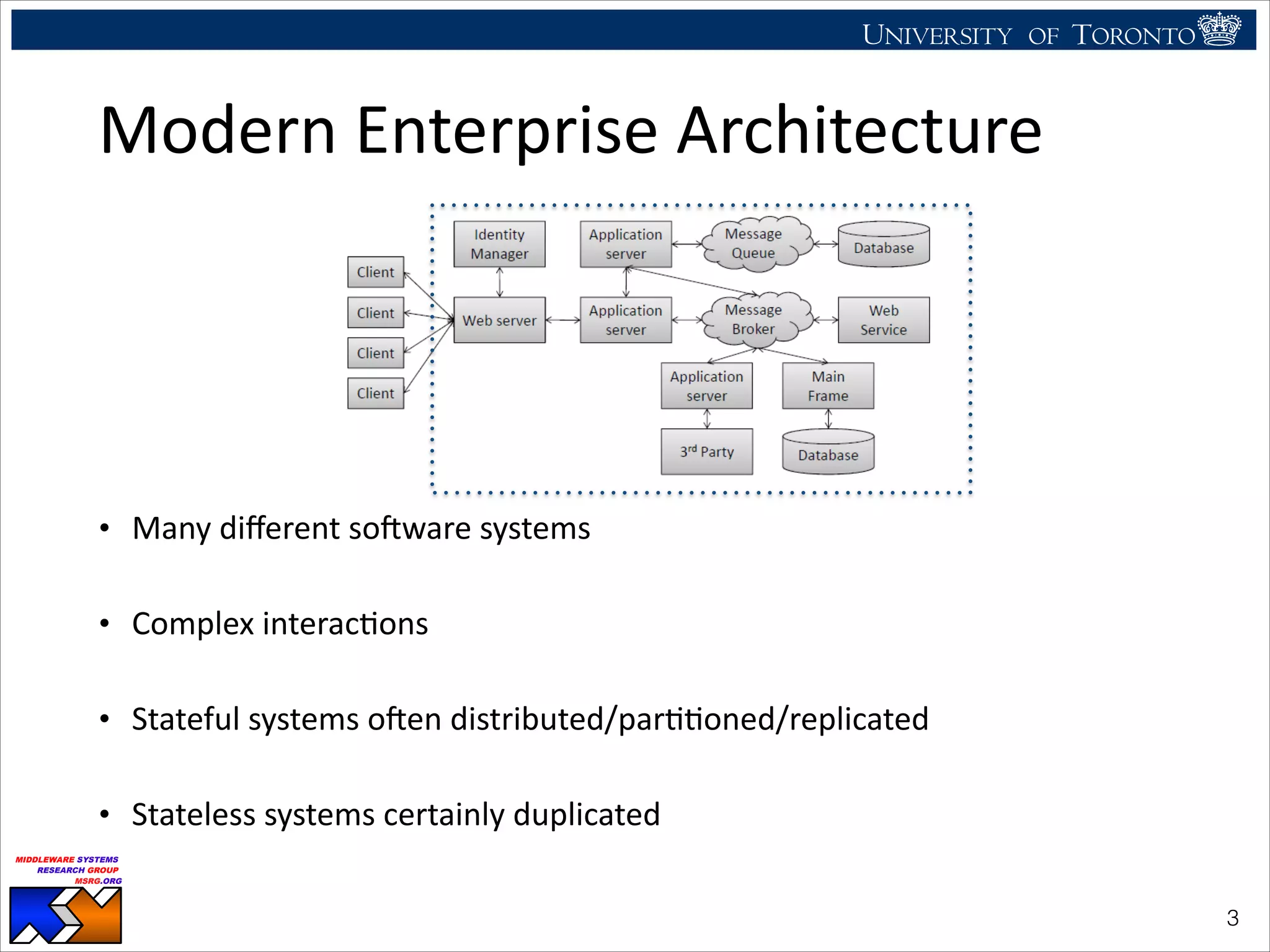
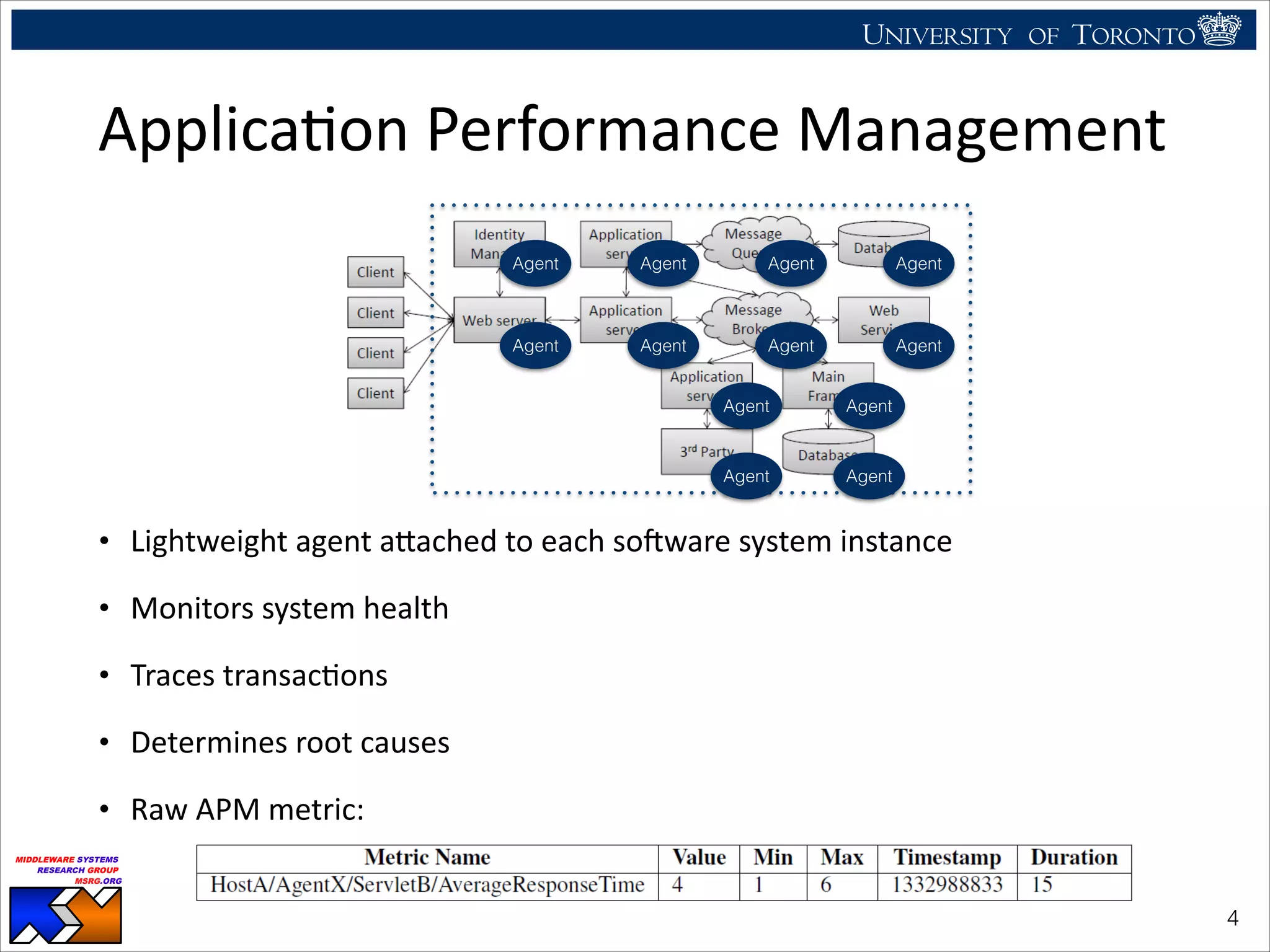
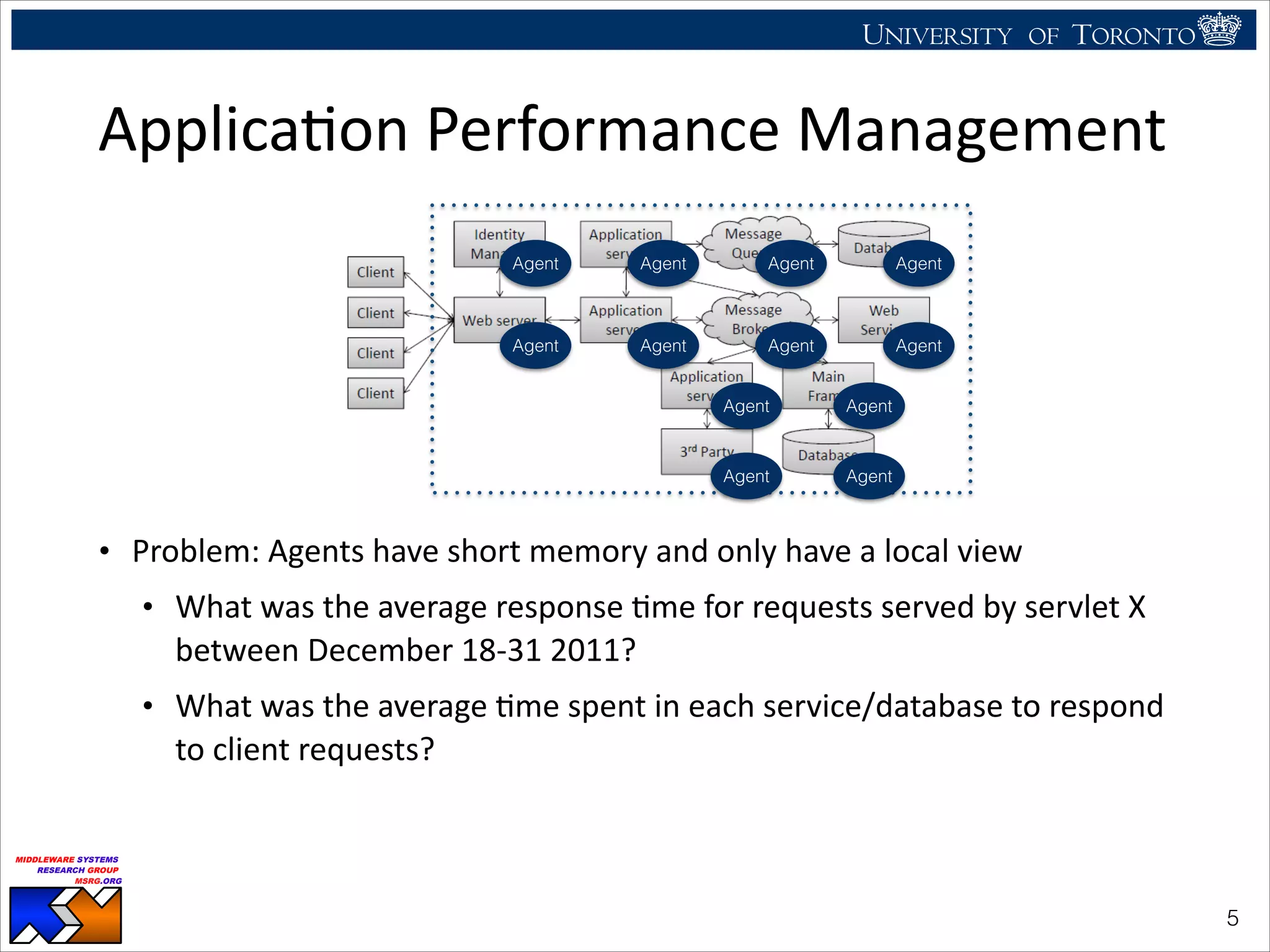
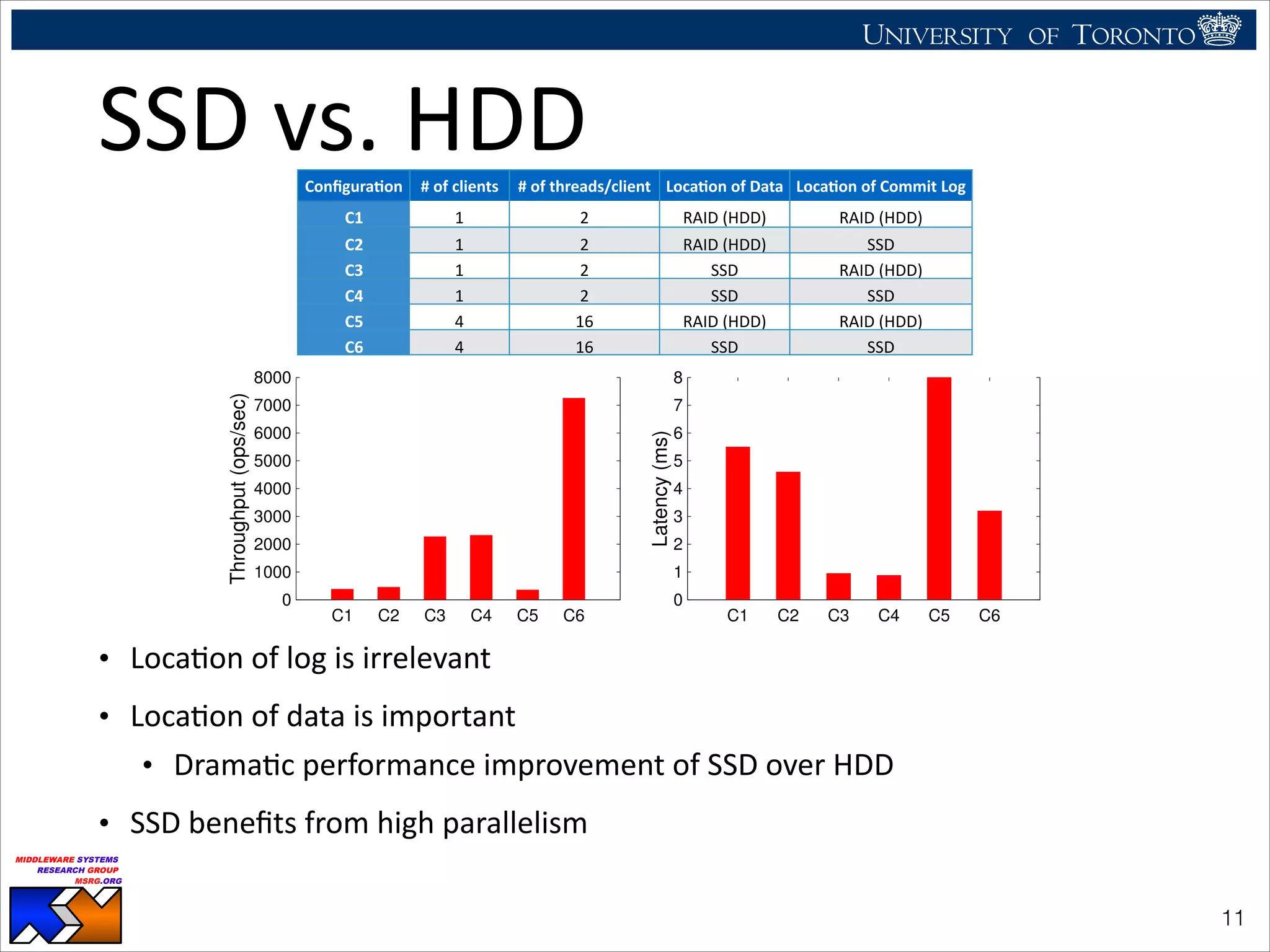
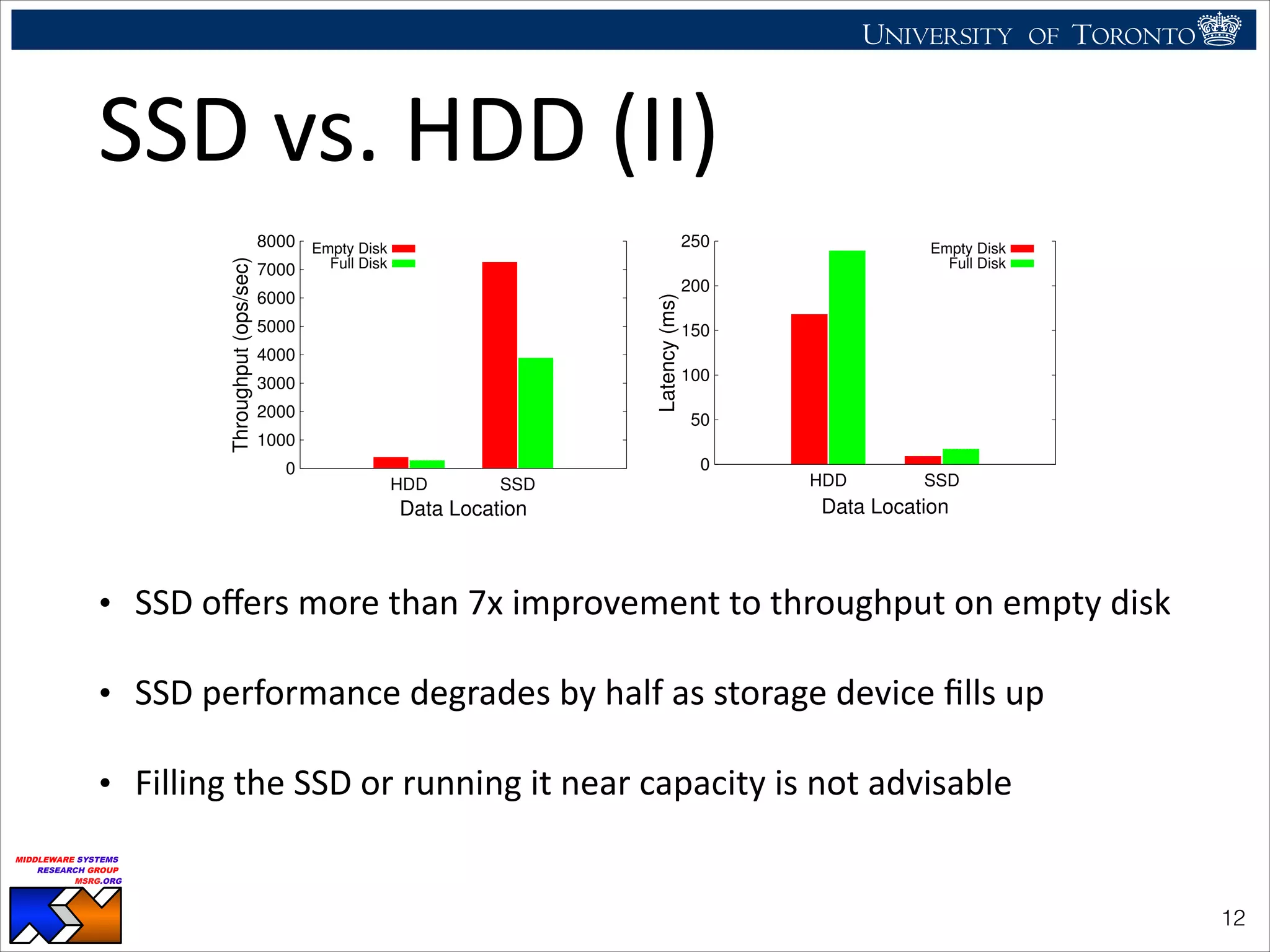
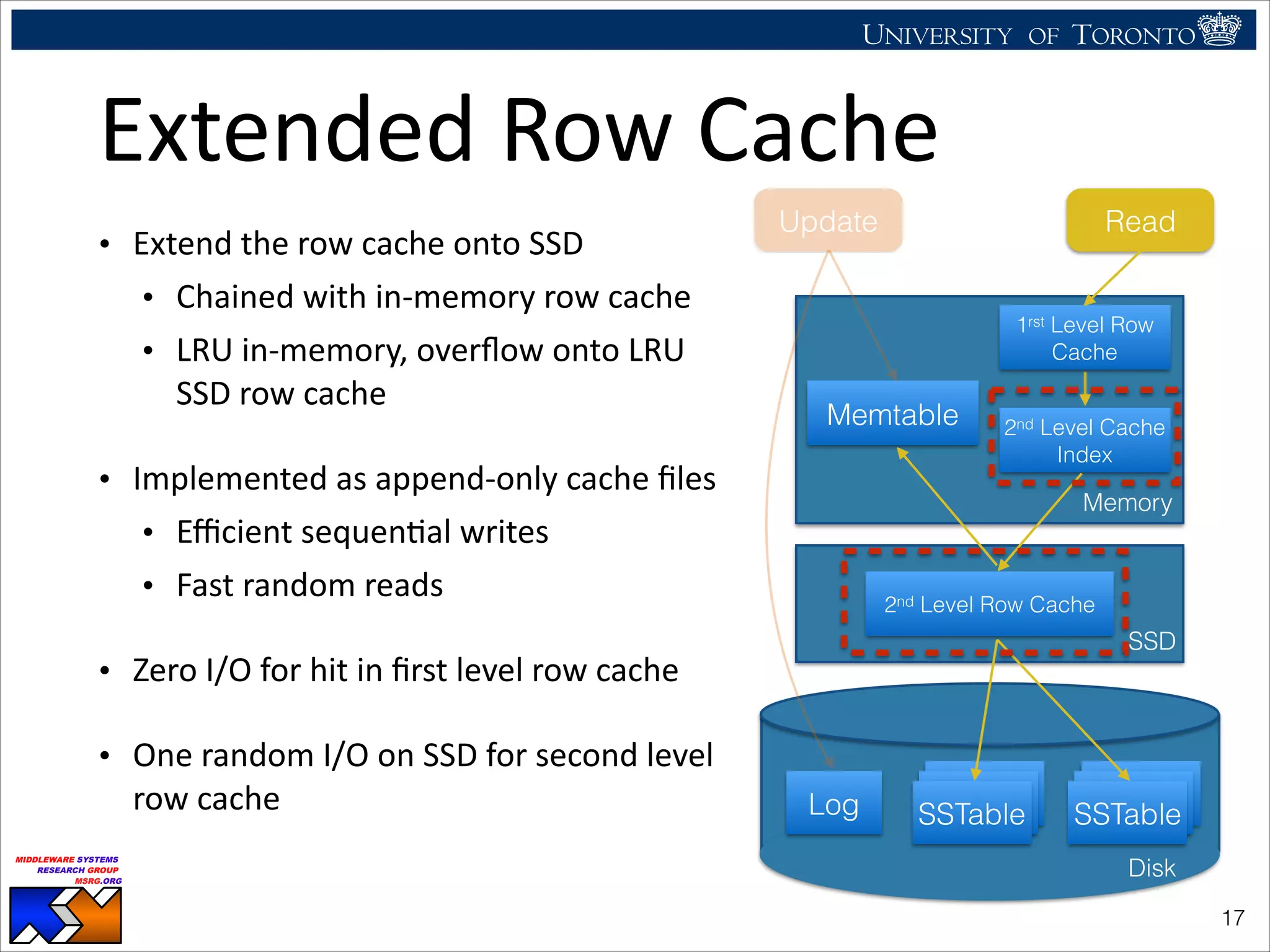
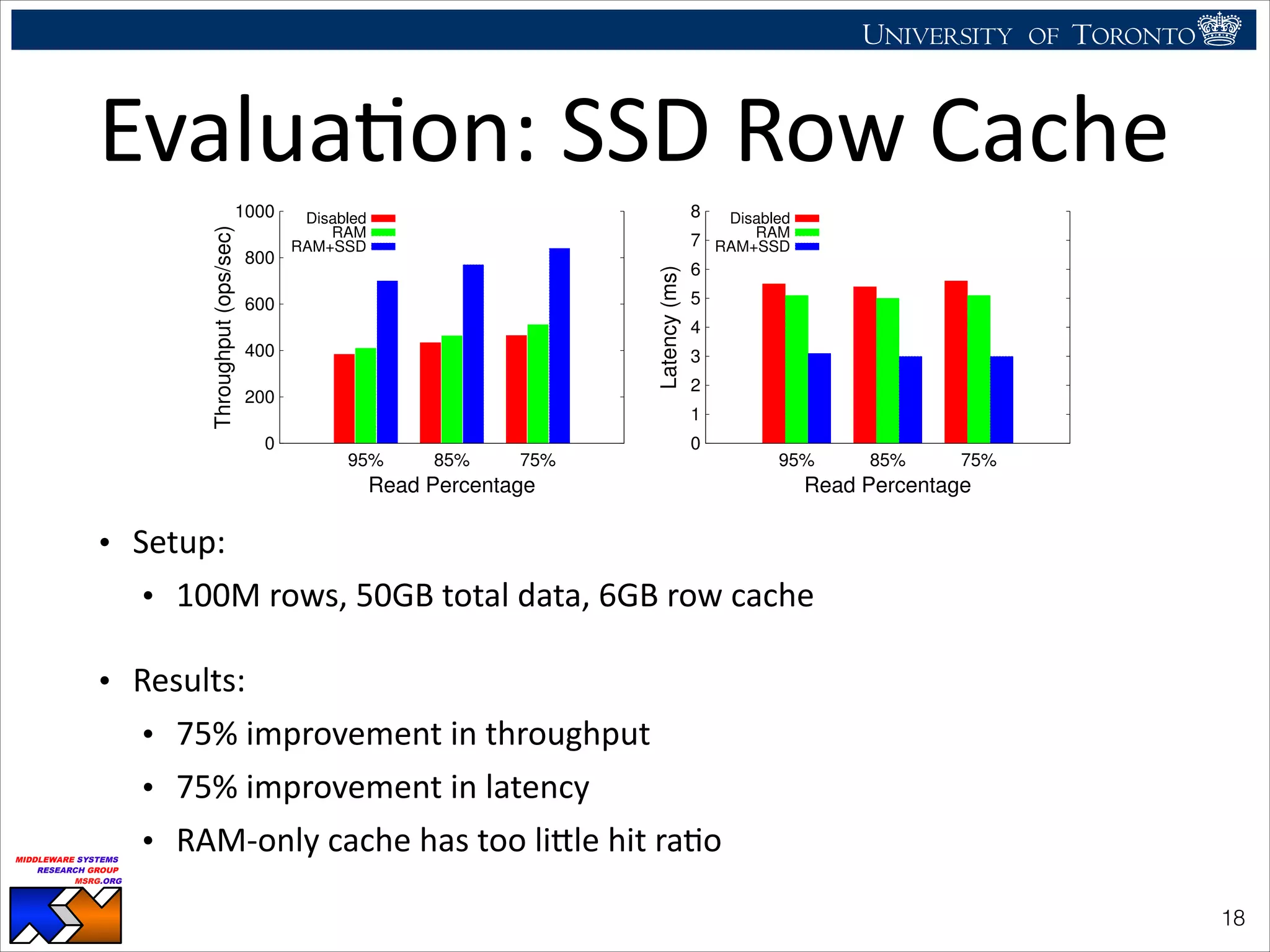
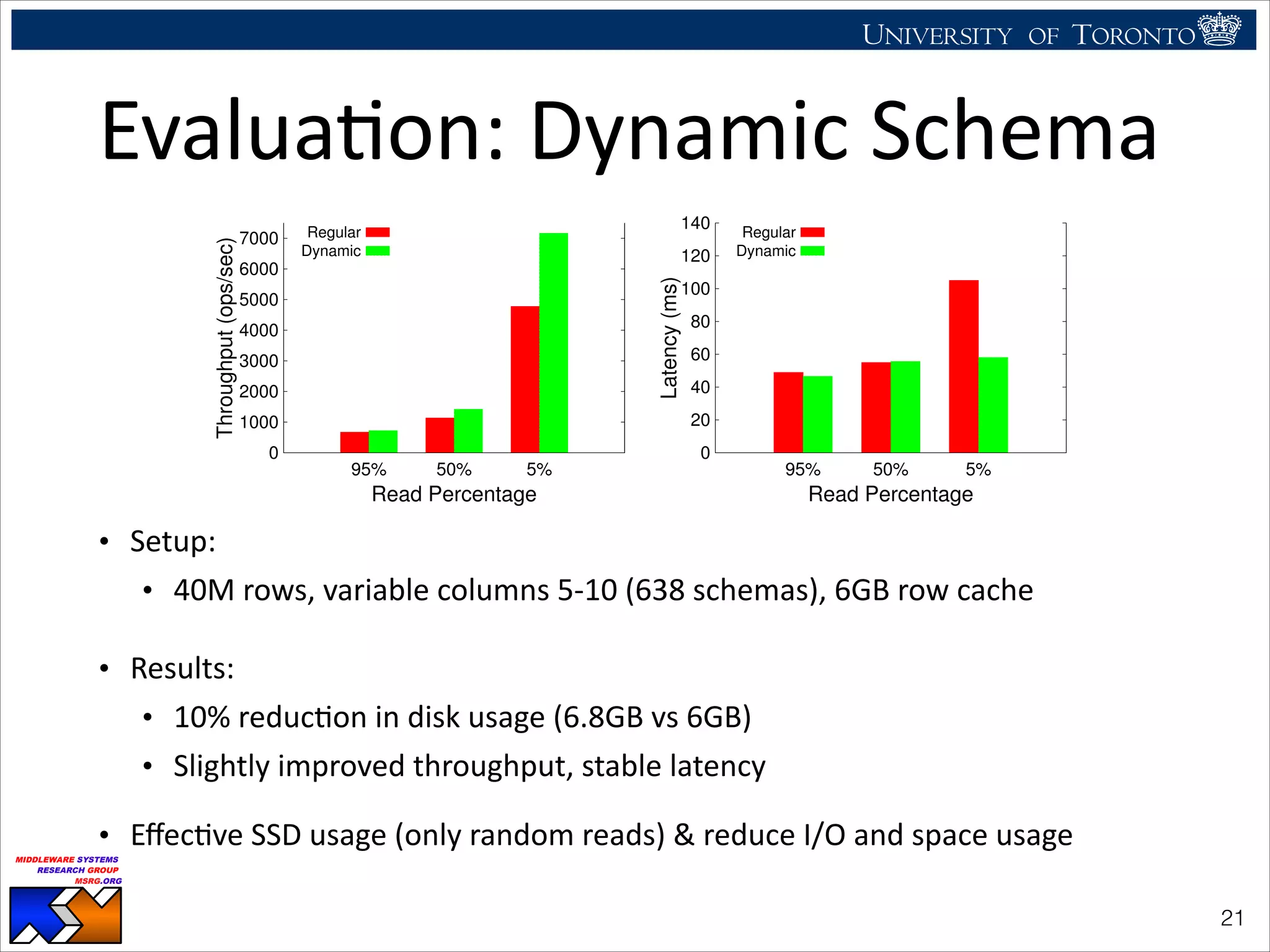
The document discusses the use of observability tools to enhance database management systems (DBMS), particularly focusing on Cassandra and its performance improvements when integrated with SSDs. It evaluates various configurations and metrics for application performance management, demonstrating how extending row cache onto SSD can significantly boost throughput and reduce latency. The findings suggest that while SSDs offer substantial performance benefits for data storage, careful configuration and management are necessary to optimize costs and lifespan.



![UNIVERSITY OF TORONTO
UNIVERSITY OF
TORONTO
Fighting back:
Using observability tools to improve
the DBMS (not just diagnose it)
Ryan Johnson
MIDDLEWARE SYSTEMS
RESEARCH GROUP
MSRG.ORG
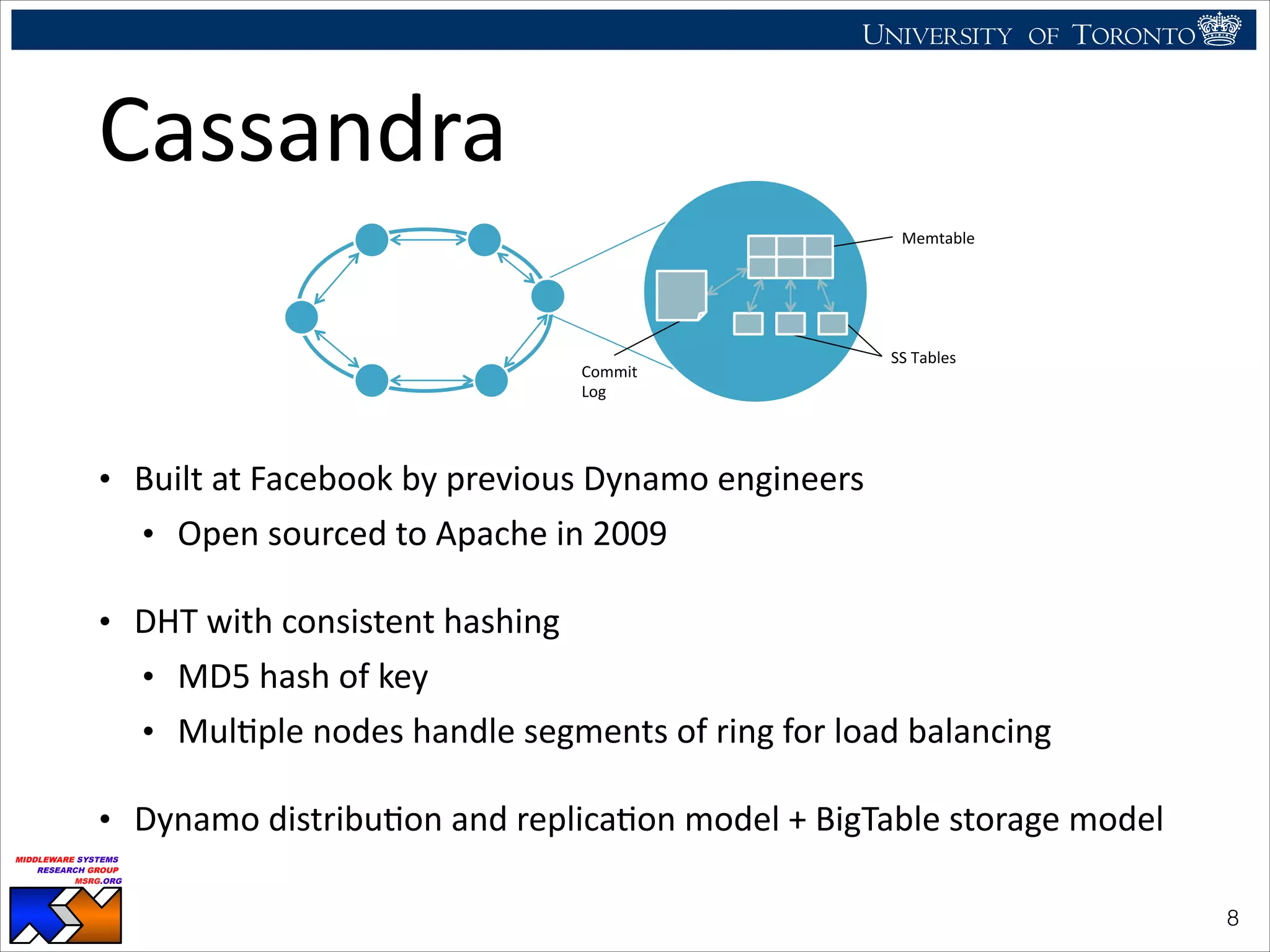
Cassandra
Wins
APM
• APM
experiments
performed
by
Rabl
et
al.
[1]
show
Cassandra
performs
best
for
APM
use
case
• In
memory
workloads
including
95%,
50%
and
5%
read
• Workloads
requiring
disk
access
with
95%,
50%
and
5%
reads
!7
Read: 95%
0
50000
100000
150000
200000
250000
2 4 6 8 10 12
Throughput(Ops/sec)
Number of Nodes
Cassandra
HBase
Voldemort
VoltDB
Redis
MySQL
Figure 6: Throughput for Workload RW
0.1
1
10
100
1000
2 4 6 8 10 12
Latency(ms)-Logarithmic
Number of Nodes
Cassandra
HBase
Voldemort
VoltDB
Redis
MySQL
Read: 50%
0
20000
40000
60000
80000
100000
120000
140000
160000
180000
2 4 6 8 10 12
Throughput(Operations/sec)
Number of Nodes
Cassandra
HBase
Voldemort
VoltDB
Redis
MySQL
Figure 3: Throughput for Workload R
million records per node, thus, scaling the problem size with the
cluster size. For each run, we used a freshly installed system and
loaded the data. We ran the workload for 10 minutes with max-
imum throughput. Figure 3 shows the maximum throughput for
workload R for all six systems.
In the experiment with only one node, Redis has the highest
throughput (more than 50K ops/sec) followed by VoltDB. There
are no significant differences between the throughput of Cassan-
dra and MySQL, which is about half that of Redis (25K ops/sec).
Voldemort is 2 times slower than Cassandra (with 12K ops/sec).
The slowest system in this test on a single node is HBase with 2.5K
operation per second. However, it is interesting to observe that the
0.1
1
10
100
2 4 6 8 10 12
Latency(ms)-Logarithmic
Number of Nodes
Cassandra
HBase
Voldemort
VoltDB
Redis
MySQL
Figure 4: Read latency for Workload R
0.01
0.1
1
10
100
2 4 6 8 10 12
Latency(ms)-Logarithmic
Number of Nodes
Cassandra
HBase
Voldemort
VoltDB
Redis
MySQL
Figure 5: Write latency for Workload R
[1] http://msrg.org/publications/pdf_files/2012/vldb12-bigdata-Solving_Big_Data_Challenges_fo.pdf](https://image.slidesharecdn.com/icde2014-cassandra-140526110404-phpapp02/75/CaSSanDra-An-SSD-Boosted-Key-Value-Store-7-2048.jpg)


![UNIVERSITY OF TORONTO
UNIVERSITY OF
TORONTO
Fighting back:
Using observability tools to improve
the DBMS (not just diagnose it)
Ryan Johnson
MIDDLEWARE SYSTEMS
RESEARCH GROUP
MSRG.ORG
SSD
vs.
HDD:
Summary
• Cassandra
benefits
most
when
storing
data
on
SSD
(not
the
log)
• LocaHon
of
commit
log
not
important
• SSD
performance
inversely
proporHonal
to
fill
raHo
• Storing
all
data
on
SSD
is
uneconomical
• Replacing
3TB
HDD
with
3x
1TB
SSD
is
10x
more
costly
• SSDs
have
limited
lifeHme
(10-‐50K
write-‐erase
cycles),
replacement
more
frequently
• Rabl
et
al.
[1]
show
adding
node
is
100%
costlier,
with
100%
throughput
improvement
• Build
hybrid
system
to
get
comparable
performance
for
marginal
cost
!13](https://image.slidesharecdn.com/icde2014-cassandra-140526110404-phpapp02/75/CaSSanDra-An-SSD-Boosted-Key-Value-Store-13-2048.jpg)
































































![[db tech showcase Tokyo 2018] #dbts2018 #B17 『オラクル パフォーマンス チューニング - 神話、伝説と解決策』](https://cdn.slidesharecdn.com/ss_thumbnails/dbts2018b17dellemc-181002065554-thumbnail.jpg?width=640&height=640&fit=bounds)





























