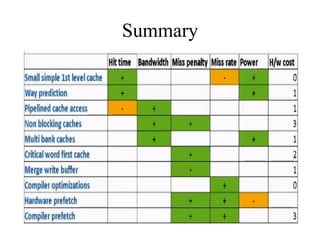
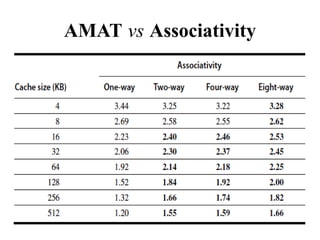
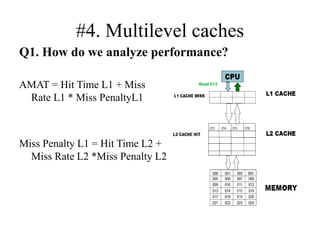
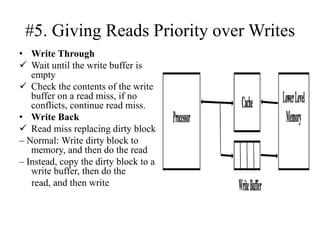
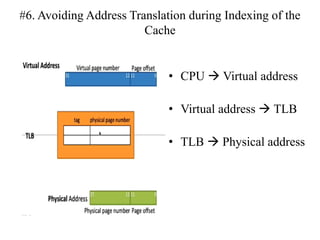
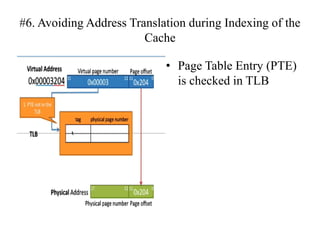
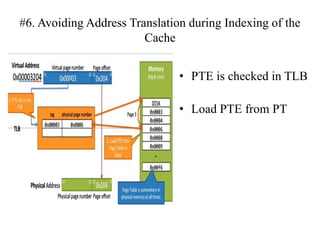
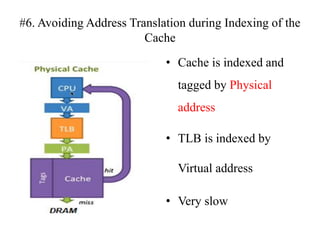
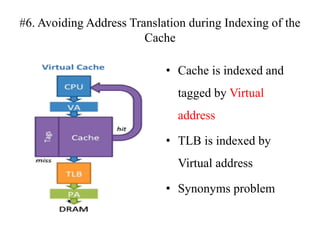
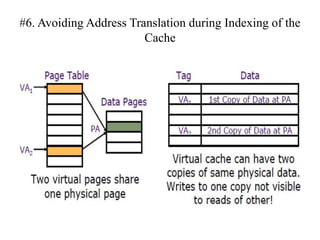
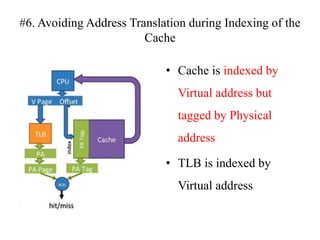
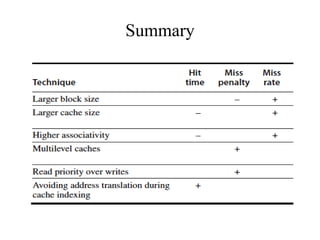
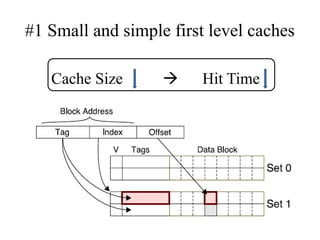
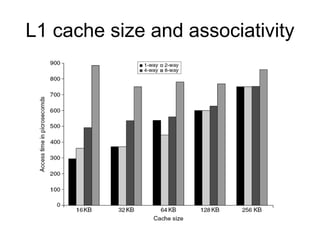
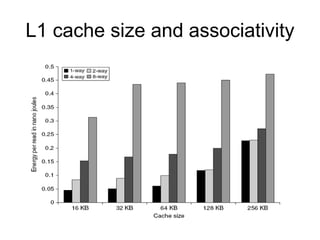
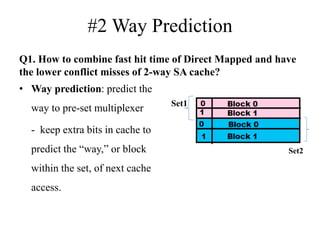
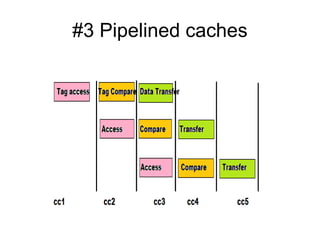
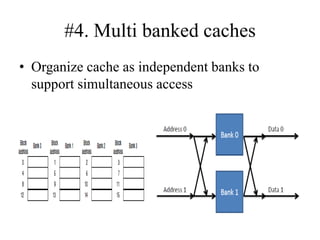
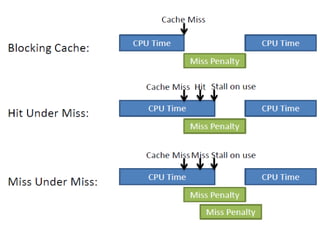
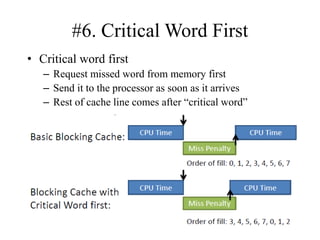
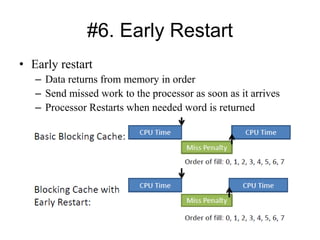
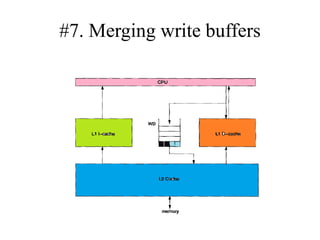
The document discusses cache optimizations, focusing on performance metrics such as hit time, miss rate, and miss penalty. It outlines strategies for improving cache performance, including increasing block size, cache size, and associativity, and implementing multilevel caches and read priority. Additionally, it delves into advanced techniques like pipelined caches, non-blocking caches, and compiler optimizations to enhance cache efficiency.























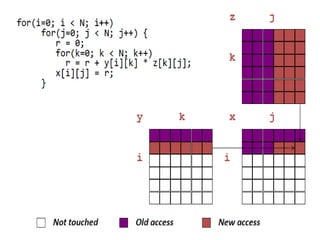
![Loop Interchange Example
/* Before */
for (j = 0; j < 3; j = j+1)
for (i = 0; i < 3; i = i+1)
x[i][j] = 2 * x[i][j];
/* After */
for (i = 0; i < 3; i = i+1)
for (j = 0; j < 3; j = j+1)
x[i][j] = 2 * x[i][j];
Sequential accesses instead of striding through memory every
word
What type of locality does this improves?](https://image.slidesharecdn.com/cacheoptimization-190312103513/85/Cache-optimization-47-320.jpg)

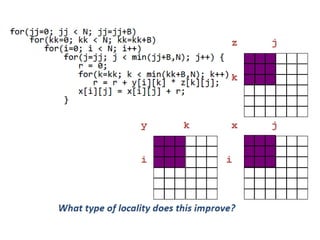
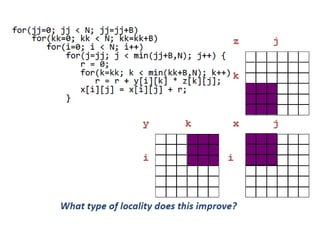
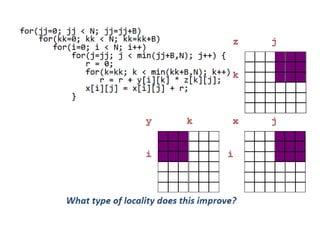
![50
Blocking
for (i = 0; i < N; i = i+1)
for (j = 0; j < N; j = j+1)
{r = 0;
for (k = 0; k < N; k = k+1){
r = r + y[i][k]*z[k][j];};
x[i][j] = r;
};
• Two inner loops:
– Read all NxN elements of z[]
– Read N elements of 1 row of y[] repeatedly
– Write N elements of 1 row of x[]](https://image.slidesharecdn.com/cacheoptimization-190312103513/85/Cache-optimization-49-320.jpg)

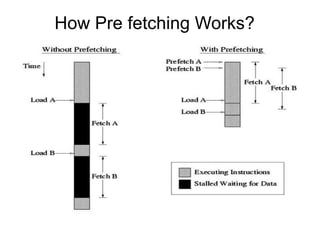


![#10. Compiler Controlled Pre fetch
• No prefetching
for (i = 0; i < N;
i++) {
sum += a[i]*b[i];
}
• Simple prefetching
for (i = 0; i < N;
i++) {
fetch (&a[i+1]);
fetch (&b[i+1]);
sum += a[i]*b[i];
}](https://image.slidesharecdn.com/cacheoptimization-190312103513/85/Cache-optimization-59-320.jpg)