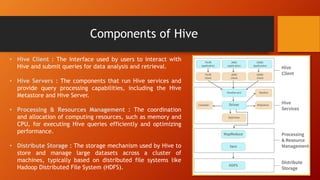
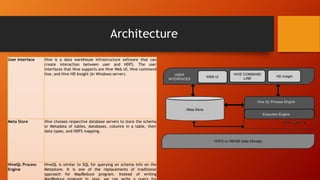
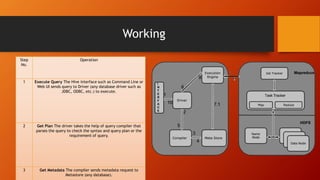
This document provides an introduction and overview of Hive, including its components, architecture, features, and working. Hive is a data warehouse infrastructure that uses SQL-like queries to analyze large datasets stored in Hadoop. It works by taking queries, compiling them into MapReduce jobs, and executing those jobs on a Hadoop cluster to process and retrieve data in a distributed manner. The document outlines Hive's client, servers, storage mechanisms, architecture involving interfaces, metastore, and query processing engine, as well as its key features like SQL support, scalability, and data formats. It concludes with a high-level description of Hive's query execution workflow.