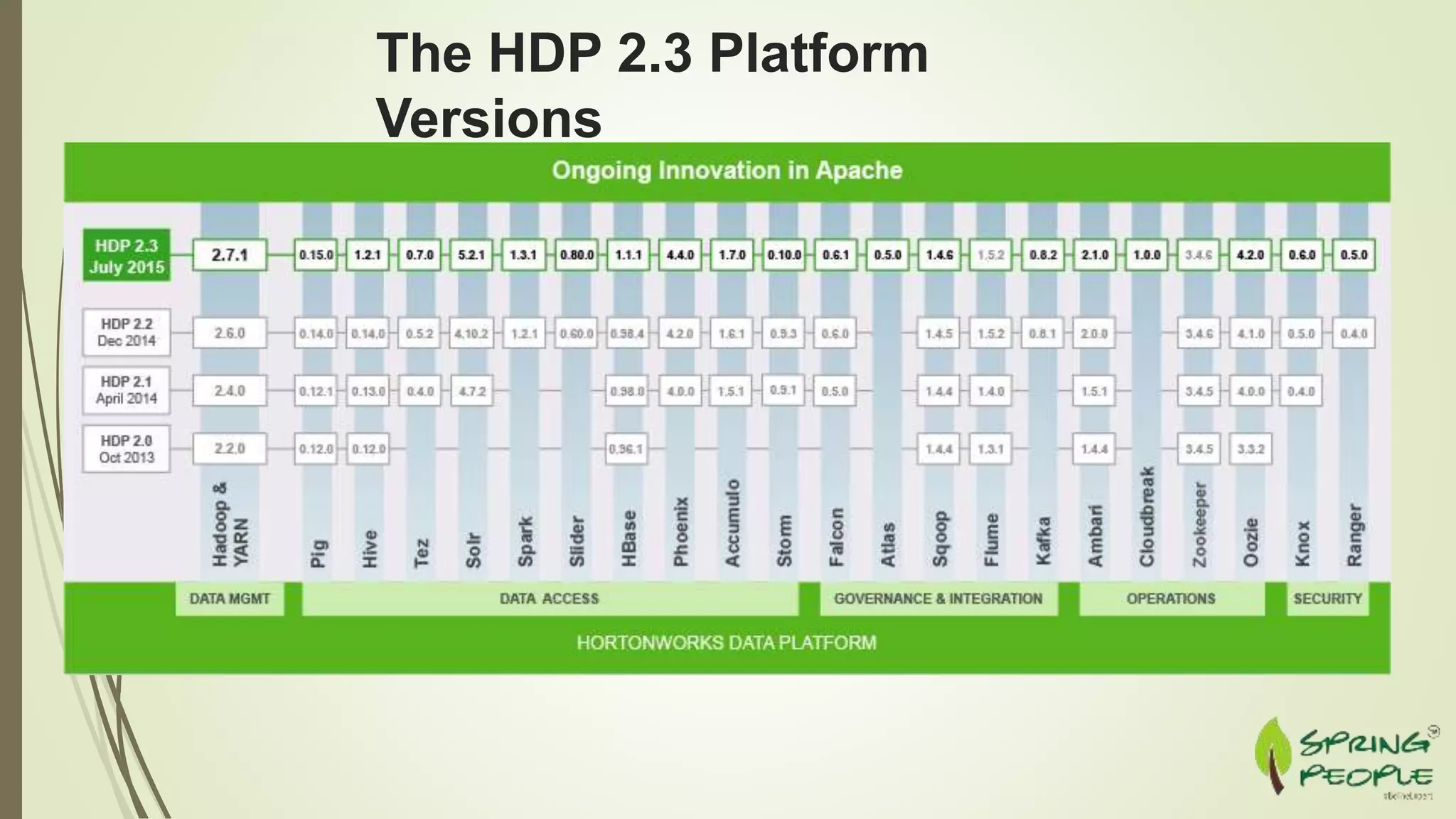
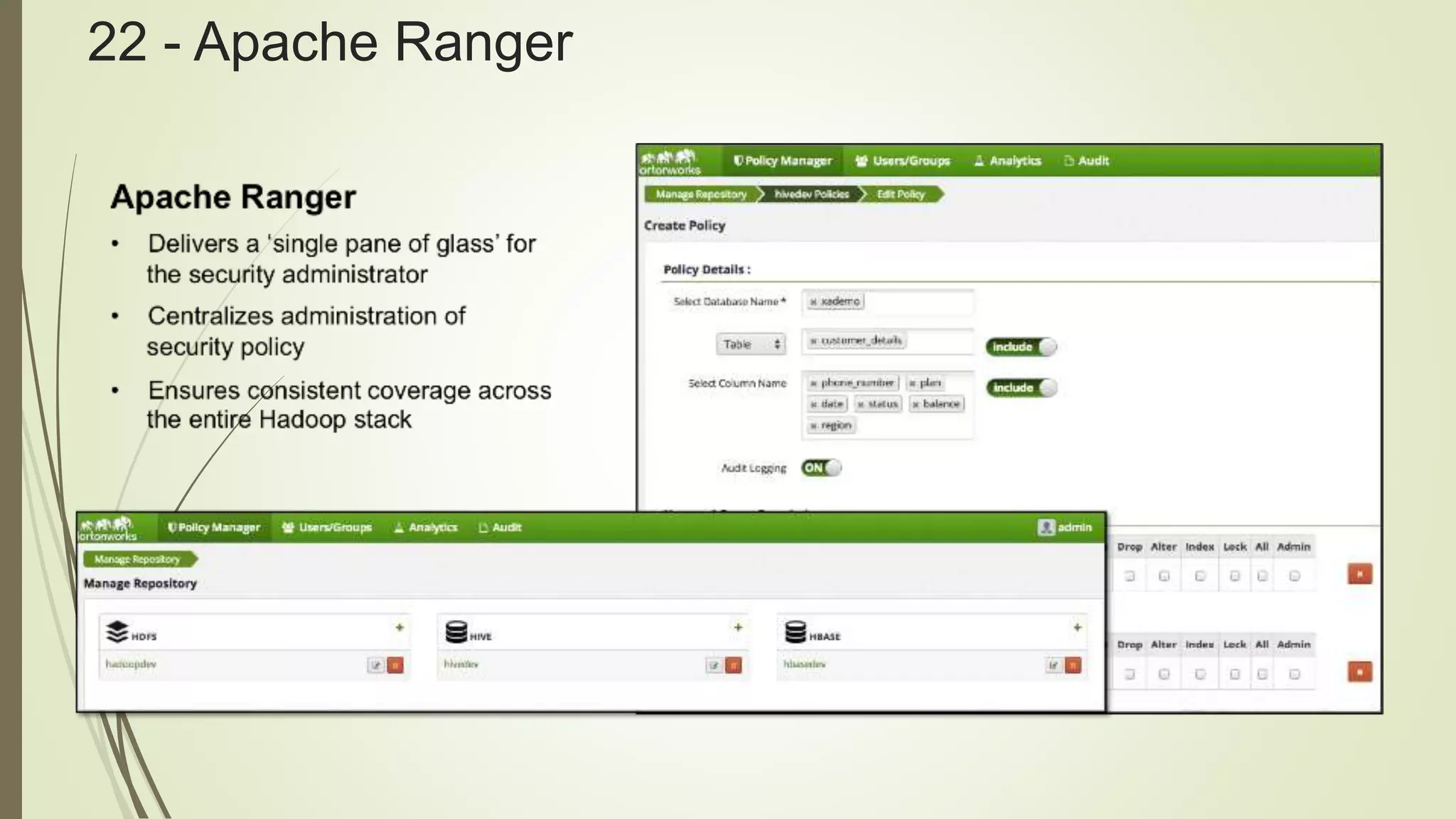
Downloaded 13 times











![19 - Running Balancer
• Can be run periodically as a batch job
• Examples: every 24 hours or weekly
• Run after new nodes have been added to the cluster
• To run balancer:
hdfs balancer [-threshold <threshold>] [-policy <policy>]]
• Runs until there are no blocks to move
or
Until it has lost contact with the NameNode
• Can be stopped with a Ctrl+C](https://image.slidesharecdn.com/hadoopadminbestpracticespart2-160812144002/75/Best-Practices-for-Administering-Hadoop-with-Hortonworks-Data-Platform-HDP-2-3-_Part-2-13-2048.jpg)





The document outlines best practices for Hadoop administration using HDP 2.3, including features of the Hadoop ecosystem, such as Ambari for cluster management and YARN components. It also covers topics like HDFS configurations, data compression tradeoffs, Sqoop security measures, and automating backups with Falcon and Oozie. Additionally, it promotes upcoming training sessions at SpringPeople for further education on these technologies.




































































![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)



