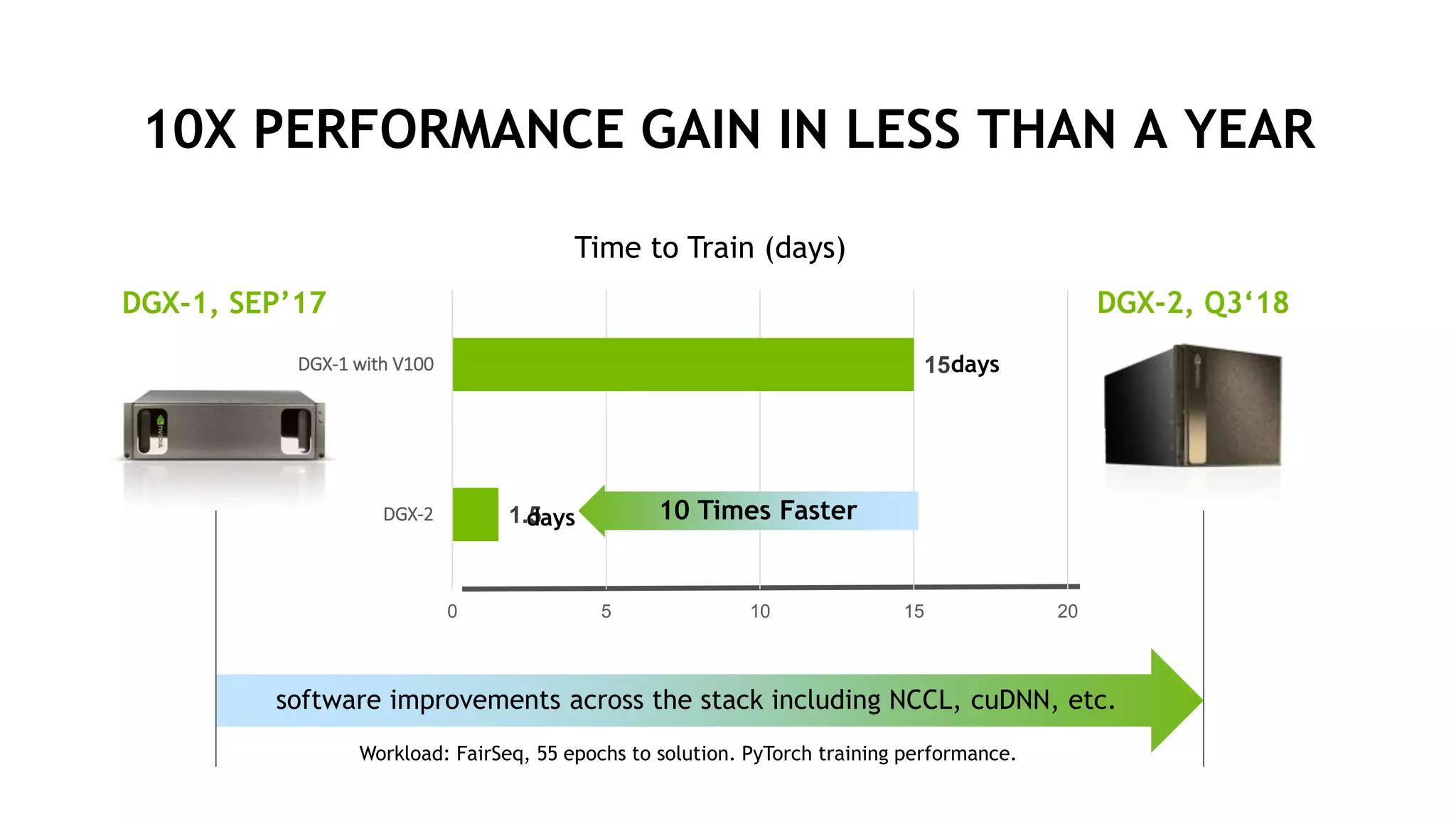
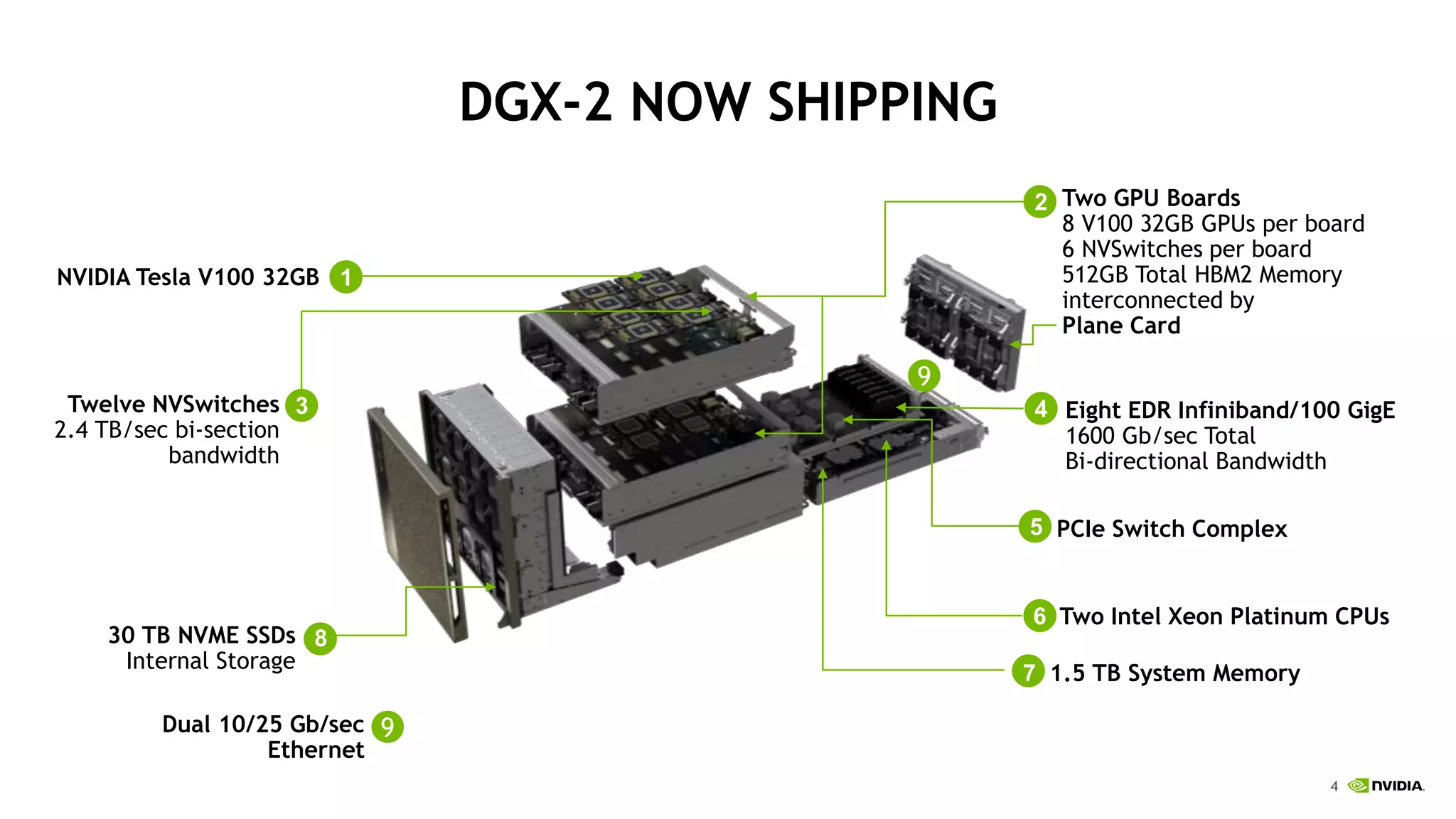
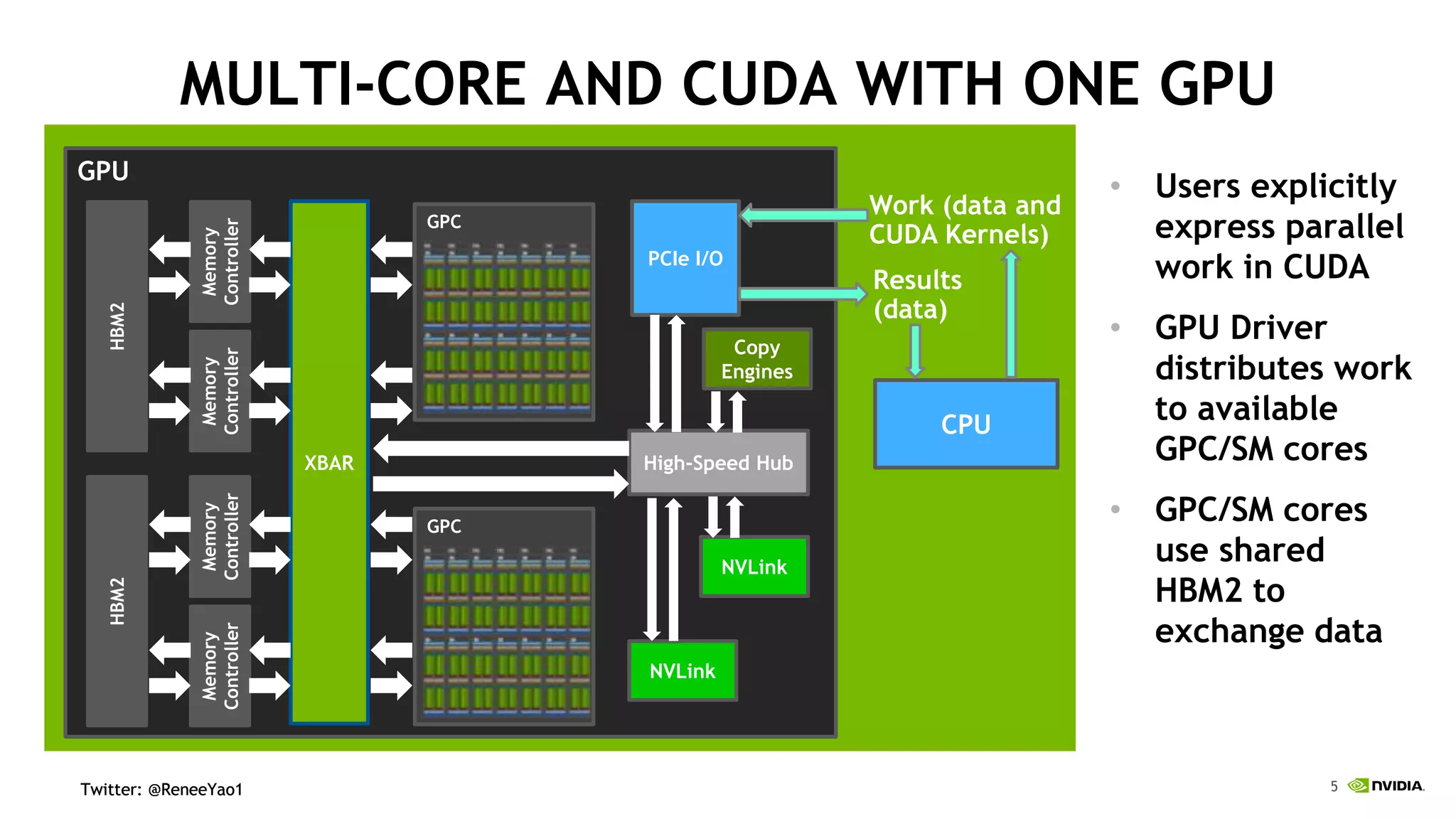
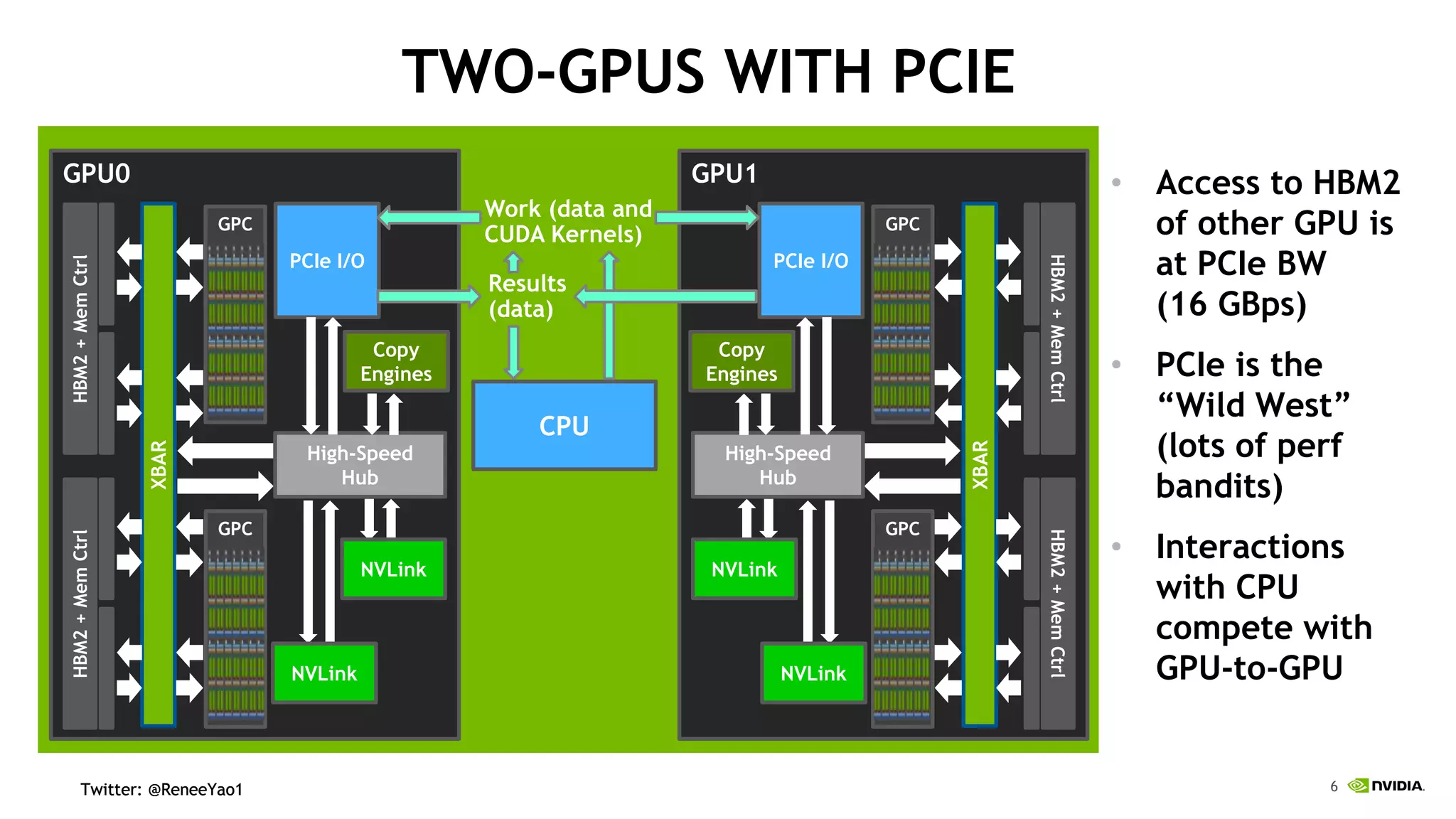
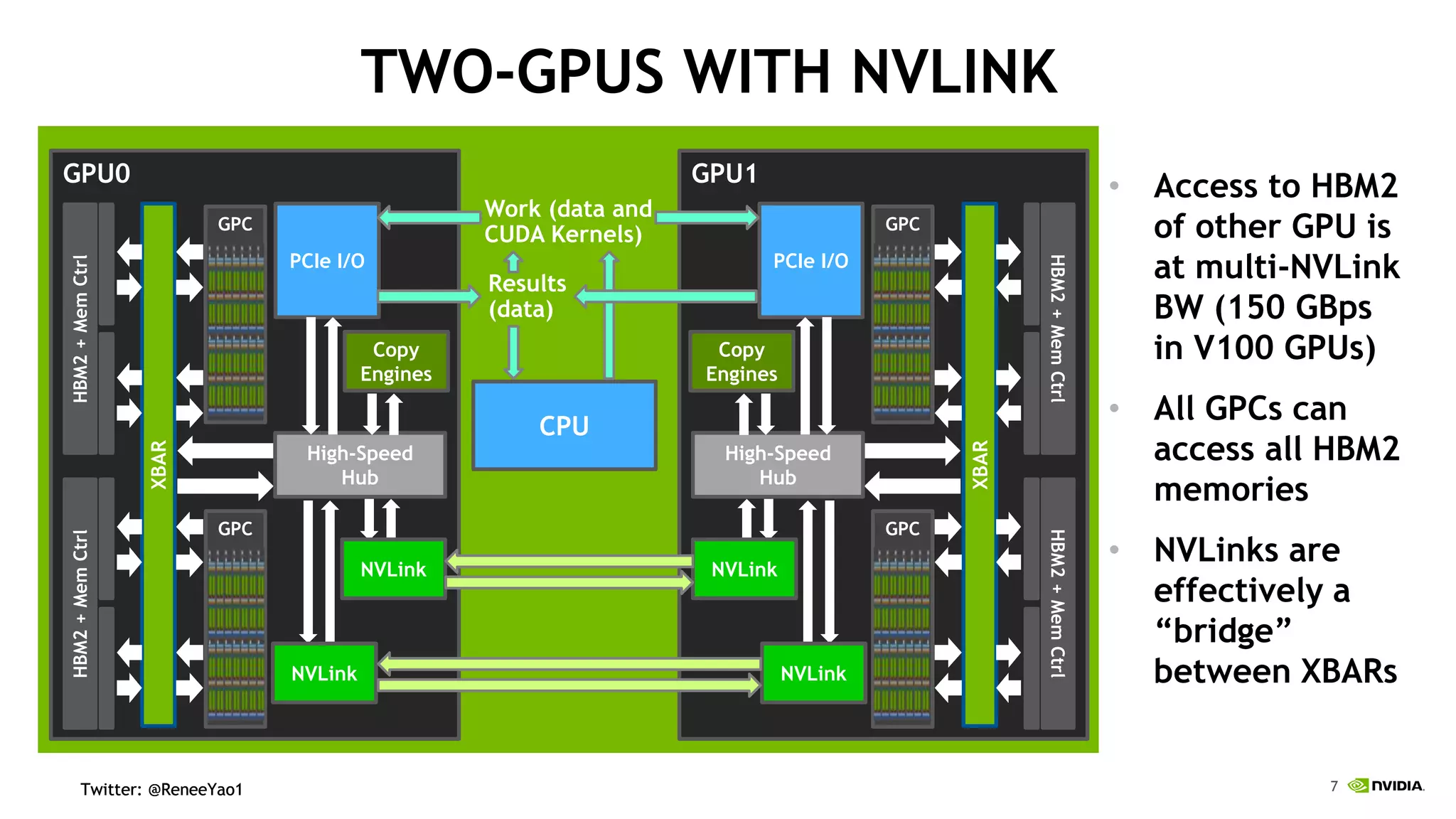
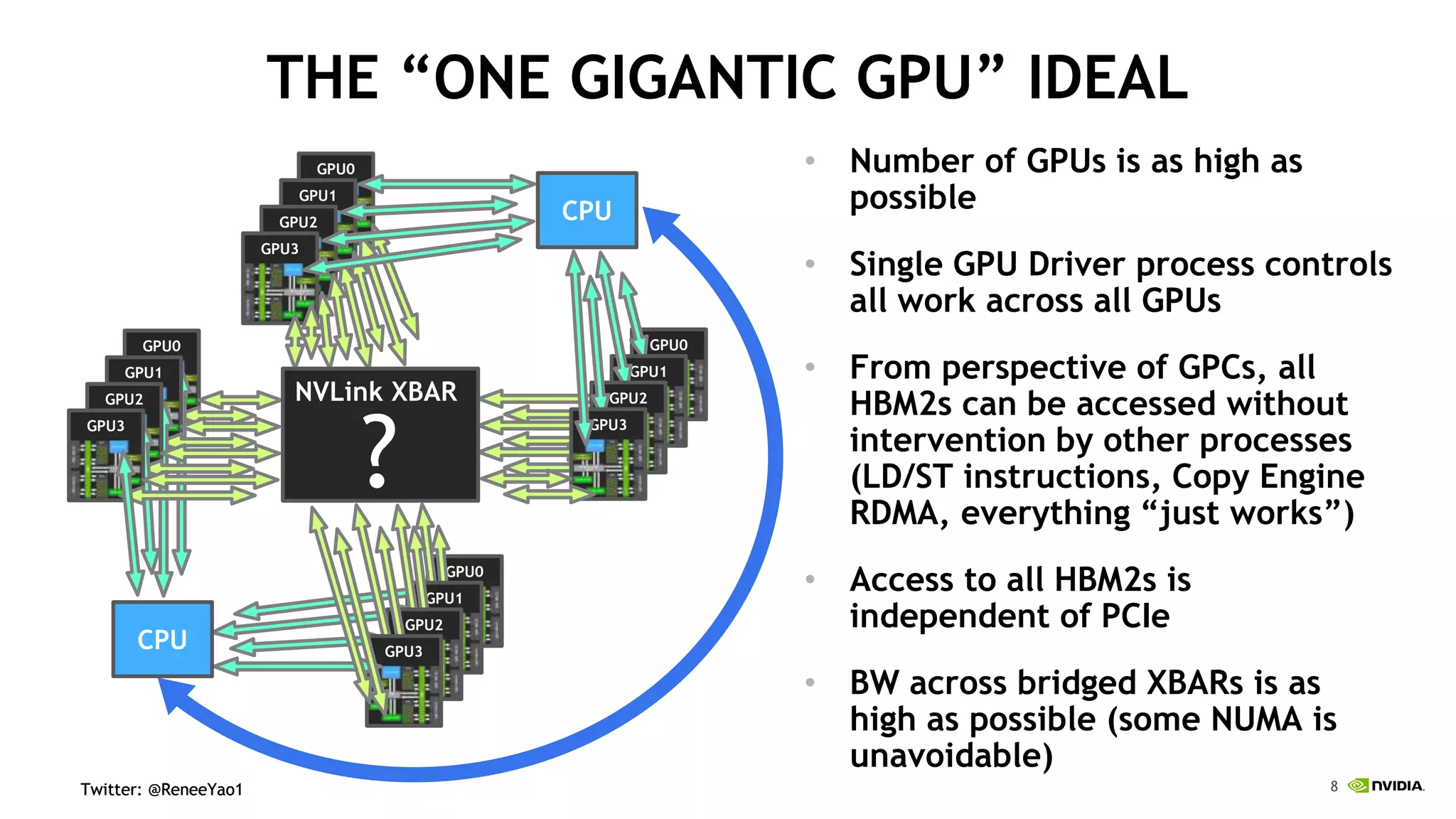
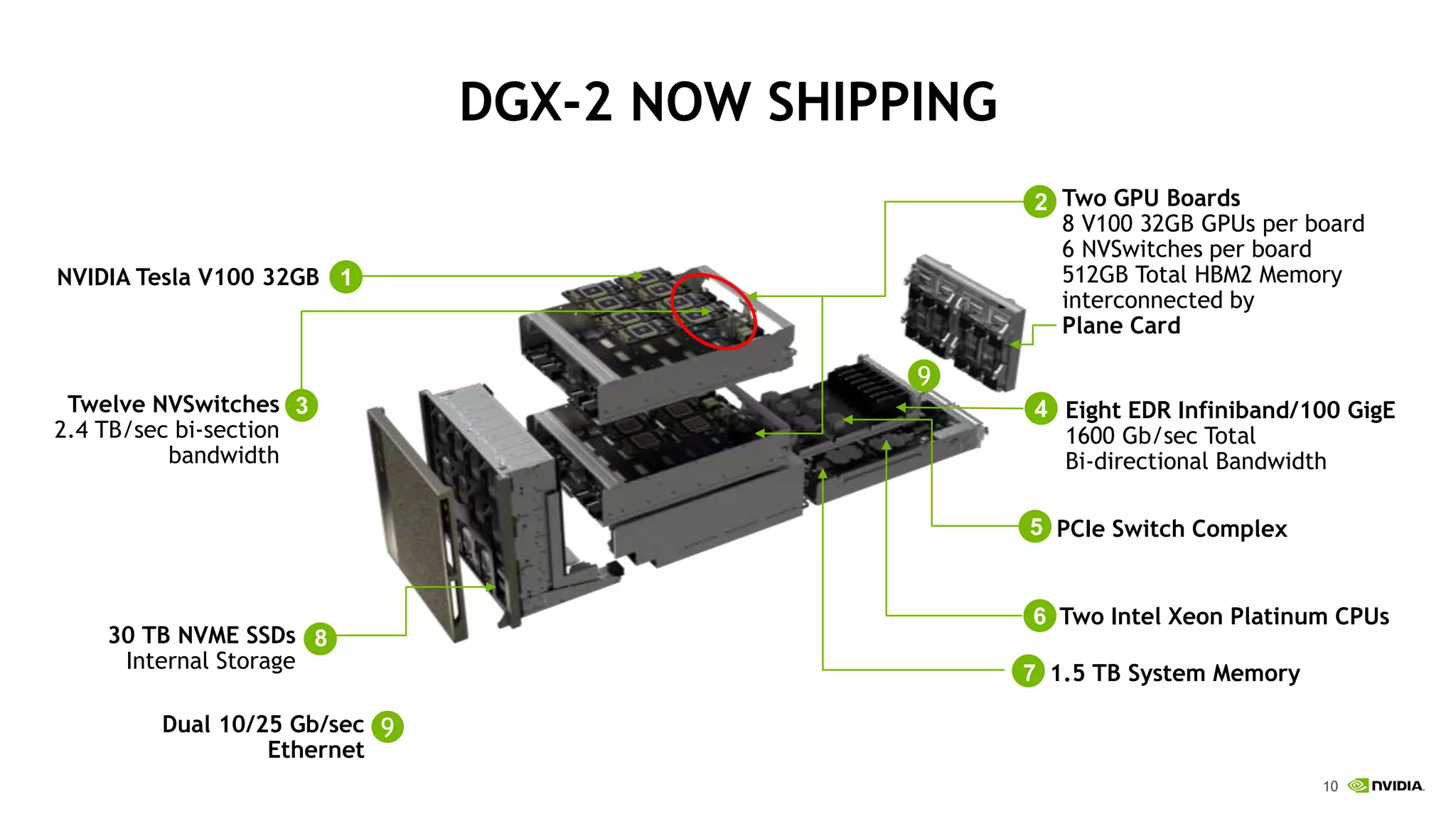
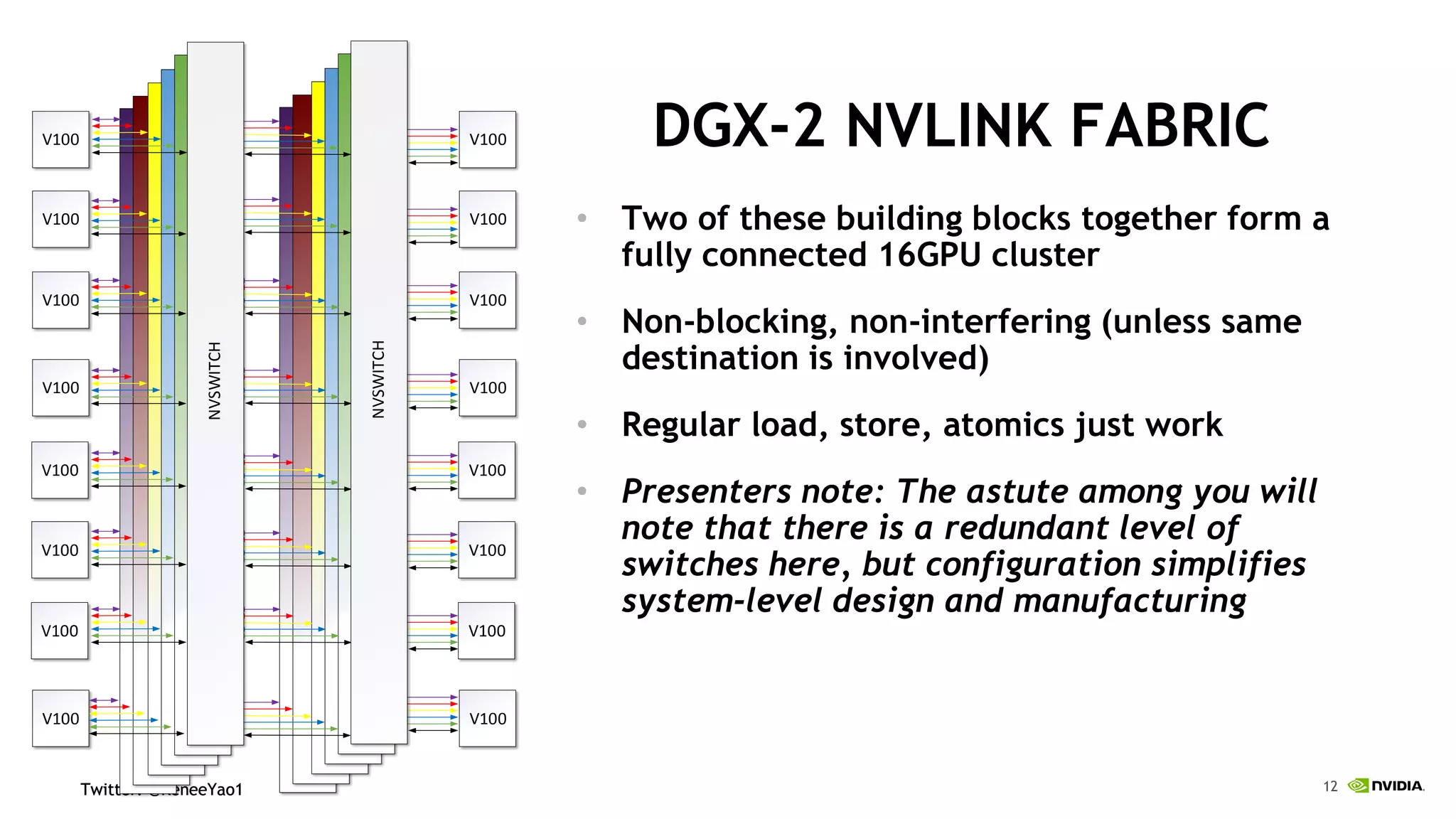
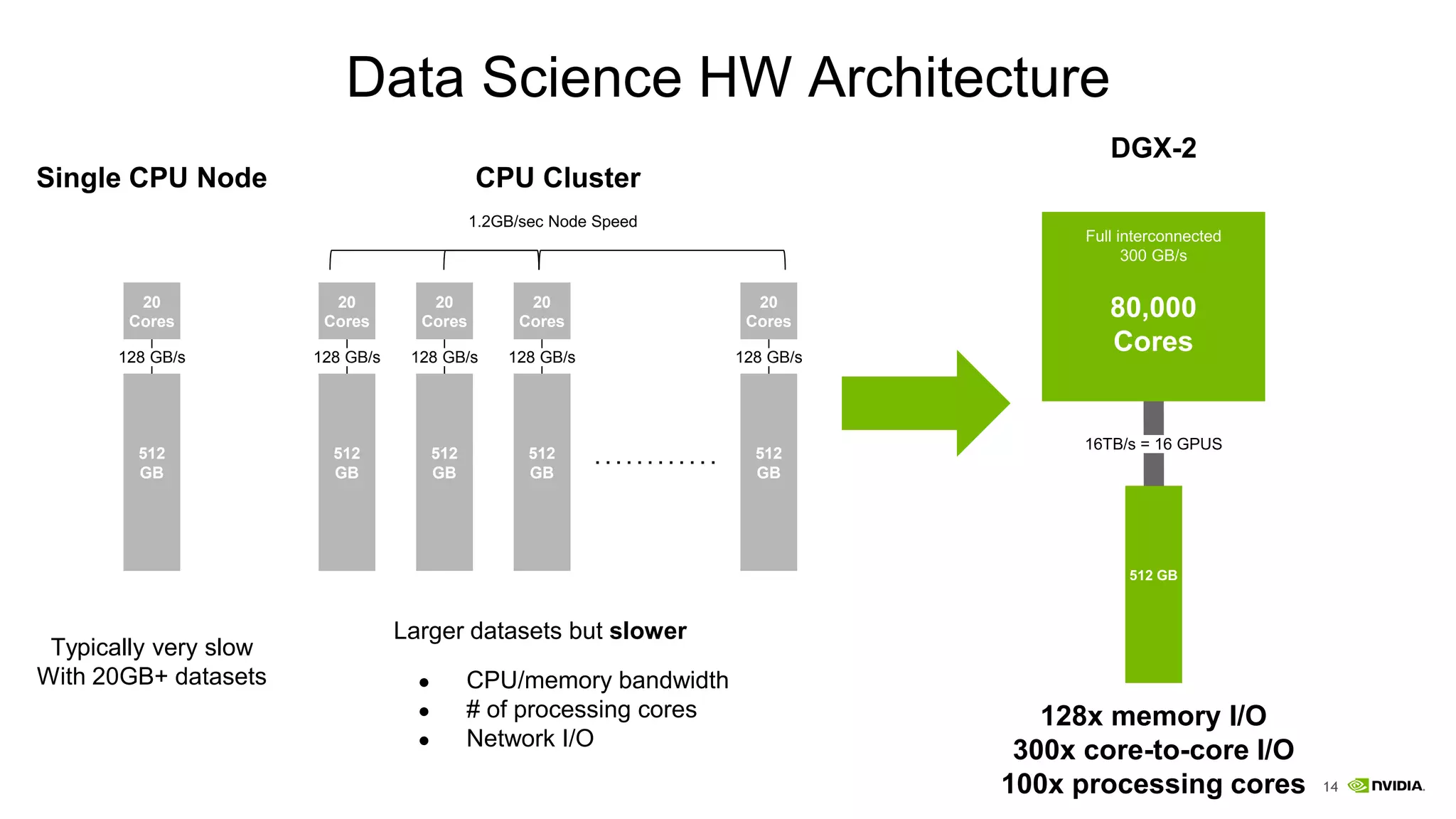
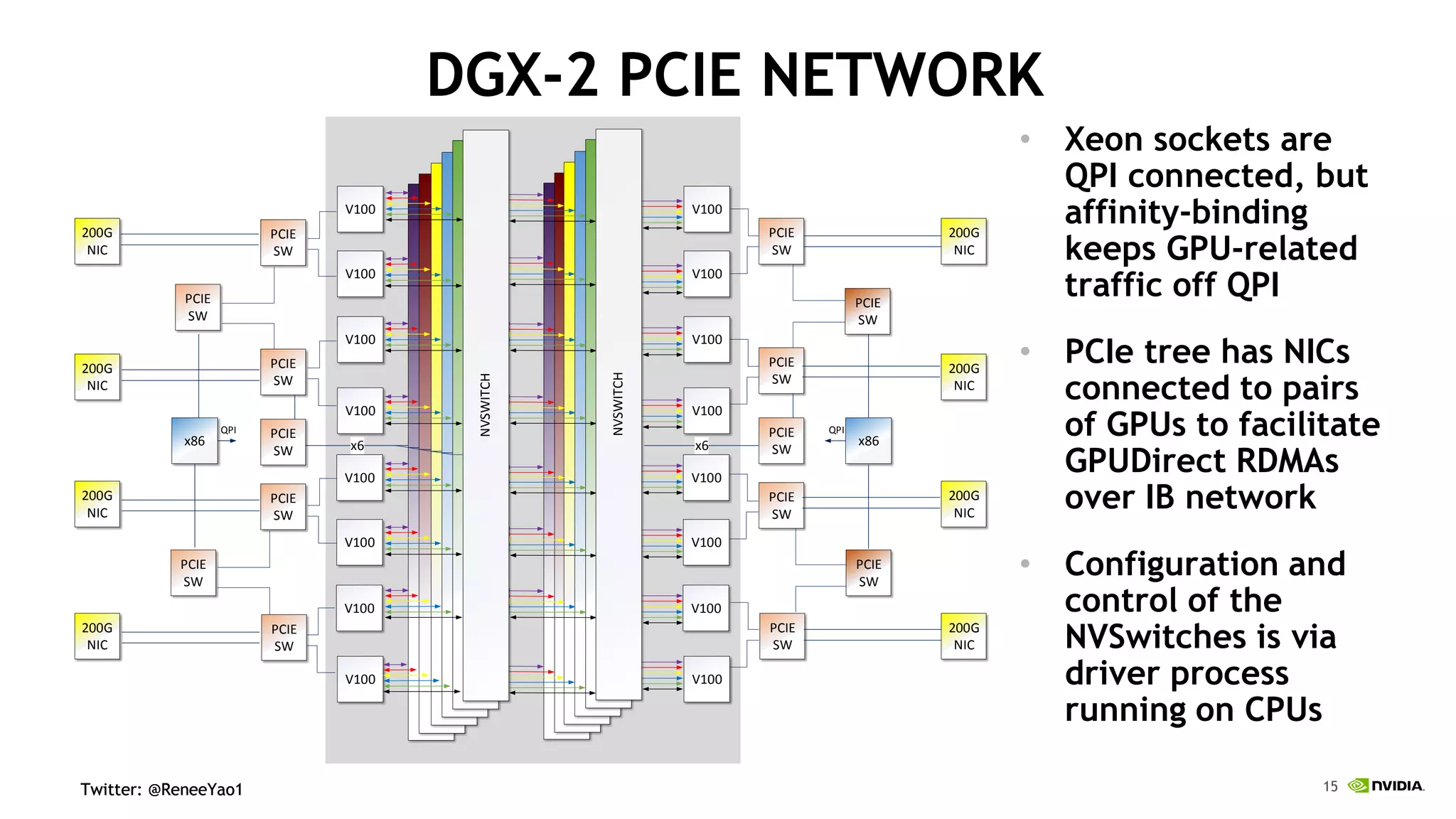
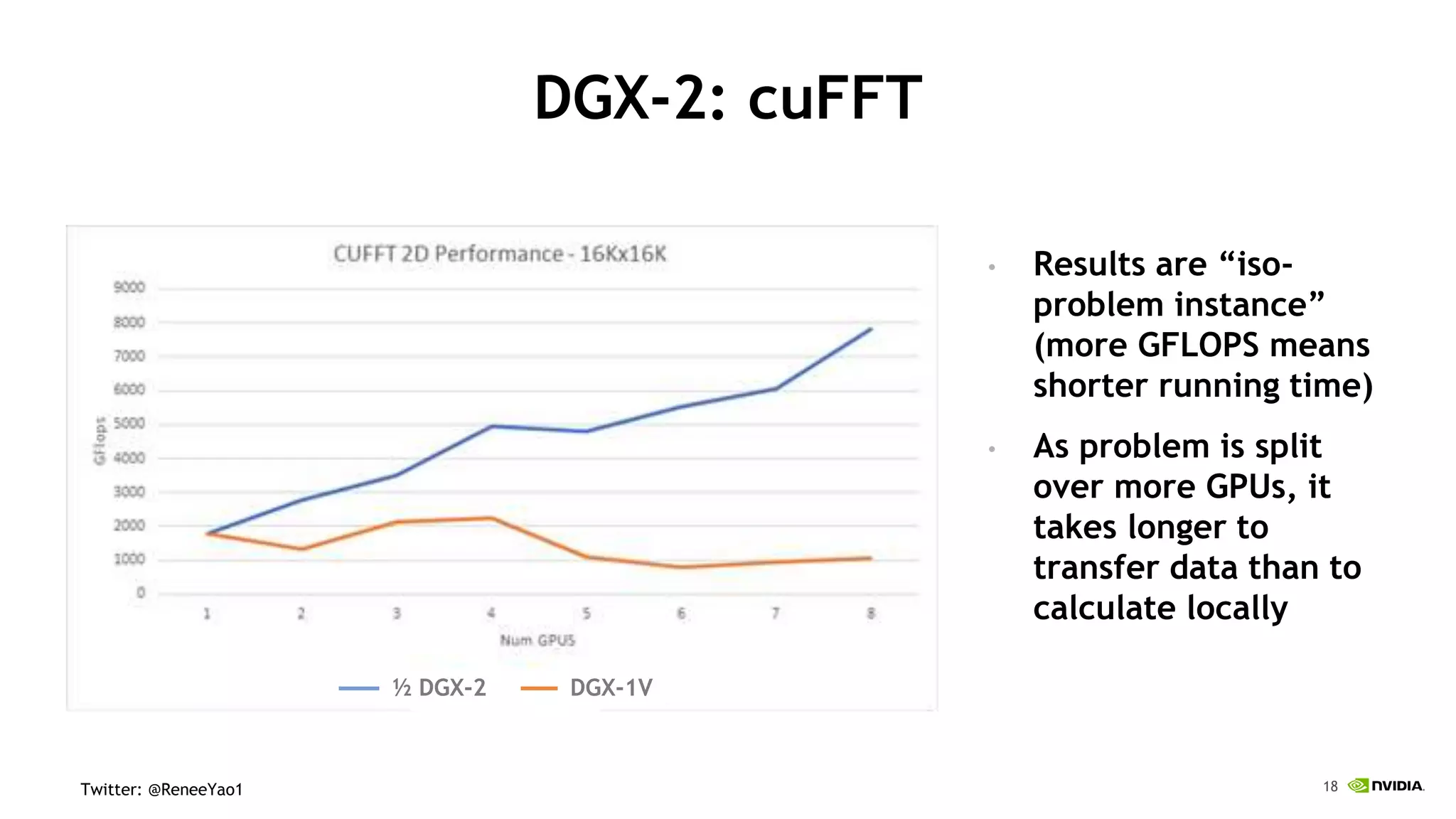
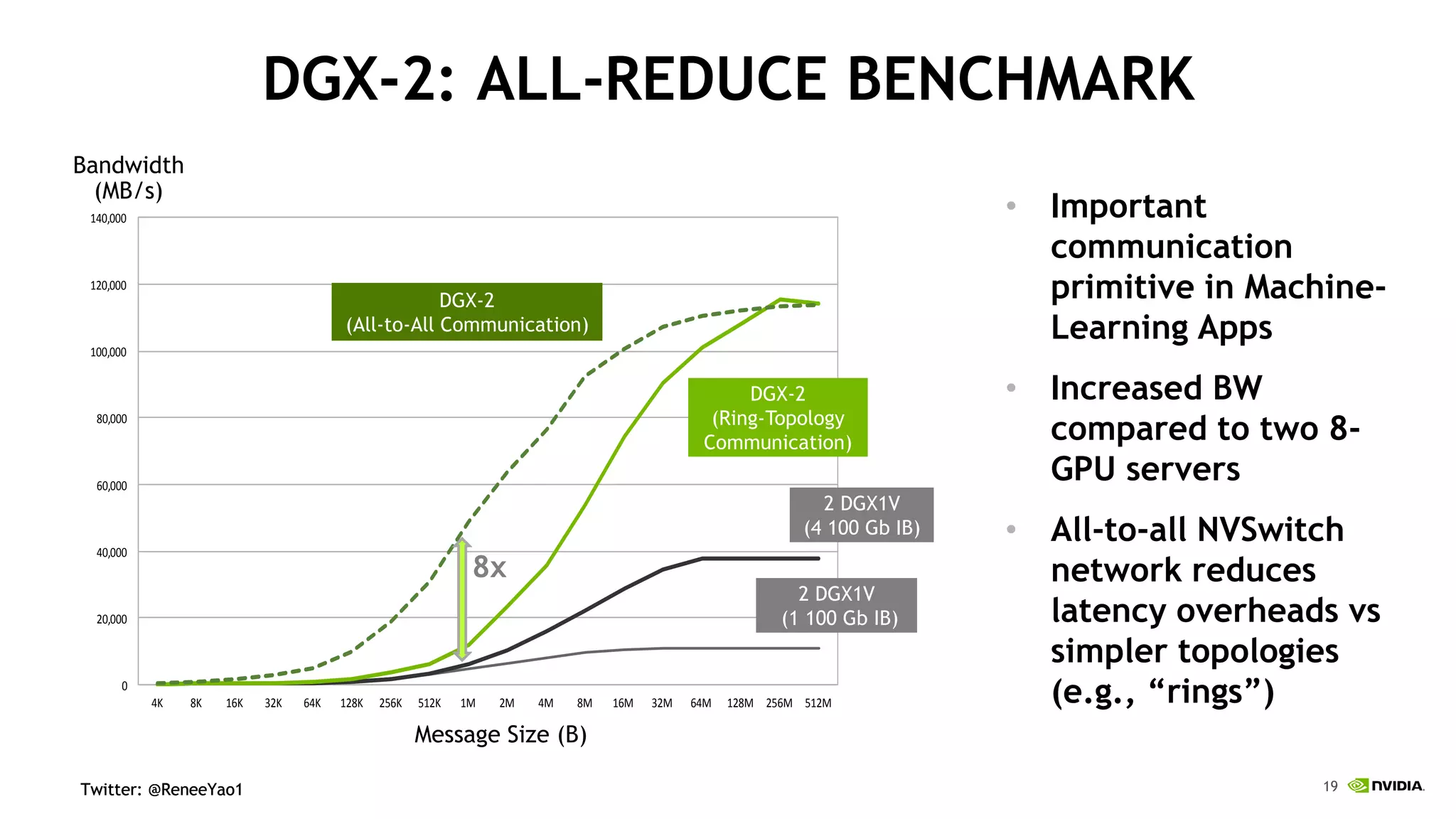
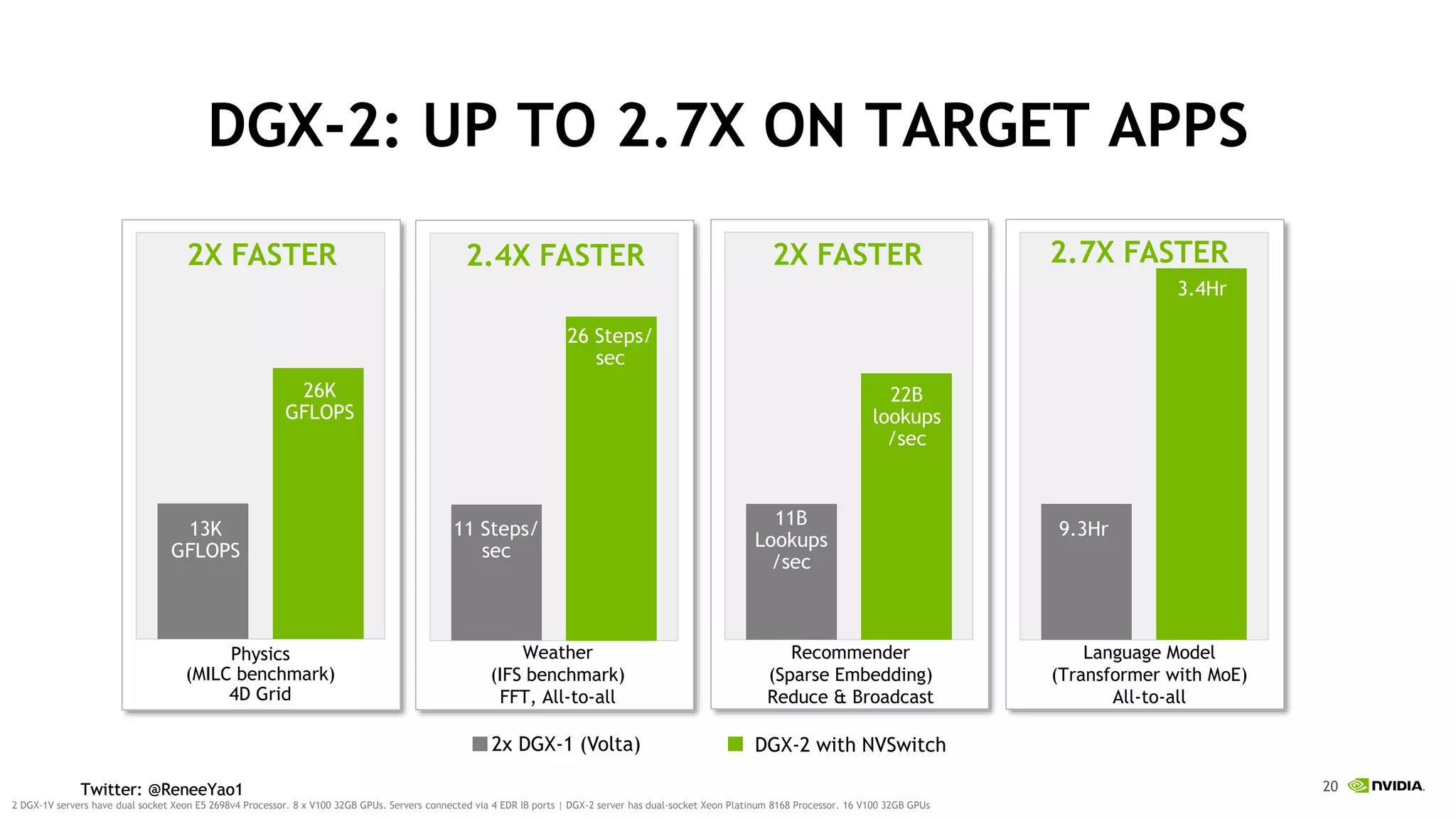
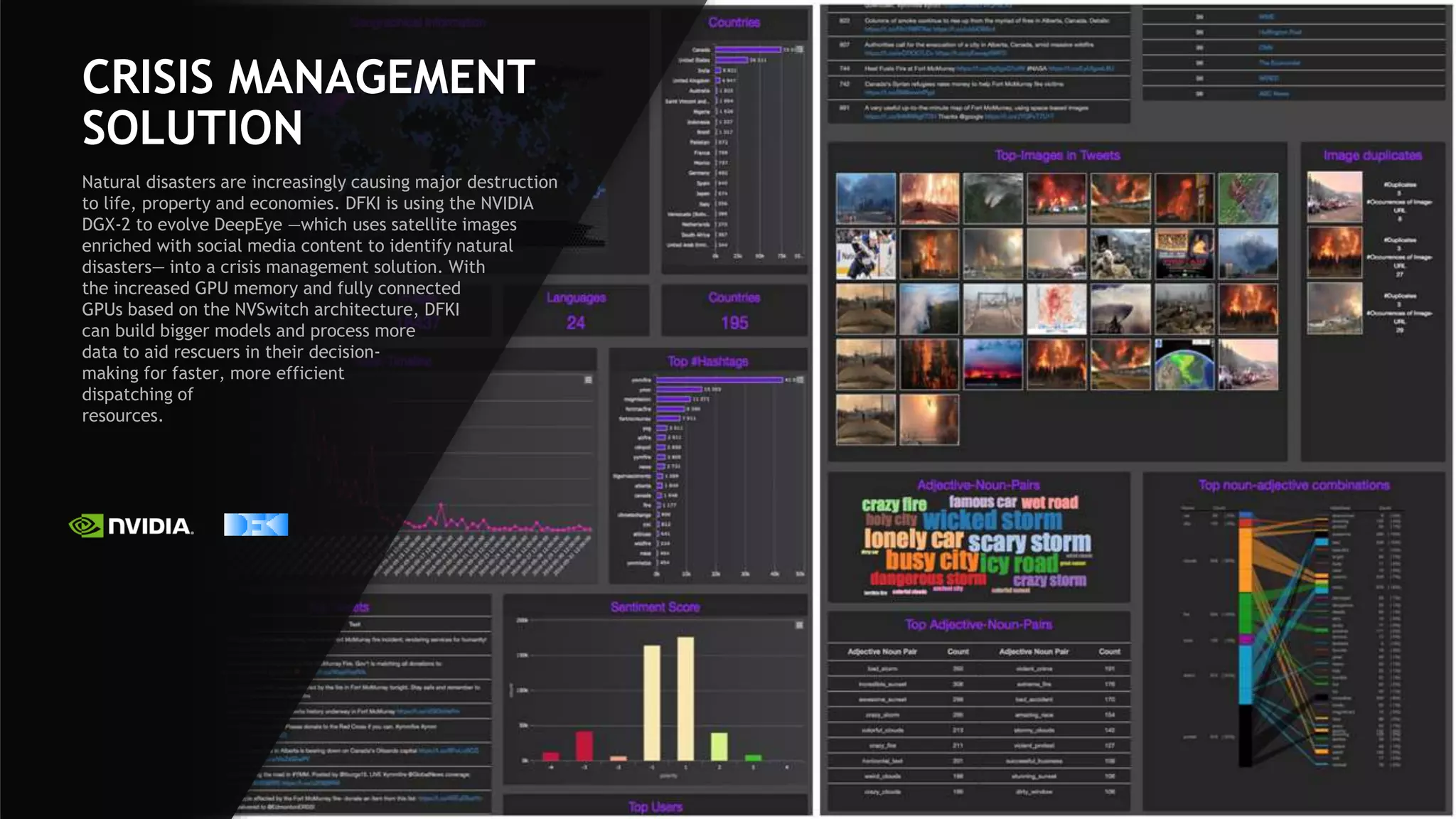
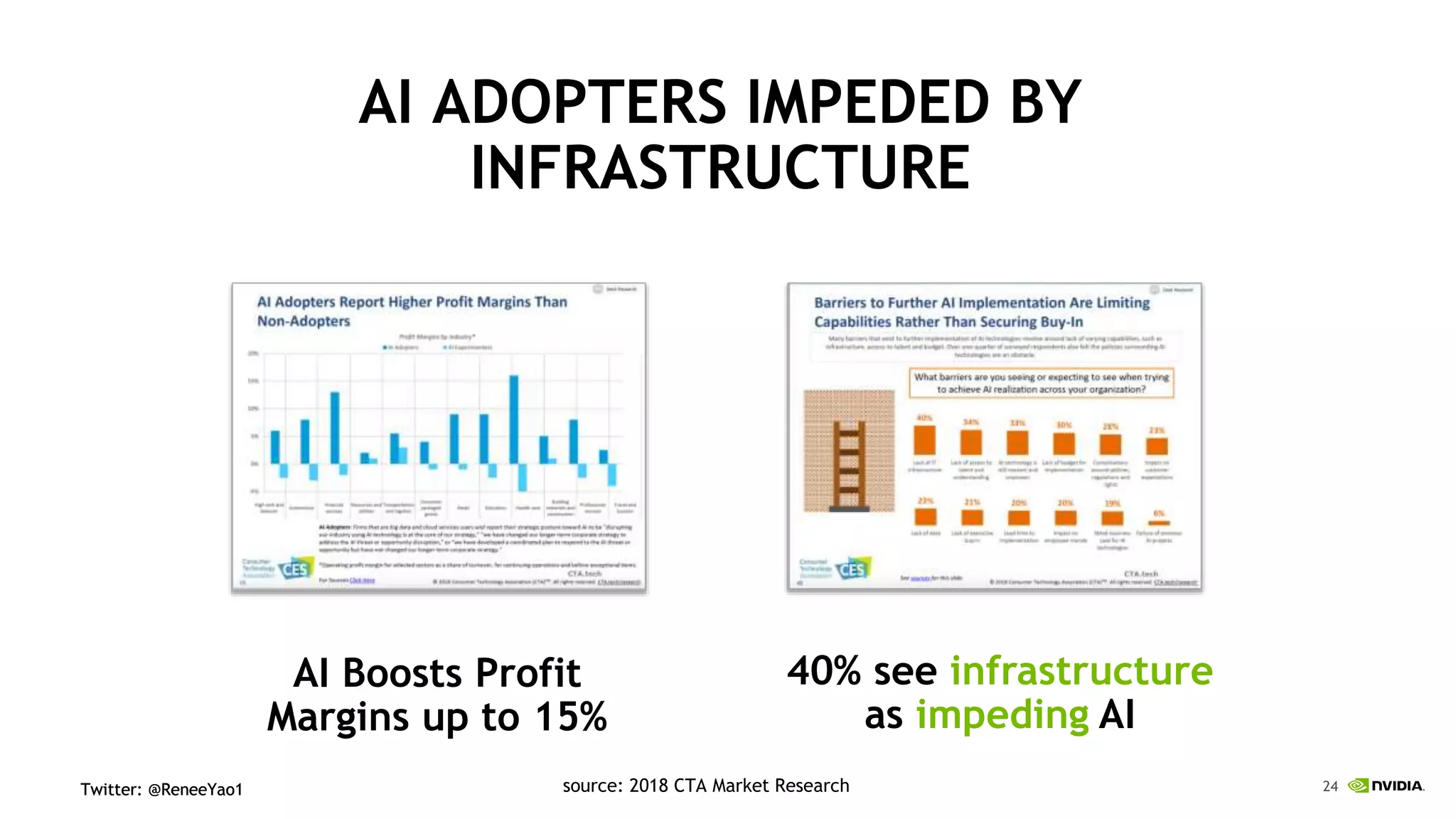
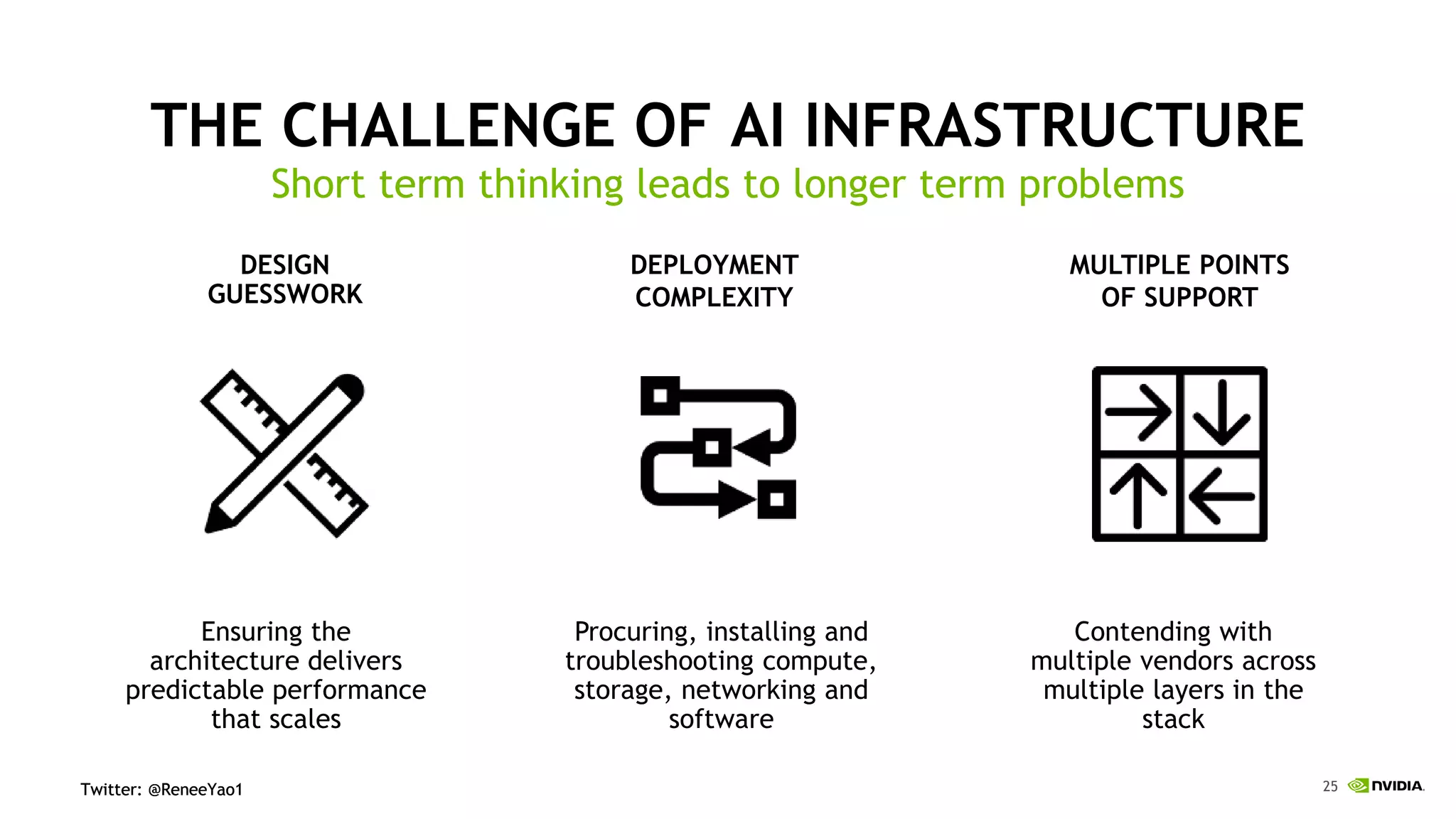
NVIDIA's DGX-2 supercomputer system, featuring Tesla V100 GPUs and NVSwitch architecture, delivers significant advancements in AI performance, providing up to 10x faster training times than its predecessor, DGX-1. The system enhances GPU connectivity and memory bandwidth, supporting complex AI tasks such as natural disaster management and healthcare image diagnostics. With a focus on scalable AI infrastructure, NVIDIA aims to reduce deployment time and increase productivity for data scientists across various industries.



















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















