Downloaded 16 times



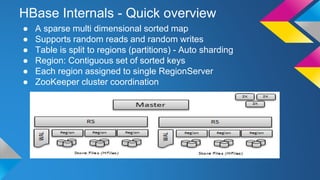
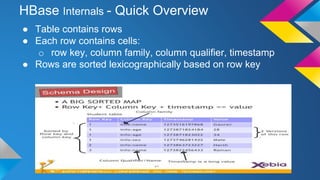
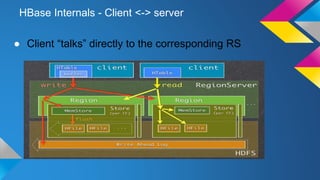




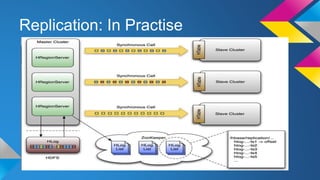













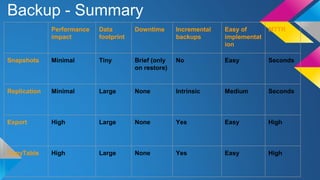













HBase Operations: Best Practices outlines key topics for operating HBase clusters effectively including replication for disaster recovery, backups using snapshots or export, monitoring systems, automation of deployments, hardware recommendations, and useful diagnostic tools. The document provides an overview of HBase internals and discusses solutions for common problems like total cluster failure or accidental data deletion through replication and backup strategies.















































