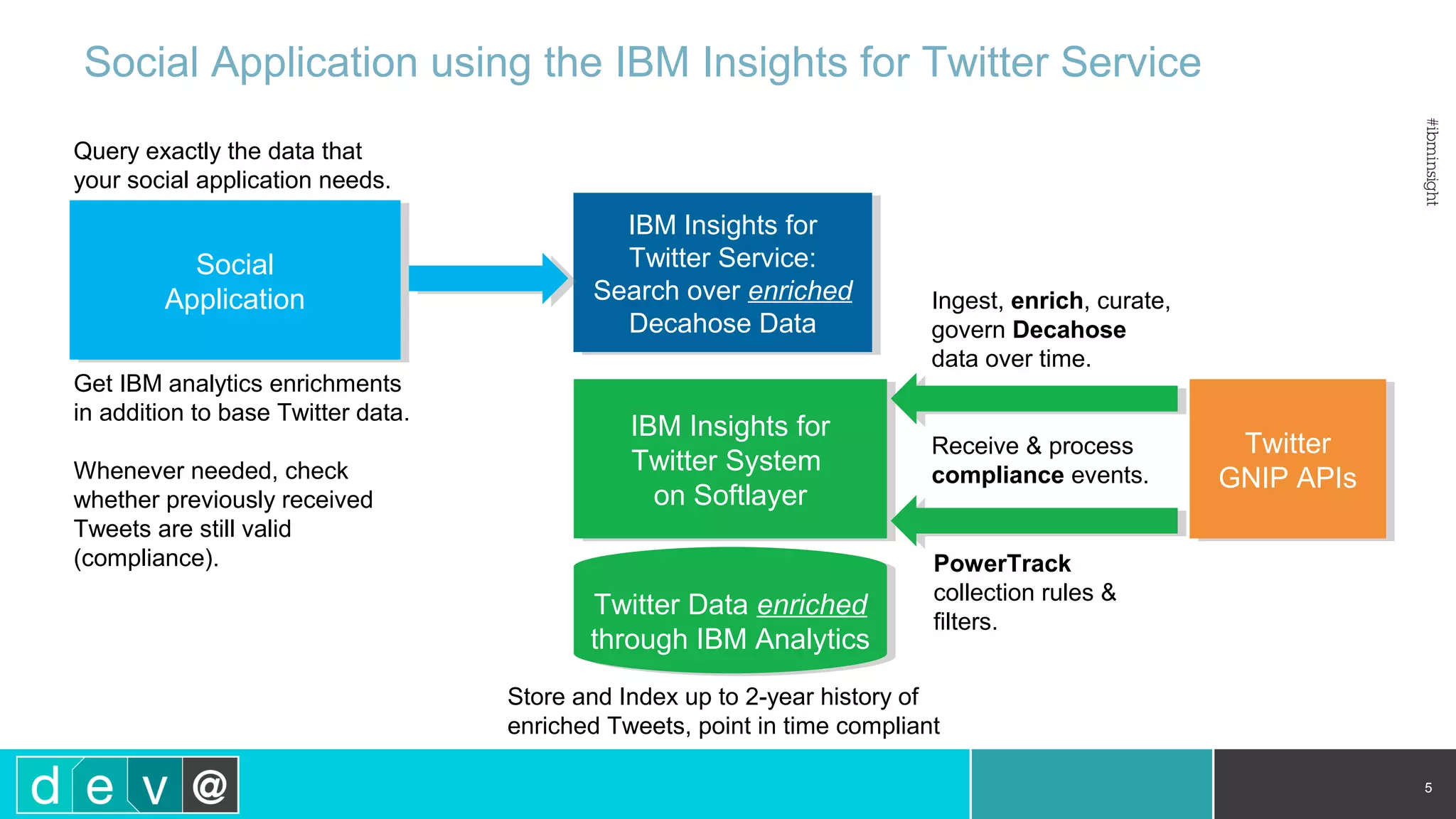
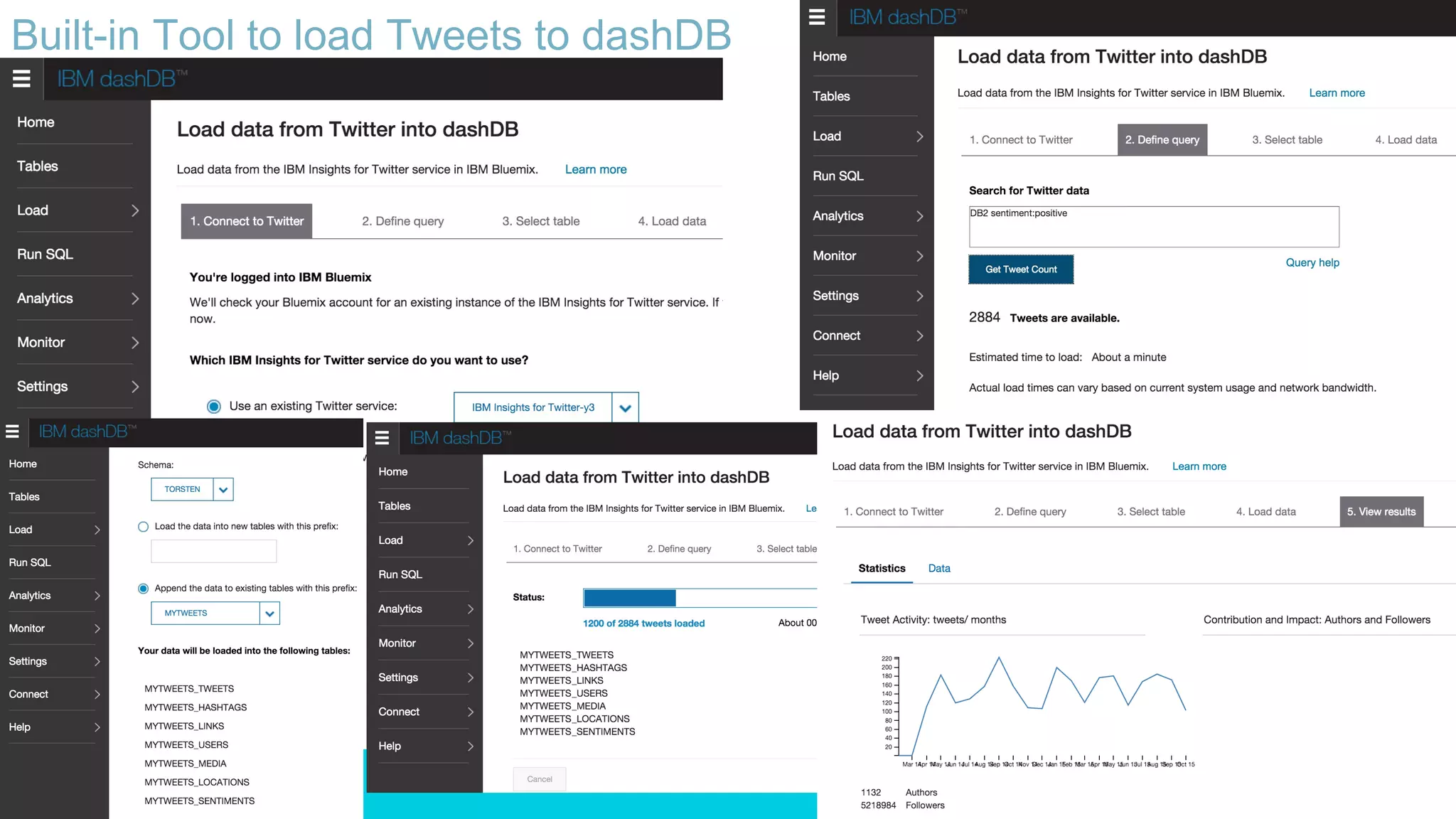
Using Bluemix and dashDB for Twitter Analysis This document discusses using IBM's Bluemix and dashDB services for Twitter analysis. It provides an overview of the IBM Insights for Twitter service in Bluemix, which allows querying and searching over enriched Twitter data stored in dashDB. Examples are given of queries that can be performed, such as searching for tweets about an upcoming movie within a time frame or searching for tweets with positive sentiment about a product. The document also discusses loading Twitter data into dashDB using a Bluemix app and performing predictive analytics on the data using built-in R and Python capabilities in dashDB.































































