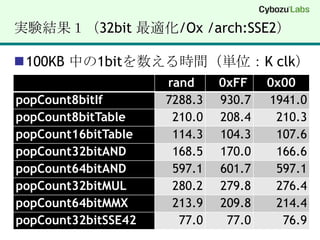
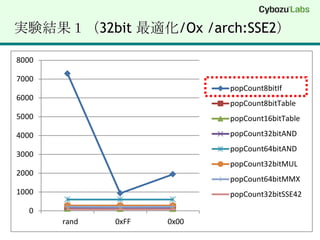
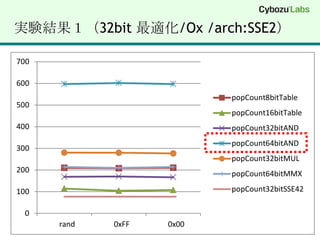
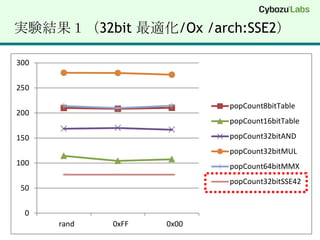
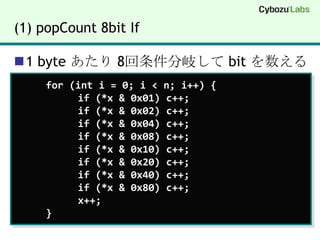
(1) popCount 8bitIf1 byte あたり 8回条件分岐して bit を数える for (int i = 0; i < n; i++) { if (*x & 0x01) c++; if (*x & 0x02) c++; if (*x & 0x04) c++; if (*x & 0x08) c++; if (*x & 0x10) c++; if (*x & 0x20) c++; if (*x & 0x40) c++; if (*x & 0x80) c++; x++;}
5.
(2) popCount 8bitTable256 byte のテーブルを作成して表引きstatic const char popTable8bit[] = { 0,1,1,2,1,2,2,3,1,2,2,3,2,3,3,4,1,2,2,3,2,3,3,4,2,3,3,4,3,4,4,5, 1,2,2,3,2,3,3,4,2,3,3,4,3,4,4,5,2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6, 1,2,2,3,2,3,3,4,2,3,3,4,3,4,4,5,2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6, 2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6,3,4,4,5,4,5,5,6,4,5,5,6,5,6,6,7, 1,2,2,3,2,3,3,4,2,3,3,4,3,4,4,5,2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6, 2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6,3,4,4,5,4,5,5,6,4,5,5,6,5,6,6,7, 2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6,3,4,4,5,4,5,5,6,4,5,5,6,5,6,6,7, 3,4,4,5,4,5,5,6,4,5,5,6,5,6,6,7,4,5,5,6,5,6,6,7,5,6,6,7,6,7,7,8};for (int i = 0; i < n; i++) { c += popTable8bit[(uint8)*x++];}
6.
(3) popCount 16bitTable64KB のテーブルを作成して表引きstatic char popTable16bit[256 * 256];void _popCount16bitTableInit(void) { for (int i = 0; i < 256; i++) { for (int j = 0; j < 256; j++) { popTable16bit[i*256 + j]= popTable8bit[i] + popTable8bit[j]; } }}for (int i = 0; i < n; i++) { c += popTable18bit[(uint16)*w++];}
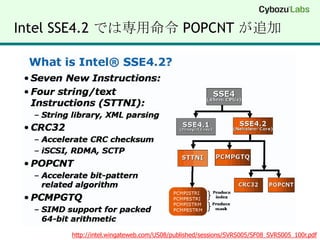
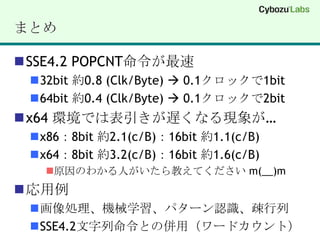
Intel SSE4.2 INSTRUCTIONSET- POPCNT#include "intrin.h"POPCNT int _mm_popcnt_u32(unsigned int a);POPCNT int64_t _mm_popcnt_u64(unsigned __int64 a);http://softwarecommunity.intel.com/isn/Downloads/Intel%20SSE4%20Programming%20Reference.pdf
17.
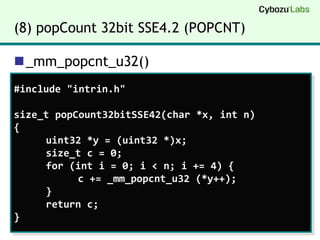
(8) popCount 32bitSSE4.2 (POPCNT)_mm_popcnt_u32()#include "intrin.h"size_tpopCount32bitSSE42(char *x, int n){ uint32 *y = (uint32 *)x;size_t c = 0; for (int i = 0; i < n; i += 4) { c += _mm_popcnt_u32 (*y++); } return c;}
18.
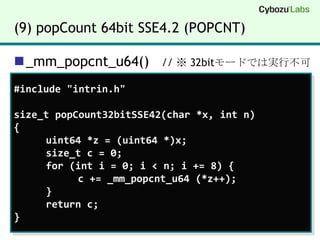
(9) popCount 64bitSSE4.2 (POPCNT)_mm_popcnt_u64() // ※ 32bitモードでは実行不可#include "intrin.h"size_t popCount32bitSSE42(char *x, int n){uint64 *z = (uint64 *)x;size_t c = 0; for (int i = 0; i < n; i += 8) { c += _mm_popcnt_u64 (*z++); } return c;}
19.
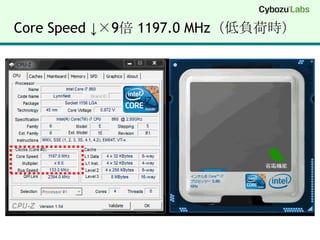
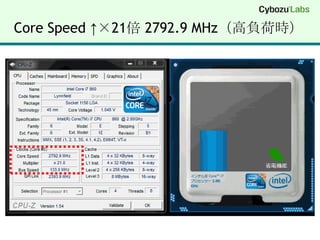
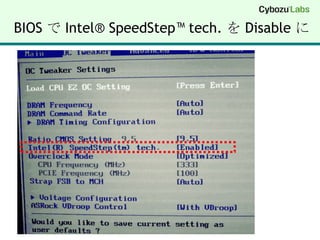
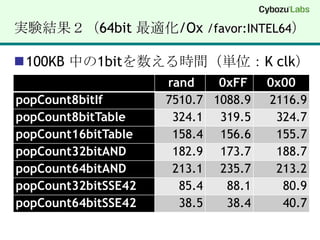
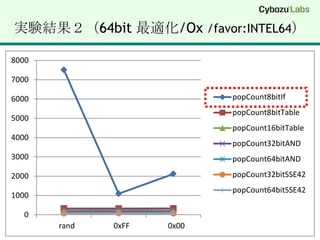
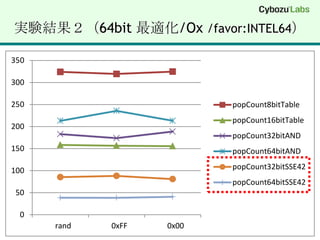
【実験環境】SSE4.2 (32bit/64bit)DELL VostroDT 430 (2009年に購入)Core i7 860 @ 2.80 GHz (45nm Lynnfield)MMX, SSE(1, 2, 3, 3S, 4.1, 4.2), EM64T, VT-xWindows 7 Professional (64bit)Visual Studio 2008 (x64) 64bit C/C++ for amd64Visual Studio 2008 (x86) 32bit C/C++ for 80x86注意点最近の Core i5 / Core i7 の省エネ機能Turbo Boost の機能で負荷に応じてクロックが変わるベンチマーク結果が不安定に




![(2) popCount 8bit Table256 byte のテーブルを作成して表引きstatic const char popTable8bit[] = { 0,1,1,2,1,2,2,3,1,2,2,3,2,3,3,4,1,2,2,3,2,3,3,4,2,3,3,4,3,4,4,5, 1,2,2,3,2,3,3,4,2,3,3,4,3,4,4,5,2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6, 1,2,2,3,2,3,3,4,2,3,3,4,3,4,4,5,2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6, 2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6,3,4,4,5,4,5,5,6,4,5,5,6,5,6,6,7, 1,2,2,3,2,3,3,4,2,3,3,4,3,4,4,5,2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6, 2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6,3,4,4,5,4,5,5,6,4,5,5,6,5,6,6,7, 2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6,3,4,4,5,4,5,5,6,4,5,5,6,5,6,6,7, 3,4,4,5,4,5,5,6,4,5,5,6,5,6,6,7,4,5,5,6,5,6,6,7,5,6,6,7,6,7,7,8};for (int i = 0; i < n; i++) { c += popTable8bit[(uint8)*x++];}](https://image.slidesharecdn.com/x86x64-popcnt-110806033815-phpapp01/85/x86x64-SSE4-2-POPCNT-5-320.jpg)
![(3) popCount 16bit Table64KB のテーブルを作成して表引きstatic char popTable16bit[256 * 256];void _popCount16bitTableInit(void) { for (int i = 0; i < 256; i++) { for (int j = 0; j < 256; j++) { popTable16bit[i*256 + j]= popTable8bit[i] + popTable8bit[j]; } }}for (int i = 0; i < n; i++) { c += popTable18bit[(uint16)*w++];}](https://image.slidesharecdn.com/x86x64-popcnt-110806033815-phpapp01/85/x86x64-SSE4-2-POPCNT-6-320.jpg)




![(6) popCount 64bit MMX + SSE (psadbw)__asm { MOVD MM0, [v+0] ;v_lowPUNPCKLDQ MM0, [v+4] ;v MOVQ MM1, MM0 ;v PSRLD MM0, 1 ;v >> 1 PAND MM0, [C55] ;(v >> 1) & 0x55555555 PSUBD MM1, MM0 ;w = v - ((v >> 1) & 0x55555555) MOVQ MM0, MM1 ;w PSRLD MM1, 2 ;w >> 2 PAND MM0, [C33] ;w & 0x33333333 PAND MM1, [C33] ;(w >> 2) & 0x33333333 PADDD MM0, MM1 ;x = (w & 0x33333333) + ((w >> 2) & 0x33333333) MOVQ MM1, MM0 ;x PSRLD MM0, 4 ;x >> 4 PADDD MM0, MM1 ;x + (x >> 4) PAND MM0, [C0F] ;y = (x + (x >> 4) & 0x0F0F0F0F) PXOR MM1, MM1 ;0 PSADBW MM0, MM1 ;sum all 8 bytes (Sum of Absolute Differences) MOVD EAX, MM0 ;result in EAX per calling convention EMMS ;clear MMX state MOV retVal, EAX ;store result }](https://image.slidesharecdn.com/x86x64-popcnt-110806033815-phpapp01/85/x86x64-SSE4-2-POPCNT-12-320.jpg)

![(7) popCount 32bit MUL (no MMX, no SSE) __asm { MOV EAX, [v] ;v MOV EDX, EAX ;v SHR EAX, 1 ;v >> 1 AND EAX, 055555555h ;(v >> 1) & 0x55555555 SUB EDX, EAX ;w = v - ((v >> 1) & 0x55555555) MOV EAX, EDX ;w SHR EDX, 2 ;w >> 2 AND EAX, 033333333h ;w & 0x33333333 AND EDX, 033333333h ;(w >> 2) & 0x33333333 ADD EAX, EDX ;x = (w & 0x33333333) + ((w >> 2) & 0x33333333) MOV EDX, EAX ;x SHR EAX, 4 ;x >> 4 ADD EAX, EDX ;x + (x >> 4) AND EAX, 00F0F0F0Fh ;y = (x + (x >> 4) & 0x0F0F0F0F) IMUL EAX, 001010101h ;y * 0x01010101 SHR EAX, 24 ;population count = (y * 0x01010101) >> 24 MOV retVal, EAX ;store result }](https://image.slidesharecdn.com/x86x64-popcnt-110806033815-phpapp01/85/x86x64-SSE4-2-POPCNT-14-320.jpg)