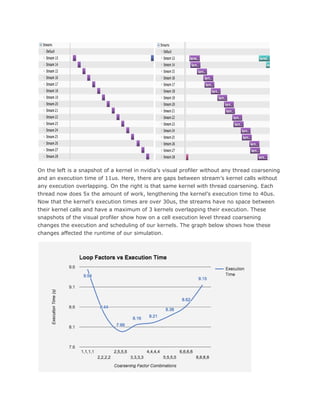
This document summarizes a project report on optimizing fracking simulations for GPU acceleration. The simulations model hydraulic fracturing and consist of three phases. The focus was on the second phase, which calculates interaction factors and stresses between grid cells and takes 80% of the CPU execution time. This phase was implemented on a GPU using techniques like finding parallelism at the cell and grid level, optimizing data transfers, memory access, and using streams to execute cells concurrently. These optimizations led to speedups of up to 56x compared to the CPU implementation.





![While exploring the optimization space of the application at hand we have make heavily use
of performance metrics including global memory throughput per kernel, floating point and
integer operations executed per kernel, instructions executed per cycle per kernel, cache
utilization per kernel, and achieved occupancy. Among these parameters, improving the
achieved occupancy per kernel has been our guiding metric. Occupancy per stream
multiprocessor can be improved by either decreasing the kernel latencies or by increasing
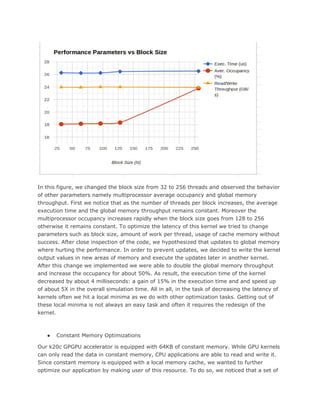
the throughput of the number of kernels we execute in the unit of time. In our initial
implementation our goal was to decrease the time execution latencies of the simulations
per cell. To pursue this goal we optimized parameters such as data traffic via the PCI bus,
number and shape of kernels, data layouts, usage of constant memory, degree of
parallelism among others. Next, because of the high number of cells, we pursued to
increase the cell throughput, the number of cells simulated in the unit of time. Our
guiding idea was to increase GPU occupancy at the expenses of increasing the cell
latencies, the time it takes to simulate the interactions over one cell. Here our goal was to
simulate multiple cell in parallel. To achieve this goal we relaxed the latencies per cell,
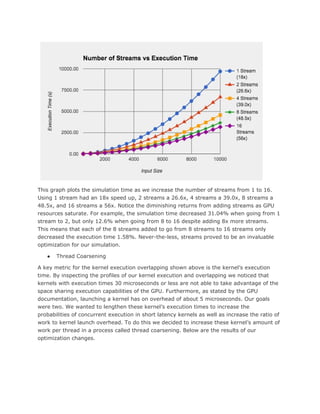
using techniques such as thread coarsening, and create multiple cuda streams. Eeach
stream been responsible for the simulation of a cell. This approach boosted the
performance of our application as we were able to achieve a speedup of up to 50X. Yet
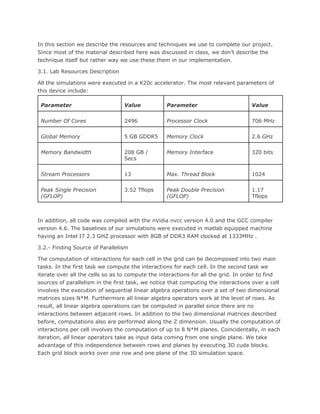
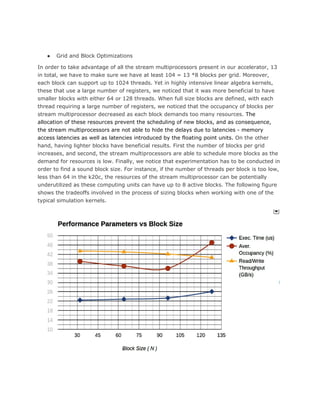
increasing cell throughput or decreasing the cell latencies are only possible by shaping the
the size of the blocks and the grids, shaping memory throughputs, increasing or
decreasing the number of floating point or integer operations and the alike. To the end,
exploring the optimization space of GPGPU applications is a complex task due in principle to
the drastic changes, the nonlinearities, present when one variable or more variables, for
instance the usage of registers per thread for instance, are altered.
5.- Related Works
The fracking algorithm we implemented is private property, confidential and unique.
However the basic structure is similar to a stencil all pairs n-body calculation which has
been heavily documented. Both our algorithm and an all pairs n-body algorithm share the
same element by element force calculations. Due the similar structures we found parallels
between our fracking implementation and the all pairs n-body implementations. For
example, [1] proposes that in dislocation dynamics n-body simulations shared memory is
not optimal when data overflows into register memory. We did not use shared memory for
this reason and due to little reuse of memory in our algorithm. [1] also removed
intermediate variables from global memory, choosing to calculate them on the fly and keep
them in register memory. We also implemented this strategy. [2] contrasts with [1],
suggesting to use tiles and shared memory. We decided to use [1]’s strategy because our
algorithm has very little memory reuse within our kernels. We did however implement
constant memory as was done in [2]. Many all pairs n-body calculations use one thread per
cell to calculate thousands in parallel, like [3] suggests. Each cell in our implementation
requires too many resources to launch enough single cell threads to fill the GPU. For this
reason we could not use the typical all pairs n-body 1 thread per cell structure. Another](https://image.slidesharecdn.com/ba1f17a8-d465-4ef4-a54c-5e5c069f8717-161218083042/85/FrackingPaper-11-320.jpg)
![strategy we used that is used in [4]’s n-body all pairs calculation is the reduction of
CPU-GPU memory traffic. Both our implementation and [4]’s move as much of the memory
to the GPU in the beginning of the algorithm as possible, and leave it there until all work
requiring that data is finished. Finally, we implemented thread coarsening which as shown
by [5] has minimal execution boost for n-body calculations. However, when we
implemented thread coarsening we achieved a 1.16X speedup due to differences in the
natures of our kernels and typical n-body kernels.
References.-
[1] Ferroni, Francesco, Edmund Tarleton, and Steven Fitzgerald. "GPU Accelerated
Dislocation Dynamics." GPU Accelerated Dislocation Dynamics. Journal of Computational
Physics, 1 Sept. 2014. Web. 10 Dec. 2015.
[2] Playne, D.P., M.G.B. Johnson, and K.A. Hawick. "Benchmarking GPU Devices with
N-Body Simulations." (n.d.): n. pag. Benchmarking GPU Devices with N-Body Simulations.
Massey University. Web. 10 Dec. 2015.
[3] Nyland, Lars, Mark Harris, and Jan Prins. "GPU Gems 3." - Chapter 31. Fast N-Body
Simulation with CUDA. NVIDIA Corporation, n.d. Web. 10 Dec. 2015.
[4] Burtscher, Martin, and Keshav Pingali. "An Efficient CUDA Implementation of the
Tree-Based Barnes Hut N-Body Algorithm." An Efficient CUDA Implementation of the
Tree-Based Barnes Hut N-Body (n.d.): n. pag.Parallel Scientific Computing. Southern
Methodist University, 2011. Web. 10 Dec. 2015.
[5] Magni, Alberto, Christophe Dubach, and Michael O'Boyle. A Large-Scale
Cross-Architecture Evaluation of Thread-Coarsening. IEEE Xplore. Univ. of Edinburgh,
Edinburgh, UK, n.d. Web. 10 Dec. 2015.](https://image.slidesharecdn.com/ba1f17a8-d465-4ef4-a54c-5e5c069f8717-161218083042/85/FrackingPaper-12-320.jpg)




























































