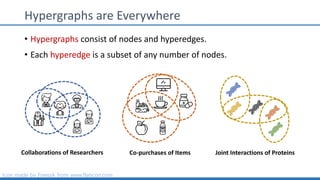
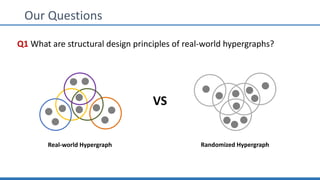
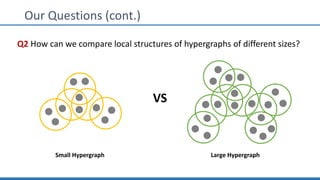
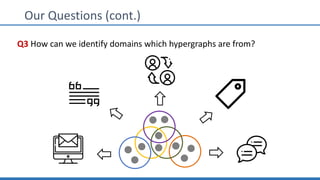
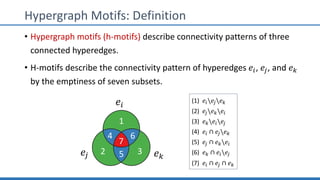
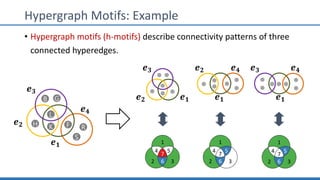
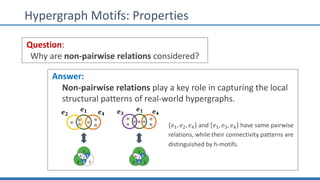
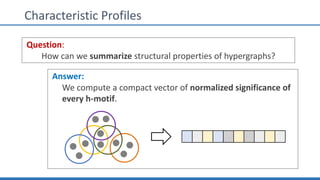
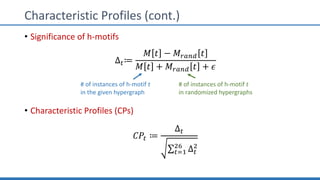
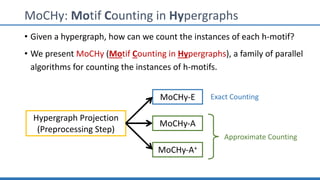
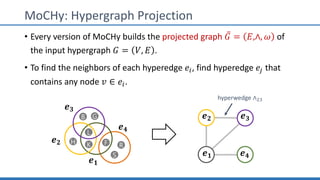
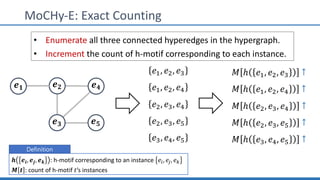
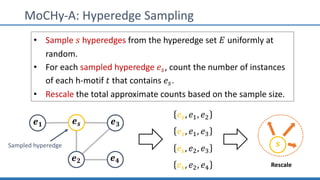
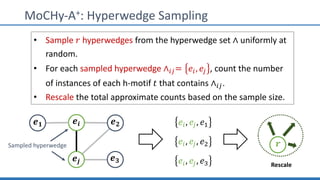
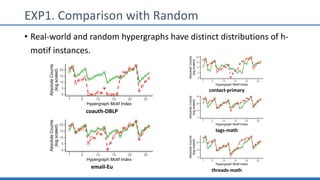
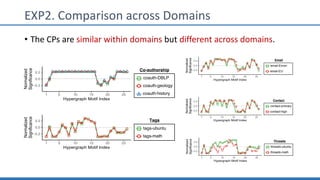
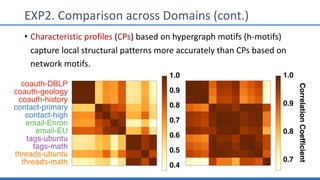
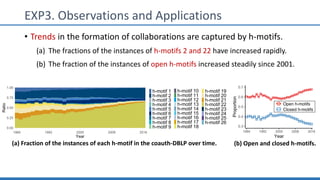
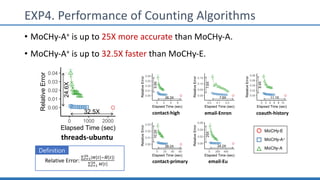
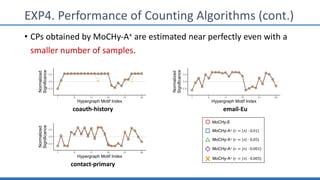
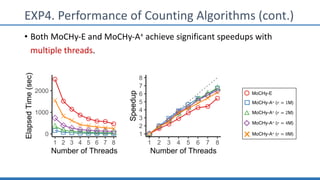
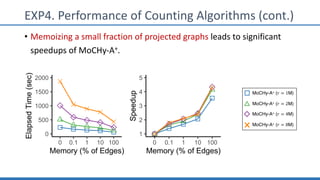
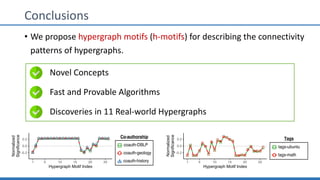
The document discusses hypergraph motifs, which describe connectivity patterns between three connected hyperedges in a hypergraph. It proposes MoCHy, a family of parallel algorithms for counting instances of hypergraph motifs in large hypergraphs. Experimental results on real-world hypergraphs from different domains show that their motif distributions differ significantly from randomized hypergraphs, and MoCHy can efficiently count motifs in large hypergraphs.












![Trial pahang 2014 spm add math k2 dan skema [scan]](https://cdn.slidesharecdn.com/ss_thumbnails/trialpahang2014spmaddmathk2danskemascan-141015101353-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)















![Trial terengganu 2014 spm add math k1 skema [scan]](https://cdn.slidesharecdn.com/ss_thumbnails/trialterengganu2014spmaddmathk1skemascan-141015101455-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)












![250915_Thanh_LabSeminar[HyperedgePrediction].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/250915thanhlabseminarhyperedgeprediction-250917140143-bcc6d5c5-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[DSC Europe 25] Gordana Milutinovic Dumbelovic - From Insight to Oversight: A...](https://cdn.slidesharecdn.com/ss_thumbnails/t7dkjsfxqwwzceropjv4-gordana-milutinovicdumbelovic-from-insight-to-oversight-ai-driven-power-bi-moni-260119121559-9e0bf11b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marcos Heidemann - Beyond the Hype: Making AI Coding Assistan...](https://cdn.slidesharecdn.com/ss_thumbnails/eexkhvldrjsopspdjbur-marcos-heidemann-beyond-the-hype-getting-real-value-out-of-ai-assisted-coding-260121115910-7e9d41ec-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dubravko Culibrk - Deep Learning for Mammography.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/yiscimuktacgqoiu4dkp-deep-learning-for-mammography-260119121559-aad59182-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milovan Jovicic - Beyond AI's Reach: The Enduring Value of Ev...](https://cdn.slidesharecdn.com/ss_thumbnails/pyeij0hurgwq5jugmtnv-2-milovan-jovicic-beyond-ais-reach-the-enduring-value-of-evergreen-design-v2-260120105856-d6ee57e5-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tali Fulman - Guild Meetings, Then What? Building Data Commun...](https://cdn.slidesharecdn.com/ss_thumbnails/fgohhi33rwmhqdowdj5k-tali-fulman-guild-meetings-then-what-building-data-communities-that-actually-ch-260120105855-528492c3-thumbnail.jpg?width=640&height=640&fit=bounds)




