
















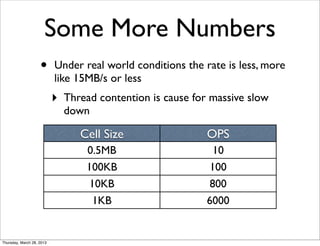






This document discusses sizing HBase clusters. It explains that HBase uses low-level resources like disk I/O, network I/O, threads, and memory, and that these resources are shared between reads and writes. It provides guidance on configuring memory sharing, optimizing reads and block caching, handling writes and flushes, avoiding compaction storms, and sizing example calculations. The document aims to help understand how HBase uses resources and configure it appropriately for different use cases.



















































































