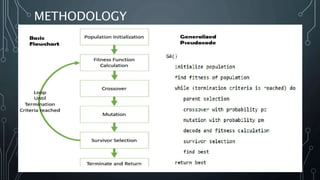
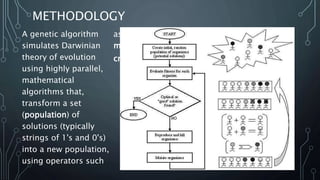
The document discusses genetic algorithms, which are optimization techniques inspired by Darwinian evolution and utilize processes like selection, crossover, and mutation to evolve solutions over generations. A numerical example illustrates the application of a genetic algorithm to solve the equation a +2b +3c +4d = 30, detailing steps including initialization, evaluation, selection, crossover, and mutation. The process continues iteratively to improve fitness until satisfactory results are achieved.






![STEP#2 | EVALUATION
• The values of the given population are put in the objective
function to calculate the individual function.
chromosomes
Genes (values) Objective function
a b c d ((a + 2b + 3c + 4d) - 30
1 12 5 23 8 F_obj[1] 93
2 2 21 18 3 F_obj[2] 80
3 10 4 13 14 F_obj[3] 83
4 20 1 10 6 F_obj[4] 46
5 1 4 13 19 F_obj[5] 94
6 20 5 17 1 F_obj[6] 55](https://image.slidesharecdn.com/genetic-algorithm-170615121726/85/Genetic-algorithm-8-320.jpg)
![STEP#3 | SELECTION
• The fittest chromosome have the highest probability of being
selected for the next generation. Compute fitness probability
by computing fitness of individual chromosome. To avoid the
“divide by zero” problem the value of F_obj is added by 1.
F_obj Values
Fitness ( 1/ (1+
F_obj))
Individual
Probability (P[i] =
Fitness[i] / Total)
cummulative
Probability
F_obj[1] 93 Fitness[1] 0.010638298 P[1] 0.125824361 C[1] 0.125824
F_obj[2] 80 Fitness[2] 0.012345679 P[2] 0.146018394 C[2] 0.271843
F_obj[3] 83 Fitness[3] 0.011904762 p[3] 0.140803452 C[3] 0.412646
F_obj[4] 46 Fitness[4] 0.021276596 P[4] 0.251648722 C[4] 0.664295
F_obj[5] 94 Fitness[5] 0.010526316 P[5] 0.124499894 C[5] 0.788795
F_obj[6] 55 Fitness[6] 0.017857143 p[6] 0.211205177 C[6] 1
Total
0.084548793](https://image.slidesharecdn.com/genetic-algorithm-170615121726/85/Genetic-algorithm-9-320.jpg)

![STEP#3 | CONTINUED
• We have calculated the
probabilities so that roulette
wheel criterion can be
implemented. It begins by
generating random number R
from 0-1 range.
• For next generation, criterion,
we create R[1] > P[1] & R[1] <
P[2]
then chromosome[2] is
selected
from this criterion, following
new population is
created.chromosome genes
new old a b c d
chromosom
e[1]
chromosom
e[2] 2 21 18 3
chromosom
e[2]
chromosom
e[3] 10 4 13 14
chromosom
e[3]
chromosom
e[1] 12 5 23 8
chromosom
e[4]
chromosom
e[6] 20 5 17 1
chromosom
e[5]
chromosom
e[3] 10 4 13 14
chromosom
e[6]
chromosom
e[4] 20 1 10 6](https://image.slidesharecdn.com/genetic-algorithm-170615121726/85/Genetic-algorithm-11-320.jpg)

![STEP#4 | CONTINUED
• Chromosome K is selected as parent if R[k] < pc, lets suppose pc
= 25% . This means chromosome[k] would be selected for
crossover if R[k] < 0.25
• We have 6 randomly generated data points
• From the given data, chromosome[1,4,5] is
selected for crossover because it meets the
criterion. All 3 combinations for crossover.
• After chromosome selection, the next is the
position of crossover. It is done by generating
random numbers from 1--- ( chromosome length -1)
that is from (1-3)
• Lets suppose C[1] = 1, C[2] = 1, C[3] = 2 are the random numbers
generated from the above criterion. What this means that during
crossover in chromosome 1&2, swapping would be done after first](https://image.slidesharecdn.com/genetic-algorithm-170615121726/85/Genetic-algorithm-13-320.jpg)


![ITERATION
• Finishing mutation process then we have one iteration or one
generation of the genetic algorithm. We can now evaluate the
objective function after one generation:
• As can be seen, clearly the objective and fitness function has
improved. This process is continued until best or desirable results
are achieved. For our case after 50 iterations
• Chromosome = [07; 05; 03; 01] This means that: a = 7, b = 5, c = 3,
d = 1 If we use the number in the problem equation a +2 b +3 c +4
chromosomes
genes objective function
a b c d ((a +2b+3c+4d)-30)
1 2 5 17 1 37
2 10 4 13 14 83
3 12 5 23 2 69
4 20 4 13 14 93
5 10 5 18 3 56
6 20 1 10 6 46](https://image.slidesharecdn.com/genetic-algorithm-170615121726/85/Genetic-algorithm-16-320.jpg)