Downloaded 45 times







![11
NEW TENSOR CORE BUILT FOR AI
Delivering 120 TFLOPS of DL Performance
TENSOR CORE
ALL MAJOR FRAMEWORKSVOLTA-OPTIMIZED cuDNN
MATRIX DATA OPTIMIZATION:
Dense Matrix of Tensor Compute
TENSOR-OP CONVERSION:
FP32 to Tensor Op Data for
Frameworks
TENSOR CORE
VOLTA TENSOR CORE
4x4 matrix processing array
D[FP32] = A[FP16] * B[FP16] + C[FP32]
Optimized For Deep Learning](https://image.slidesharecdn.com/b1-ai-for-industry-overview-171030091001/85/GTC-Taiwan-2017-11-320.jpg)
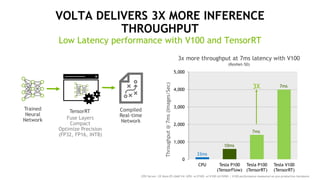
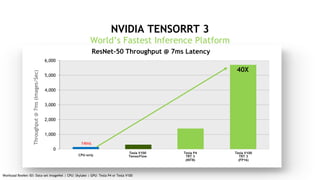


This document discusses the evolution of computing from PCs to mobile-cloud to AI and IoT. It highlights how deep learning using GPUs has become a new computing model, with neural network complexity exploding to tackle increasingly complex challenges. It introduces Nvidia's Volta GPU and how it delivers revolutionary performance for deep learning training and inference through new tensor cores and optimizations for deep learning frameworks and models.























































































