



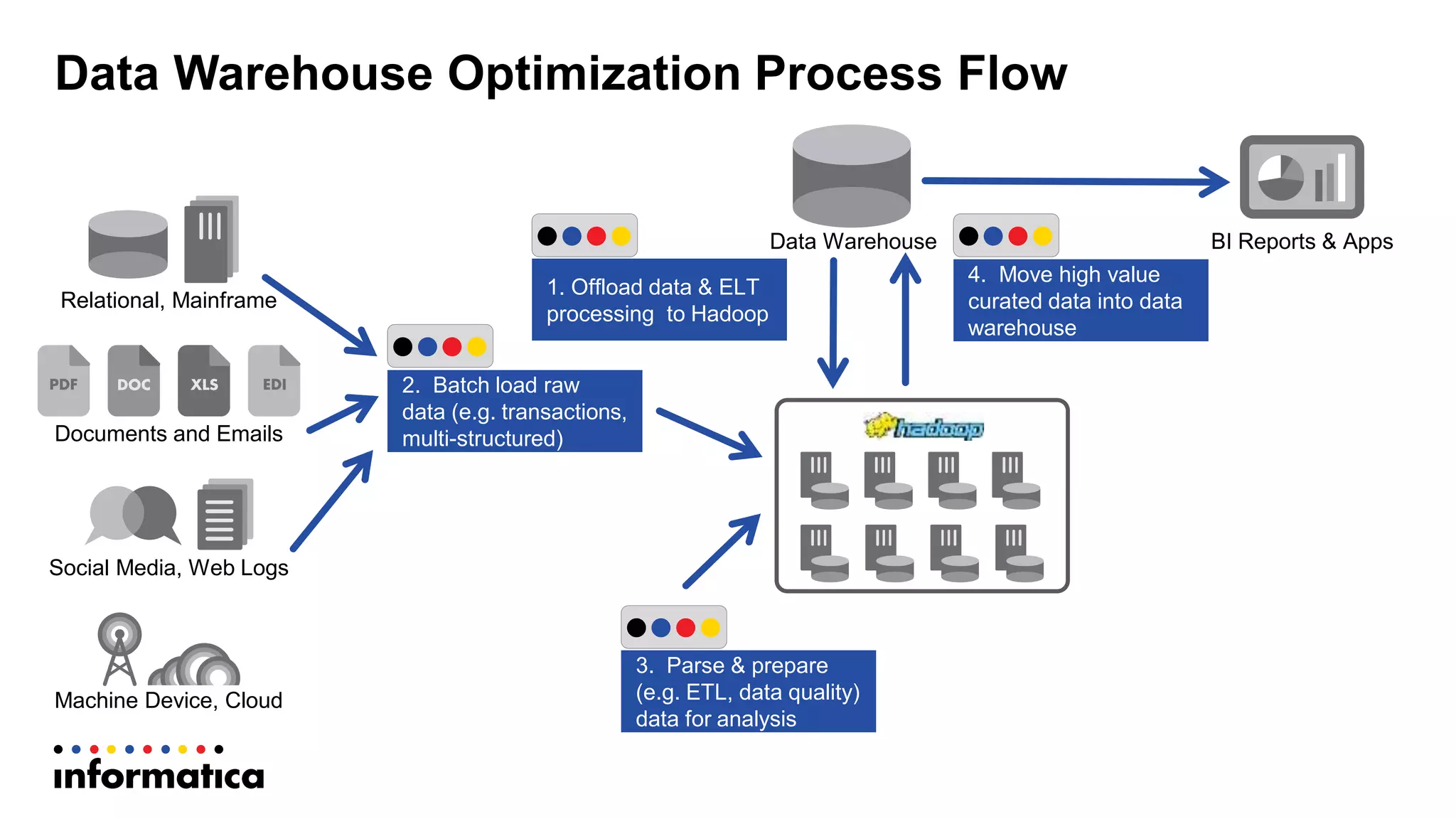


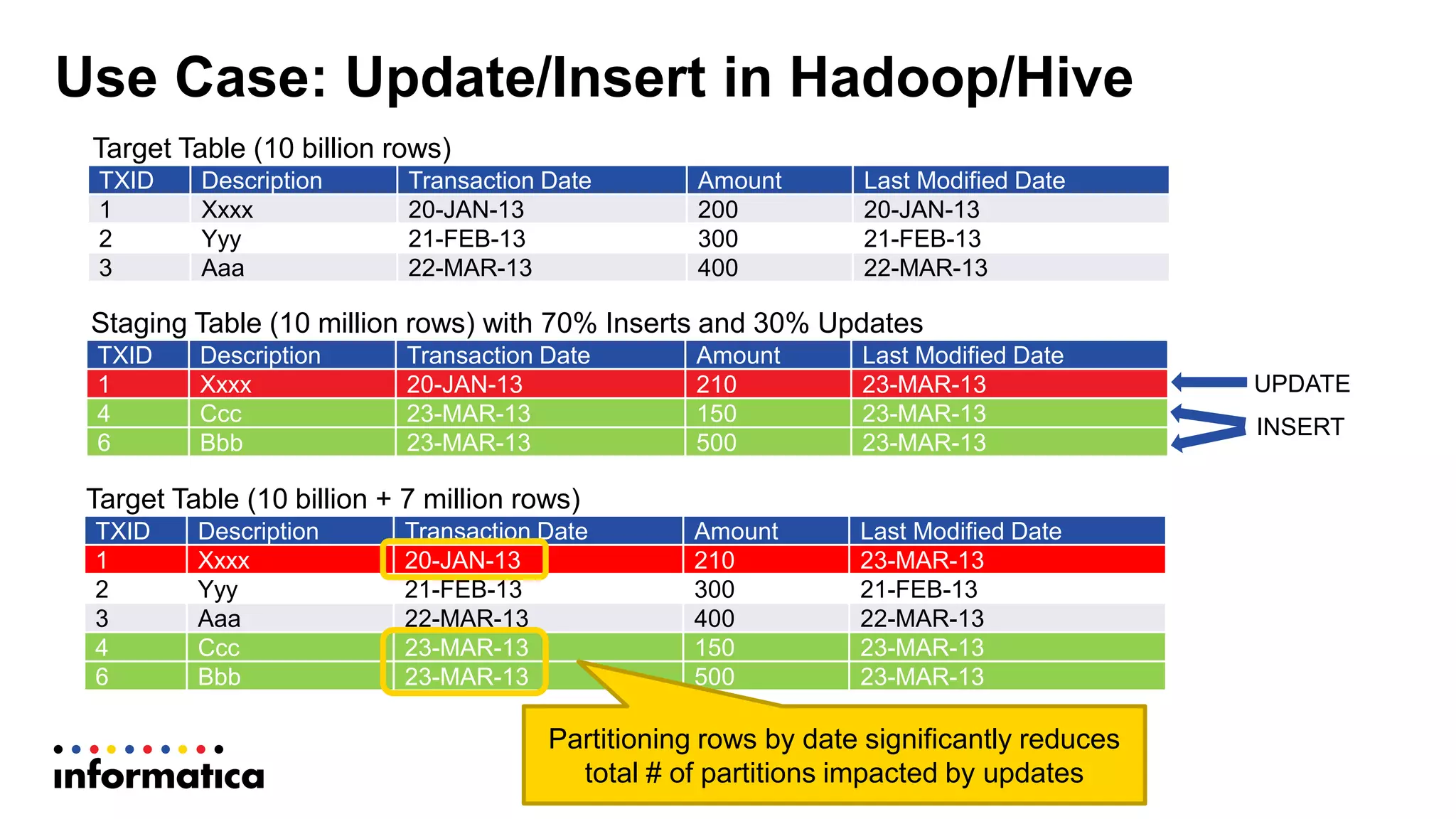
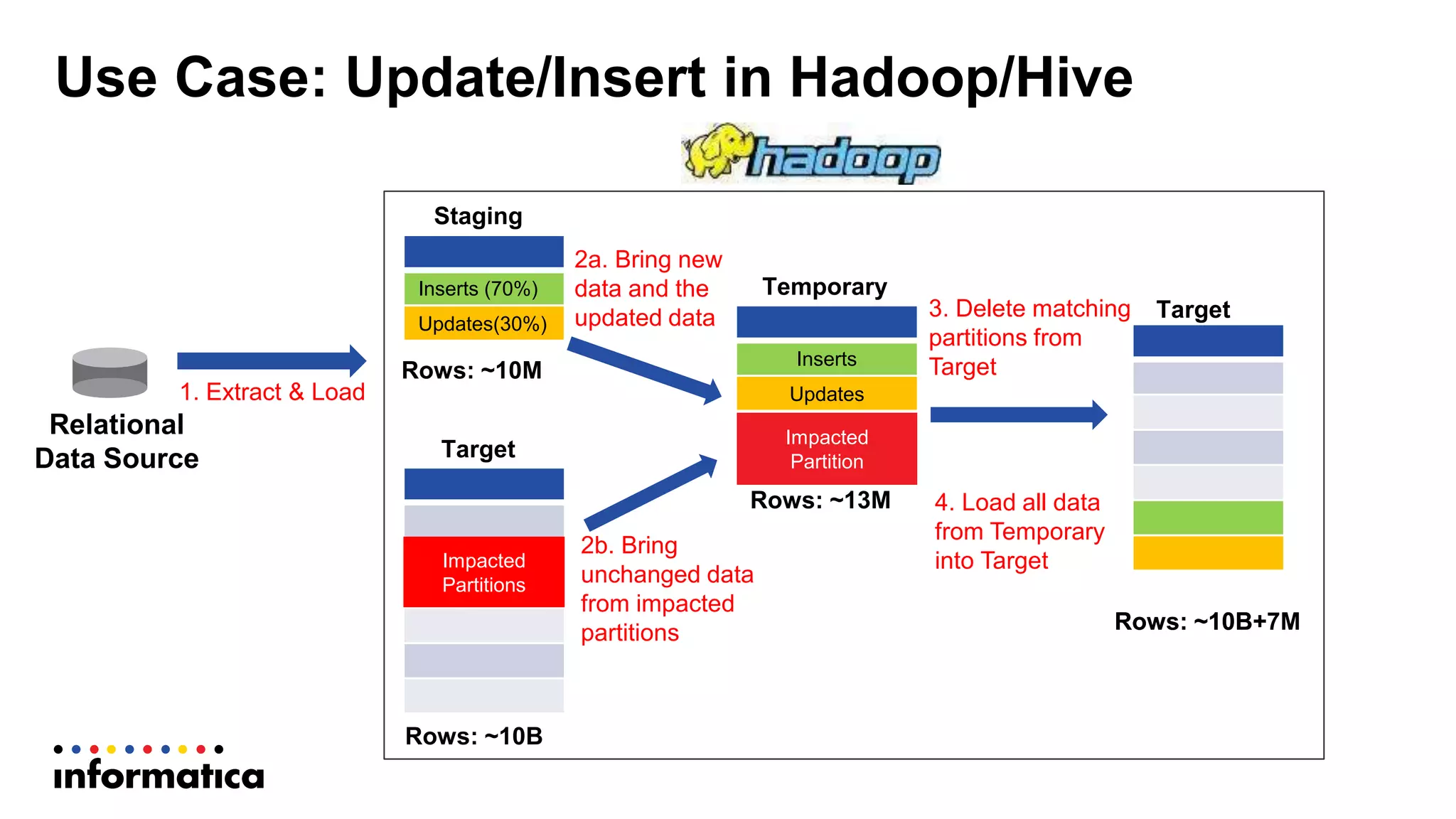

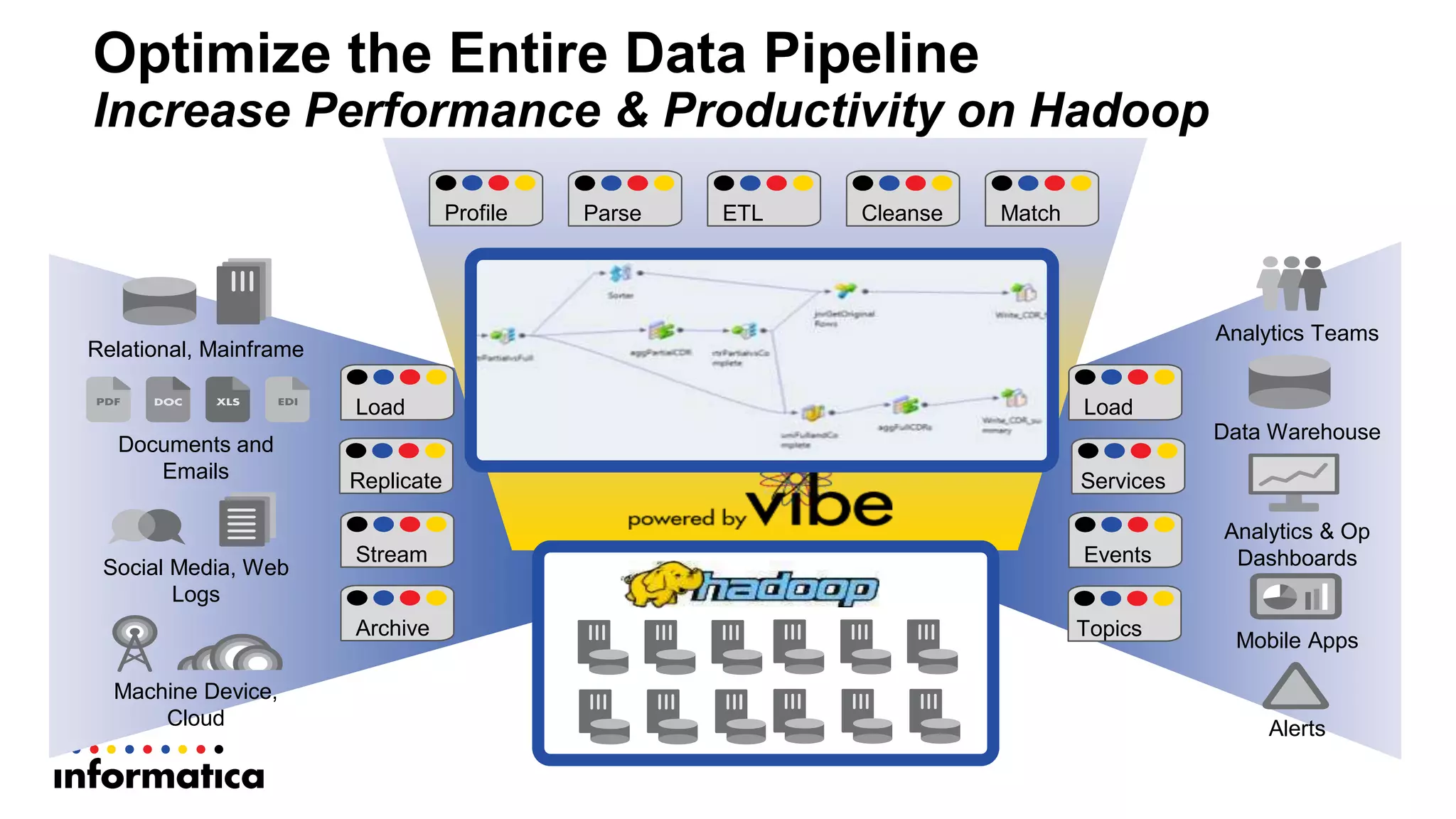



This document discusses optimizing a data warehouse by using Hadoop to handle large and changing datasets more efficiently. It outlines challenges with traditional data warehousing as data volumes grow. Requirements for an optimized solution include unlimited scalability, handling all data types, and supporting agile methodologies. The document then describes a process flow for offloading ELT and loading to Hadoop. It provides an example use case of updating large datasets on Hadoop more efficiently using partitioning and temporary tables to minimize impact. A demo is referenced to illustrate the approach.

































































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)








