Downloaded 74 times





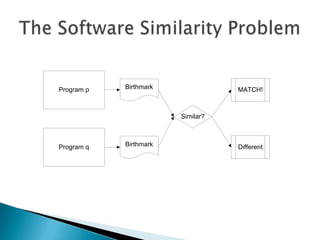

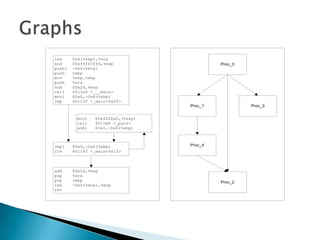


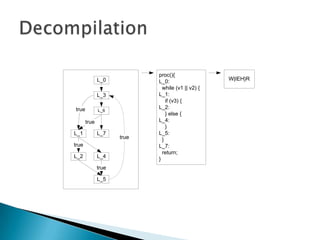








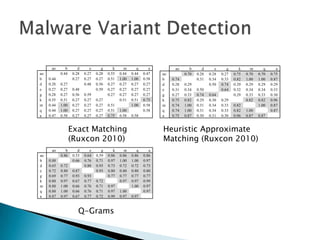




Silvio Cesare is a PhD candidate at Deakin University researching malware detection and automated vulnerability discovery. His current work extends his Masters research on fast automated unpacking and classification of malware. He presented this work last year at Ruxcon 2010. His system uses control flow graphs and q-grams of decompiled code as "birthmarks" to detect unknown malware samples that are suspiciously similar to known malware, reducing the need for signatures. He evaluated the system on 10,000 malware samples with only 10 false positives. The system provides improved effectiveness and efficiency over his previous work in 2010.






























































