The document provides an overview of genetic algorithms, including their inspiration from evolution, the basic algorithm, why they work, strengths and weaknesses, and applications. It summarizes the encoding, selection, crossover, and mutation steps of the basic genetic algorithm. It also gives examples of genetic algorithms applied to the traveling salesman problem (TSP), including encoding solutions and crossover/mutation operators.









![Schemas
Population
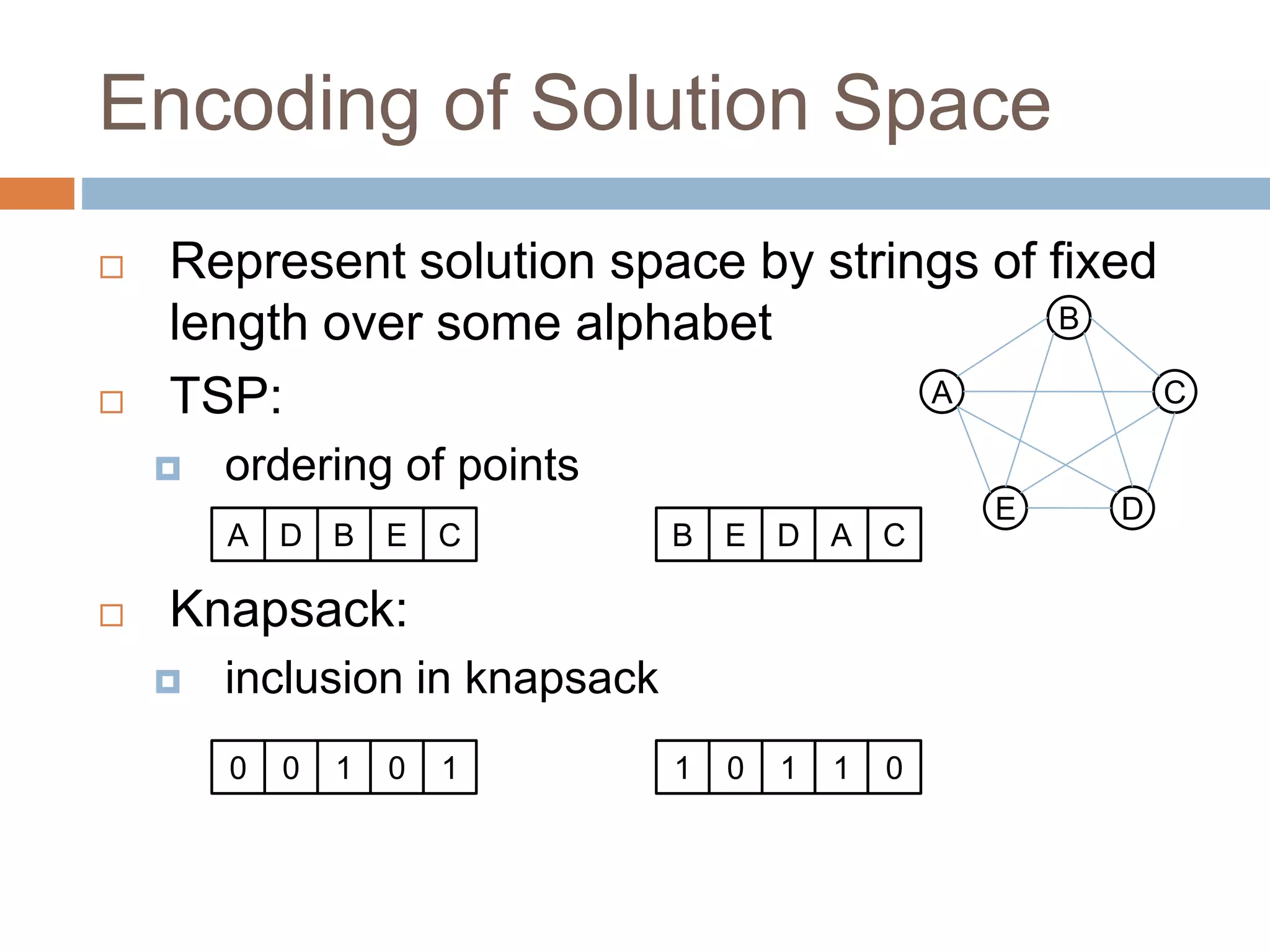
Strings over alphabet {0,1} of length L
E.g.
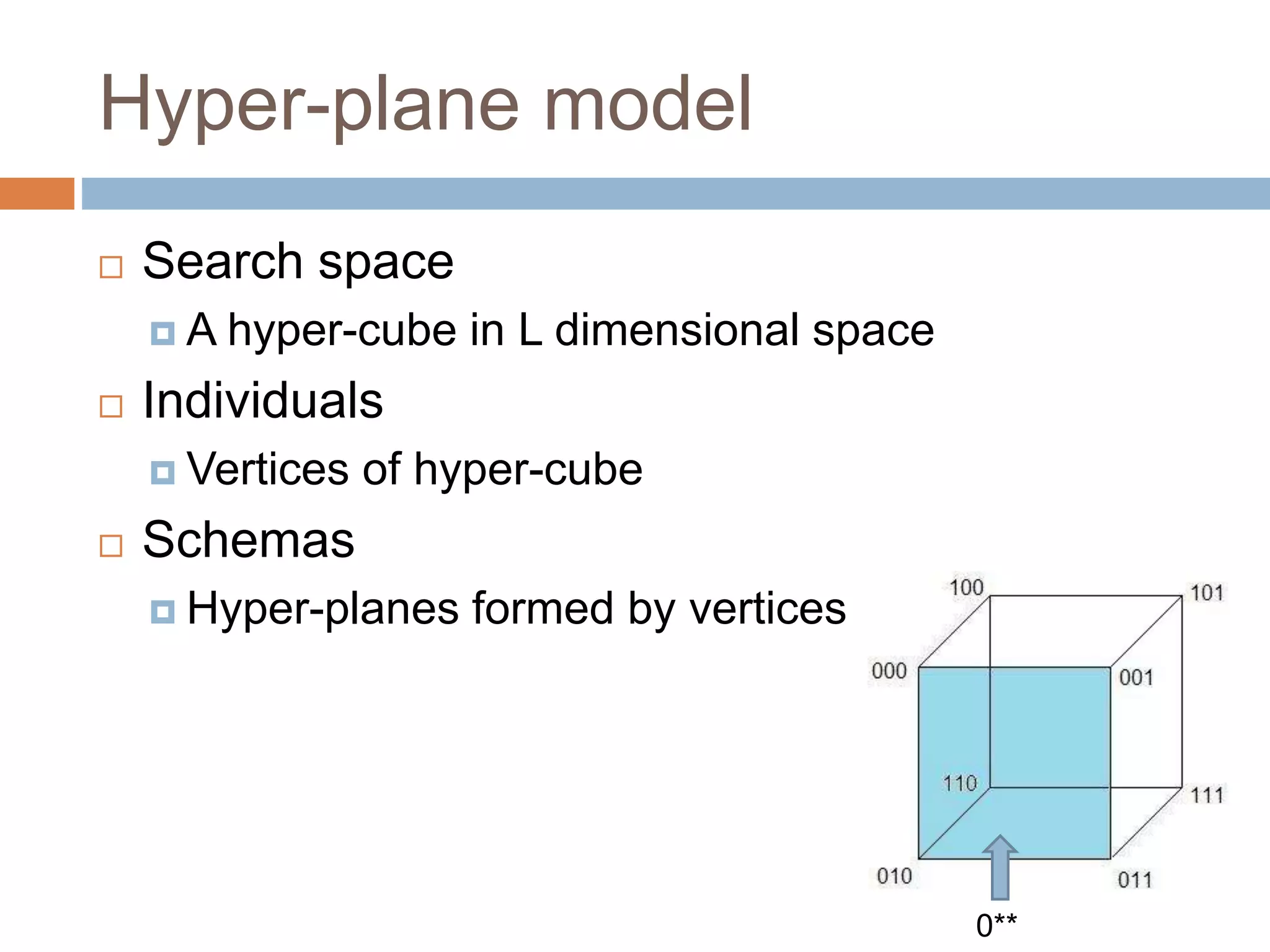
Schema
A schema is a subset of the space of all possible
individuals for which all the genes match the
template for schema H.
Strings over alphabet {0,1,*} of length L
E.g. }
11110
,
11010
,
10110
,
10010
{
]
10
*
*
1
[
H
10010
s](https://image.slidesharecdn.com/group-9geneticalgorithms1-211127135346/75/Group-9-genetic-algorithms-1-12-2048.jpg)
















![TSP – Mutation Operators
Exchange Mutation Operator (EM)
Randomly select two nodes and interchange their
positions.
( 1 2 3 4 5 6 ) can become ( 1 2 6 4 5 3 )
Displacement Mutation Operator (DM)
Select a random sub-tour, remove and insert it in
a different location.
( 1 2 [3 4 5] 6 ) becomes ( 1 2 6 3 4 5 )](https://image.slidesharecdn.com/group-9geneticalgorithms1-211127135346/75/Group-9-genetic-algorithms-1-30-2048.jpg)














































































