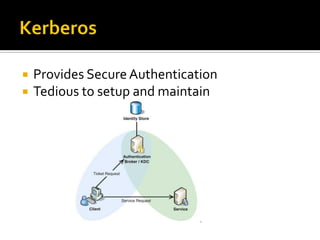
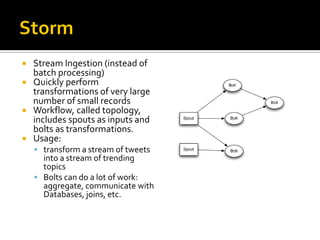
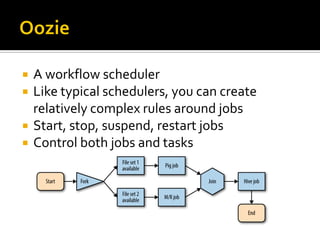
This document provides an overview of various Hadoop ecosystem technologies, including core Hadoop components like HDFS, MapReduce, YARN and Spark. It also summarizes other related big data technologies for data processing, security, ETL, monitoring, databases, machine learning and graph processing that commonly work with Hadoop.