Download as PDF, PPTX

















![idBigData.com IDBigData idBigData @idBigData hub.idBigData.com
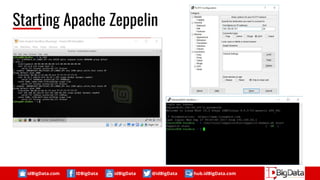
Know Your Data
Data Format : text file that contain 10 fields and separated by space for each field
remotehost rfc931 authuser [date] "request" status size referer agent tcp_code
Field Description :
1. Remotehost
Remote hostname (or IP number if DNS hostname is not
available, or if DNSLookup is Off.
2. Rfc931
The remote logname of the user.
3. User ID
The username as which the user has authenticated himself.
Always NULL ("-") for Squid logs.
4. [date]
Date and time of the request.
5. "Request"
The request line exactly as it came from the client. GET,
HEAD, POST, etc. for HTTP requests. ICP_QUERY for ICP
requests.
6. Status
The HTTP status code returned to the client. See the HTTP
status codes for a complete list.
7. Size
The content-length of data transferred in byte.
8. Referer
9. Agent
Application that access the internet
10. TCP Code
The ``cache result'' of the request. This describes if the
request was a cache hit or miss, and if the object was
refreshed](https://image.slidesharecdn.com/opensourcesolutionfordataanalystworkflow-1-170930160724/85/Open-Source-Solution-for-Data-Analyst-Workflow-17-320.jpg)
![idBigData.com IDBigData idBigData @idBigData hub.idBigData.com
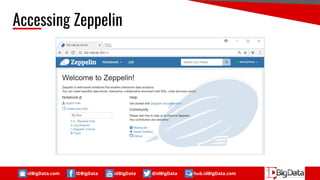
Know Your Data
Sample Data :
192.168.6.129 - - [17/Sep/2017:00:00:21 +0700] "GET
http://api.account.xiaomi.com/pass/v2/safe/user/coreInfo? HTTP/1.1" 200 862 "-"
"Dalvik/2.1.0 (Linux; U; Android 5.1.1; 2014817 MIUI/V8.5.1.0.LHJMIED)" TCP_MISS:DIRECT
192.168.6.103 - - [17/Sep/2017:00:01:14 +0700] "POST http://netmarbleslog.netmarble.com/
HTTP/1.0" 200 299 "-" "okhttp/2.5.0" TCP_MISS:DIRECT
Remotehost : 192.168.129
[date] : [17/Sep/2017:00:00:21 +0700]
"Request" :
"GET http://api.account.xiaomi.com/pass/v2/safe/user/coreInfo? HTTP/1.1"
Status : 200
Size : 862
Agent :
"Dalvik/2.1.0 (Linux; U; Android 5.1.1; 2014817 MIUI/V8.5.1.0.LHJMIED)"
TCP Code : TCP_MISS:DIRECT](https://image.slidesharecdn.com/opensourcesolutionfordataanalystworkflow-1-170930160724/85/Open-Source-Solution-for-Data-Analyst-Workflow-18-320.jpg)
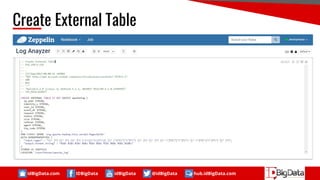
![idBigData.com IDBigData idBigData @idBigData hub.idBigData.com
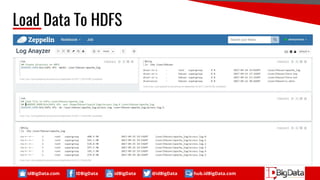
RegexSerDe
Sample Data :
192.168.6.129 - - [17/Sep/2017:00:00:21 +0700] "GET
http://api.account.xiaomi.com/pass/v2/safe/user/coreInfo? HTTP/1.1" 200 862 "-"
"Dalvik/2.1.0 (Linux; U; Android 5.1.1; 2014817 MIUI/V8.5.1.0.LHJMIED)" TCP_MISS:DIRECT](https://image.slidesharecdn.com/opensourcesolutionfordataanalystworkflow-1-170930160724/85/Open-Source-Solution-for-Data-Analyst-Workflow-24-320.jpg)
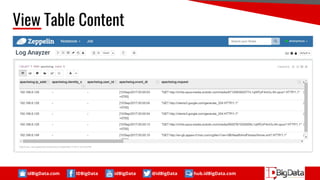
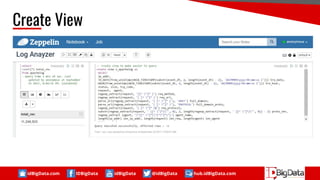
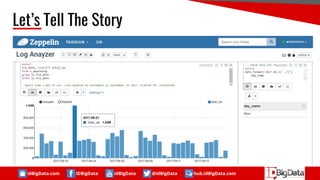
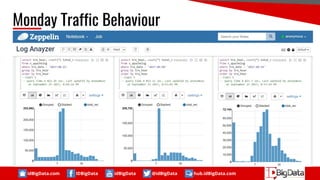
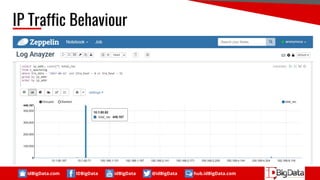
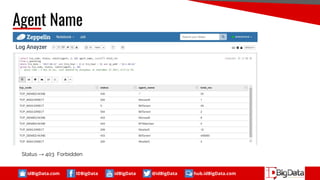
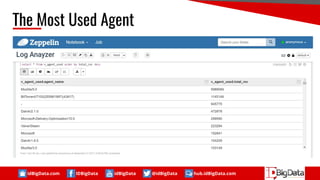


This document summarizes a presentation about using SQL for big data analytics. It discusses how SQL can be used on Hadoop systems to analyze large datasets. It then demonstrates loading squid web access log data into an Apache Hive database on Hadoop and performing queries to analyze traffic patterns and popular browsers. The presentation shows how SQL provides an accessible way for analysts to explore and gain insights from big data.



































































