Download as PDF, PPTX





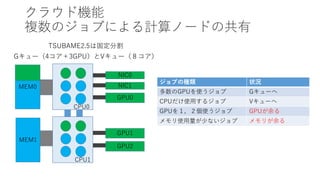
![(ビッグデータの) BYTES 能力が、特にデータのバンド
幅と容量がBD/AIの加速には大変重要だが、近年の
(Linpack)FLOPS偏重のスパコンには多くが欠けている
• システム全体のバンド幅(BYTE/S)と容
量(BYTES)がHPC-BD/AI統合には必要
(メモリバンド幅だけではNG)
• 左側の疎なデータ中心のアプリには自明
• 右側のDNNでも、高速化のためのマルチ
ノードの並列化で強スケーリングする場合
や、CTや地層などの3次元の大規模化す
るデータ解析を行う場合はやはり必要
(Source: https://www.spineuniverse.com/image-
library/anterior-3d-ct-scan-progressive-kyphoscoliosis)
(Source: http://www.dgi.com/images/cvmain_overview/CV4DOverview_Model_001.jpg)
CaffeNetのTSUBAME-KFC/DL
における学習時の一回のイ
テレーションの時間
(Mini-batch size 256)
殆どの時間が通信やメモリ
内の捜査に使用
1 2 4 8 16 1A 2A 4A 8A 16A
Iteration
Other
H2D
Commun
D2H
ForwardB
Number of nodes
Executiontime[s]
0.00.20.40.60.8
1 2 4 8 16 1A 2A 4A 8A 16A
Iteration
Other
H2D
Communication
D2H
ForwardBackward
Number of nodes
Executiontime[s]
0.00.20.40.60.8
1 2 4 8 16 1A 2A 4A 8A 16A
Iteration
Other
H2D
Communication
D2H
ForwardBackward
Number of nodes
Executiontime[s]
0.00.20.40.60.8
Number of nodes
殆どが通信時間
GPU上での計算
は僅か3.9%
BD/AIとHPCを統
合するスパコン
では、メモリや
ネットワークの
容量や性能を確
保するアーキや
そのシステムソ
フトが大変重要](https://image.slidesharecdn.com/dli2017nagoyamatsuokatsubame-abci-enhanced-j-170522082326/85/HPC-AI-TSUBAME3-0-ABCI-10-320.jpg)



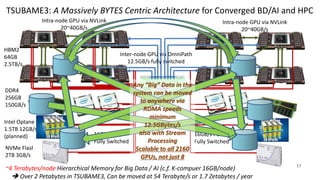

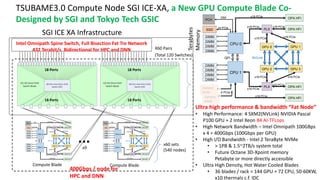

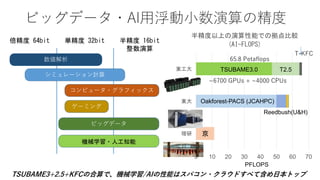

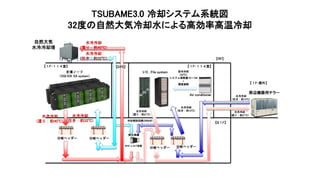
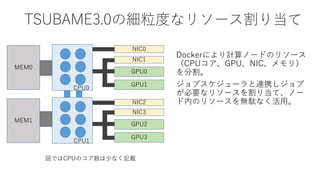
![TSUBAME3.0 世界トップクラスの冷却効率
TSUBAME 3.0 PUE 予測 (900KW消費仮定) 2013~2015年の天候データを元に計算
1月 2月 3月 4月 5月 6月 7月 8月 9月 10月 11月 12月
年間
平均
冷却設備
平均消費電力
[kW]
28.83 28.83 28.83 28.83 29.21 30.06 30.06 32.00 30.06 29.21 28.83 28.83 29.465
PUE 1.032 1.032 1.032 1.032 1.032 1.033 1.033 1.036 1.033 1.032 1.032 1.032 1.033
PUEは冷却のオーバーヘッドを表す。1.0に近いほど良い
PUE = {(計算ノードの消費電力)+(計算ノードの冷却に必要なすべての設備消費電力)}
/ (計算ノードの消費電力)
• 通常のデータセンター:PUE = 2~3 (冷却の方がマシンより電気を食っている)
• 最新の空冷データセンター、TSUBAME1:PUE = 1.4~1.6
• TSUBAME2.0:PUE = 1.28
• TSUBAME-KFC:PUE = 1.09
TSUBAME3.0の計算ノードの年間PUE平均値は『1.033』
世界トップクラス 4-27](https://image.slidesharecdn.com/dli2017nagoyamatsuokatsubame-abci-enhanced-j-170522082326/85/HPC-AI-TSUBAME3-0-ABCI-24-320.jpg)
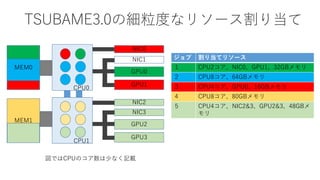
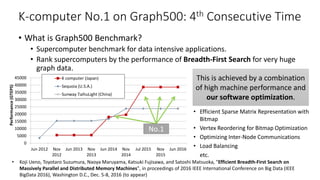
![Sparse BYTES: The Graph500 – 2015~2016 – world #1 x 4
K Computer #1 Tokyo Tech[Matsuoka EBD CREST] Univ.
Kyushu [Fujisawa Graph CREST], Riken AICS, Fujitsu
List Rank GTEPS Implementation
November 2013 4 5524.12 Top-down only
June 2014 1 17977.05 Efficient hybrid
November 2014 2 19585.2 Efficient hybrid
June, Nov 2015
June Nov 2016
1 38621.4
Hybrid + Node
Compression
BYTES Rich
Machine + Superior
BYTES algoithm
88,000 nodes,
660,000 CPU Cores
1.3 Petabyte mem
20GB/s Tofu NW
≫
LLNL-IBM Sequoia
1.6 million CPUs
1.6 Petabyte mem
0
200
400
600
800
1000
1200
64 nodes
(Scale 30)
65536 nodes
(Scale 40)
ElapsedTime(ms)
Communi…
Computati…
73% total exec
time wait in
communication
TaihuLight
10 million CPUs
1.3 Petabyte mem
Effective x13
performance c.f.
Linpack
#1 38621.4 GTEPS
(#7 10.51PF Top500)
#2 23755.7 GTEPS
(#1 93.01PF Top500)
#3 23751 GTEPS
(#4 17.17PF Top500)
BYTES, not FLOPS!](https://image.slidesharecdn.com/dli2017nagoyamatsuokatsubame-abci-enhanced-j-170522082326/85/HPC-AI-TSUBAME3-0-ABCI-30-320.jpg)
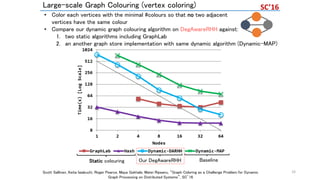
![share.sa ndia.g ov
Dynamic Graph ApplicationStreaming edg es
NVRAM
Larg e-scale Dynamic Graph Data Store
NVRAM NVRAM
mmap mmap mmap
Comp.
N ode
Comp.
N ode
Comp.
N ode
Distributed Large-Scale Dynamic Graph Data Store (work with LLNL, [SC16 etc.])
Node Level Dynamic Graph Data Store
Extend for multi-processes using an async
MPI communication framework
Follows an adjacency-list format and leverages an
open address hashing to construct its tables
2 billion
insertions/s
InsertedBillionEdges/sec
Number of Nodes (24 processes per node)
Multi-node Experiment
STINGER
• A state-of-the-art dynamic graph processing
framework developed at Georgia Tech
Baseline model
• A naïve implementation using Boost library (C++) and
the MPI communication framework
Based on K-Computer results, adaping to (1) deep
memory hierarchy, (2) rapid dynamic graph changes
K. Iwabuchi, S. Sallinen, R. Pearce, B. V. Essen, M. Gokhale, and S. Matsuoka, Towards a distributed large-scale dynamic graph data store. In 2016
IEEE Interna- tional Parallel and Distributed Processing Symposium Workshops (IPDPSW)
C.f. STINGER (single-node, on memory)
0
200
6 12 24
SpeedUp
Parallels
Baseline DegAwareRHH 212x
Dynamic Graph Construction (on-memory & NVM)
K Computer
large
memory
but very
expensive
DRAM only
Develop
algorithms
and SW
exploiting
large
hierarchical
memory
Dynamic graph store
w/ world’s top graph
update performance
and scalability](https://image.slidesharecdn.com/dli2017nagoyamatsuokatsubame-abci-enhanced-j-170522082326/85/HPC-AI-TSUBAME3-0-ABCI-32-320.jpg)

![GPU-based Distributed Sorting
[Shamoto, IEEE BigData 2014, IEEE Trans. Big Data 2015]
• Sorting: Kernel algorithm for various EBD processing
• Fast sorting methods
– Distributed Sorting: Sorting for distributed system
• Splitter-based parallel sort
• Radix sort
• Merge sort
– Sorting on heterogeneous architectures
• Many sorting algorithms are accelerated by many cores and high memory bandwidth.
• Sorting for large-scale heterogeneous systems remains unclear
• We develop and evaluate bandwidth and latency reducing GPU-based HykSort on
TSUBAME2.5 via latency hiding
– Now preparing to release the sorting library
EBD Algorithm Kernels](https://image.slidesharecdn.com/dli2017nagoyamatsuokatsubame-abci-enhanced-j-170522082326/85/HPC-AI-TSUBAME3-0-ABCI-35-320.jpg)
![0
10
20
30
0 500 1000 1500 2000
# of proccesses (2 proccesses per node)
Keys/second(billions)
HykSort 1thread
HykSort 6threads
HykSort GPU + 6threads
x1.4
x3.61
x389
0.25
[TB/s]
Performance prediction
x2.2 speedup compared to
CPU-based
implementation when the
# of PCI bandwidth
increase to 50GB/s
8.8% reduction of overall
runtime when the
accelerators work 4 times
faster than K20x
• PCIe_#: #GB/s bandwidth
of interconnect between
CPU and GPU
• Weak scaling performance (Grand
Challenge on TSUBAME2.5)
– 1 ~ 1024 nodes (2 ~ 2048 GPUs)
– 2 processes per node
– Each node has 2GB 64bit integer
• C.f. Yahoo/Hadoop Terasort:
0.02[TB/s]
– Including I/O
GPU implementation of splitter-
based sorting (HykSort)](https://image.slidesharecdn.com/dli2017nagoyamatsuokatsubame-abci-enhanced-j-170522082326/85/HPC-AI-TSUBAME3-0-ABCI-36-320.jpg)
![Xtr2sort: Out-of-core Sorting Acceleration
using GPU and Flash NVM [IEEE BigData2016]
• Sample-sort-based Out-of-core Sorting Approach for Deep Memory
Hierarchy Systems w/GPU and Flash NVM
– I/O chunking to fit device memory capacity of GPU
– Pipeline-based Latency hiding to overlap data transfers between NVM, CPU, and
GPU using asynchronous data transfers,
e.g., cudaMemCpyAsync(), libaio
RD R2H H2D EX D2H H2W WR
RD R2H H2D EX D2H H2W WR
RD R2H H2D EX D2H H2W WR
RD R2H H2D EX D2H H2W WR
RD R2H H2D EX D2H H2W WR
RD R2H H2D EX D2H H2W WR
chunk&i
chunk&i+1
chunk&i+2
chunk&i+3
chunk&i+4
RD R2H H2D EX D2H H2W WR
chunk&i+5
chunk&i+6
c chunks
time
GPU
GPU + CPU + NVM
CPU + NVM
How to combine deepening memory layers for
future
HPC/Big Data workloads, targeting Post Moore Era?
x4.39
BYTES中心のHPCア
ルゴリズム:GPUのバ
ンド幅高速ソートと、
不揮発性メモリによる
大容量化の両立](https://image.slidesharecdn.com/dli2017nagoyamatsuokatsubame-abci-enhanced-j-170522082326/85/HPC-AI-TSUBAME3-0-ABCI-37-320.jpg)


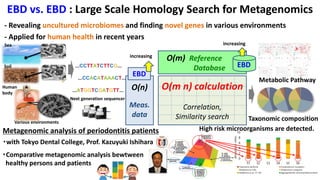
![HPC and BD/AI Convergence Example [ Yutaka Akiyama, Tokyo Tech]
Oral/Gut Metagenomics
Ultra-fast Seq. Analysis
Exhaustive PPI
Prediction System
Pathway Predictions
Fragment-based
Virtual Screening
Learning-to-Rank VS
Genomics Protein-Protein
Interactions
Drug Discovery
• Ohue et al., Bioinformatics (2014)
• Suzuki et al., Bioinformatics (2015)
• Suzuki et al., PLOS ONE (2016)
• Matsuzaki et al., Protein Pept Lett (2014) • Suzuki et al., AROB2017 (2017)
• Yanagisawa et al., GIW (2016)
• Yamasawa et al., IIBMP (2016)
43](https://image.slidesharecdn.com/dli2017nagoyamatsuokatsubame-abci-enhanced-j-170522082326/85/HPC-AI-TSUBAME3-0-ABCI-43-320.jpg)
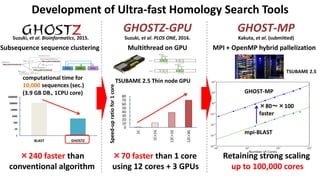
![Estimated Compute Resource Requirements for Deep Learning
[Source: Preferred Network Japan Inc.]
2015 2020 2025 2030
1E〜100E Flops
自動運転車1台あたり1日 1TB
10台〜1000台, 100日分の走行データの学習
Bio / Healthcare
Image Recognition Robots / Drones
10P〜 Flops
1万人の5000時間分の音声データ
人工的に生成された10万時間の
音声データを基に学習 [Baidu 2015]
100P 〜 1E Flops
一人あたりゲノム解析で約10M個のSNPs
100万人で100PFlops、1億人で1EFlops
10P(Image) 〜 10E(Video) Flops
学習データ:1億枚の画像 10000クラス分類
数千ノードで6ヶ月 [Google 2015]
Image/Video
Recognition
1E〜100E Flops
1台あたり年間1TB
100万台〜1億台から得られた
データで学習する場合
Auto Driving
10PF 100EF100PF 1EF 10EF
P:Peta
E:Exa
F:Flops
機械学習、深層学習は学習データが大きいほど高精度になる
現在は人が生み出したデータが対象だが、今後は機械が生み出すデータが対象となる
各種推定値は1GBの学習データに対して1日で学習するためには
1TFlops必要だとして計算
To complete the learning phase in one day
It’s the FLOPS
(in reduced
precision)
and BW!
So both are
important in the
infrastructure](https://image.slidesharecdn.com/dli2017nagoyamatsuokatsubame-abci-enhanced-j-170522082326/85/HPC-AI-TSUBAME3-0-ABCI-49-320.jpg)


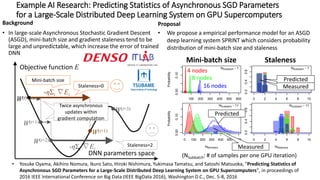
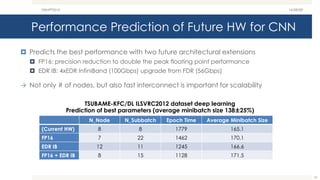
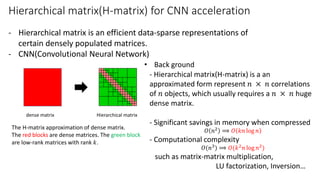
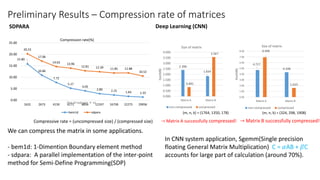
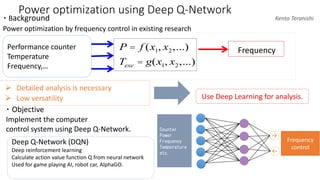





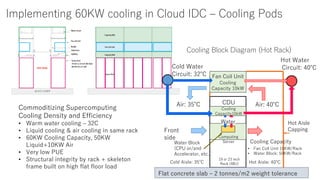




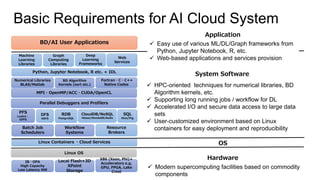

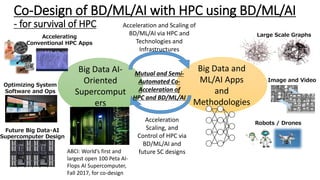


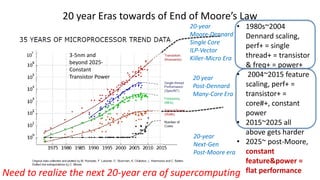


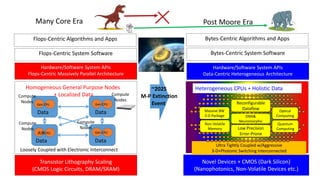

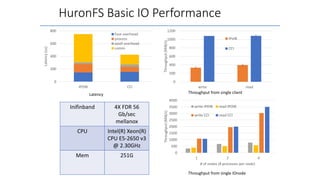
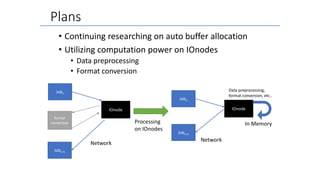
- The document discusses the latest HPC technologies used in AI/Big Data infrastructures such as TSUBAME3.0 at Tokyo Institute of Technology and ABCI at AIST. - It provides an overview of the capabilities and achievements of these supercomputers, including TSUBAME2.0 receiving the 2011 ACM Gordon Bell Prize. - It emphasizes that future supercomputers need to focus on "BYTES" capabilities like bandwidth and capacity to better support large-scale data processing for AI/Big Data applications.





![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)










![[RakutenTechConf2013] [A-3] TSUBAME2.5 to 3.0 and Convergence with Extreme Bi...](https://cdn.slidesharecdn.com/ss_thumbnails/techconf2013a3-131119010414-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


























































