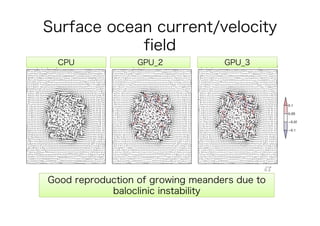
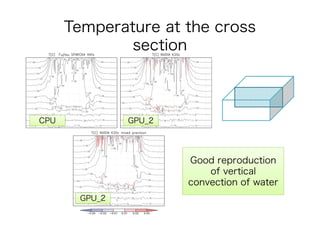
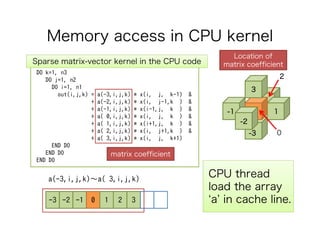
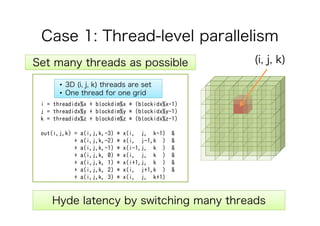
This document discusses the GPU acceleration of a non-hydrostatic ocean model called 'kinaco', highlighting its implementation, optimization strategies, and performance evaluation. The study demonstrates that the GPU-optimized model is approximately 4.7 times faster than the CPU version while maintaining acceptable accuracy for oceanic studies. Future work aims to apply mixed precision techniques to additional kernels and implement MPI for realistic experiments.














![Performance
CPU GPU_1 GPU_2 GPU_3
Speedup
(GPU_3)
all components 174.2 42.6 39.2 37.3 4.7
Poisson/Helmholtz
solver
36.8 15.8 12.4 10.5 3.5
others 137.4 26.9 26.8 26.8 5.1
Elapsed time[s]: CPU vs GPU
CPU : original CPU code
GPU_1: basic and typical implementation to the GPU
GPU_2: GPU_1 + memory optimization, hyde latency
GPU_3: GPU_2 + mixed precision preconditioning
GPU achieved 4.7 times speedup vs CPU
5hours (150 steps)](https://image.slidesharecdn.com/ihpces2016takateruyamagishi-170312050040/85/GPU-acceleration-of-a-non-hydrostatic-ocean-model-with-a-multigrid-Poisson-Helmholtz-solver-16-320.jpg)