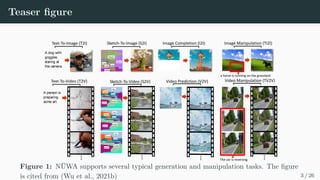
Download as PDF, PPTX




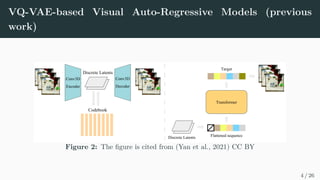
![VQ-VAE-based Visual Auto-Regressive Models (previous
work)
Encoder
Decoder
Discretize Recover
Text Tokenizer (sentence pieces)
Image Tokenizer
(Discrete AutoEncoder)
[ROI1] Text Token Text Token [BASE] [BOI1] [EOI1]
Image Token Image Token
Flattern
Input Text: Input Image:
Transformer (GPT)
z }| {
<latexit sha1_base64="WkmkOQqV4y/G2CwEGjey+GFekFc=">AAACAnicbVDLSgMxFM3UV62vUVfiJlgEV2VGi7osuHFZwT6gM5RMeqcNzWSGJCOUobjxV9y4UMStX+HOvzHTzkJbD4Qczrn3JvcECWdKO863VVpZXVvfKG9WtrZ3dvfs/YO2ilNJoUVjHstuQBRwJqClmebQTSSQKODQCcY3ud95AKlYLO71JAE/IkPBQkaJNlLfPvJiYweSUMi8kUry+9JJ9HTat6tOzZkBLxO3IFVUoNm3v7xBTNMIhKacKNVzzRw/I1IzymFa8VIFZv6YDKFnqCARKD+brTDFp0YZ4DCW5giNZ+rvjoxESk2iwFRGRI/UopeL/3m9VIfXfsZEkmoQdP5QmHKsY5zngQdMAtV8Ygihkpm/YjoiJg9tUquYENzFlZdJ+7zmXtScu3q1US/iKKNjdILOkIuuUAPdoiZqIYoe0TN6RW/Wk/VivVsf89KSVfQcoj+wPn8A712XuA==</latexit>
z }| {
<latexit sha1_base64="WkmkOQqV4y/G2CwEGjey+GFekFc=">AAACAnicbVDLSgMxFM3UV62vUVfiJlgEV2VGi7osuHFZwT6gM5RMeqcNzWSGJCOUobjxV9y4UMStX+HOvzHTzkJbD4Qczrn3JvcECWdKO863VVpZXVvfKG9WtrZ3dvfs/YO2ilNJoUVjHstuQBRwJqClmebQTSSQKODQCcY3ud95AKlYLO71JAE/IkPBQkaJNlLfPvJiYweSUMi8kUry+9JJ9HTat6tOzZkBLxO3IFVUoNm3v7xBTNMIhKacKNVzzRw/I1IzymFa8VIFZv6YDKFnqCARKD+brTDFp0YZ4DCW5giNZ+rvjoxESk2iwFRGRI/UopeL/3m9VIfXfsZEkmoQdP5QmHKsY5zngQdMAtV8Ygihkpm/YjoiJg9tUquYENzFlZdJ+7zmXtScu3q1US/iKKNjdILOkIuuUAPdoiZqIYoe0TN6RW/Wk/VivVsf89KSVfQcoj+wPn8A712XuA==</latexit>
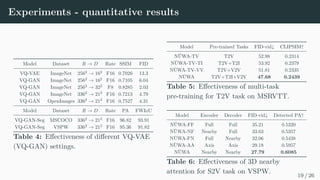
Figure 3: The figure is cited from (Ding et al., 2021)
5 / 26](https://image.slidesharecdn.com/slide-211201042003/85/NUWA-Visual-Synthesis-Pre-training-for-Neural-visUal-World-creAtion-6-320.jpg)

![VQGAN
zi = arg min
j∈{0,...,N−1}
||
RdB
z }| {
E(I)i −Bj||2
, (1)
ˆ
I = G(B[z]), (2)
LV
= ||
RH×W ×C
∈
I − ˆ
I||2
2 + ||sg[
Rh×w×dB
z}|{
E(I)] − B[z]||2
2 + ||E(I) − sg[B[z]]||2
2, (3)
LP
= ||CNN(I) − CNN(ˆ
I)||2
2, (4)
LG
= logD(I) + log(1 − D(ˆ
I)), (5)
where dB
= 256, N = 12, 288, H = W ∈ {256, 336}, h = w ∈ {16, 21, 32}.
8 / 26](https://image.slidesharecdn.com/slide-211201042003/85/NUWA-Visual-Synthesis-Pre-training-for-Neural-visUal-World-creAtion-9-320.jpg)

















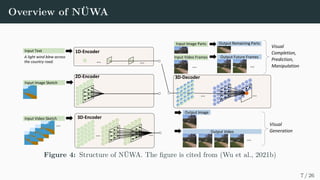
NÜWA is a unified multimodal pre-trained model that can generate and manipulate visual data like images and videos. It uses a 3D transformer encoder-decoder framework to handle text, images, and videos. A 3D Nearby Attention mechanism considers the nature of visual data and reduces computational complexity. NÜWA achieves state-of-the-art results on tasks like text-to-image generation, text-to-video generation, and video prediction. It also shows strong zero-shot capabilities for tasks like text-guided image and video manipulation.




































![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)






![[AAAI 2021] Vid-ODE: Continuous-Time Video Generation with Neural Ordinary Di...](https://cdn.slidesharecdn.com/ss_thumbnails/2021aaaivid-ode20min-210401064554-thumbnail.jpg?width=640&height=640&fit=bounds)




















