Downloaded 53 times




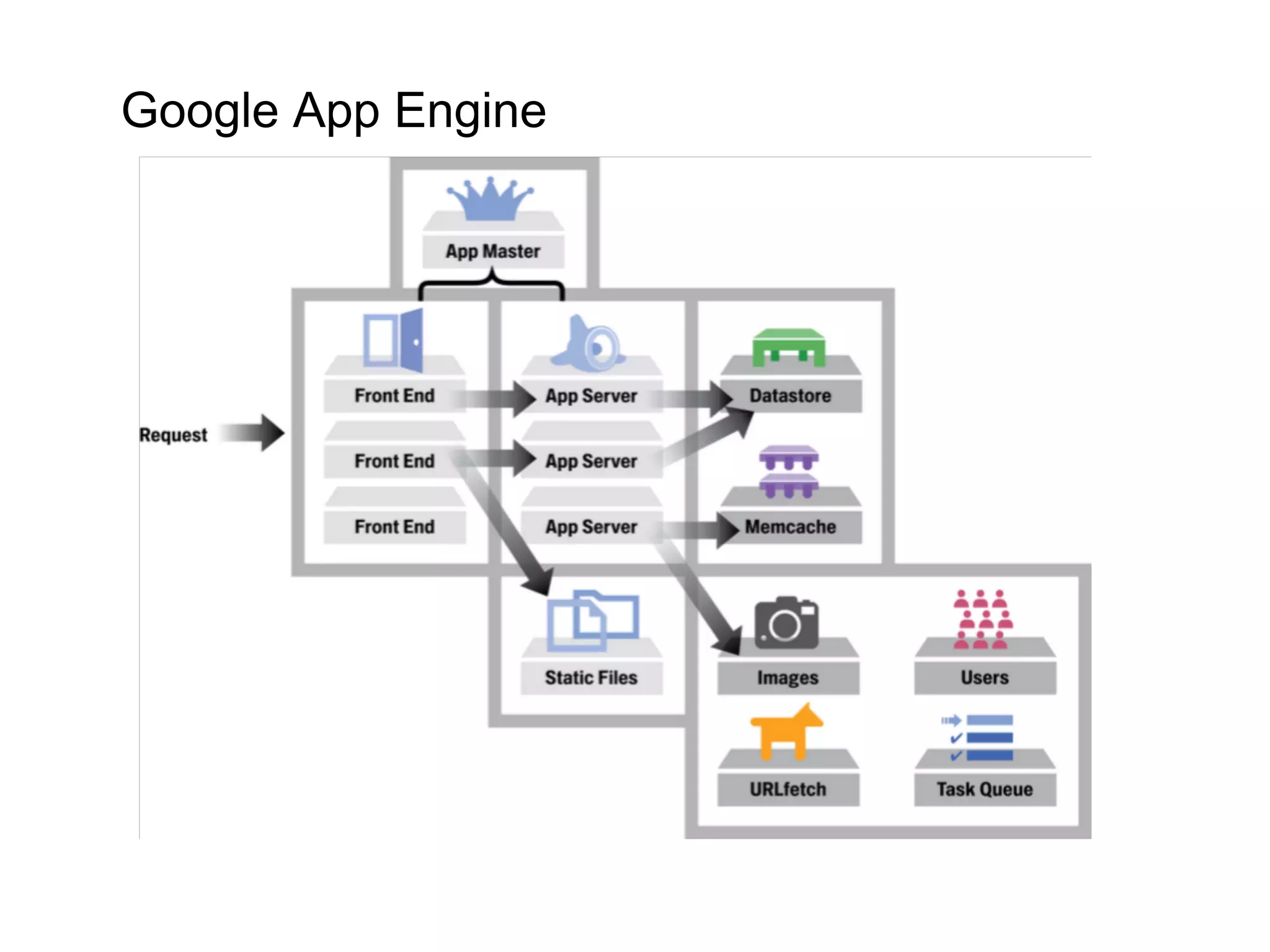
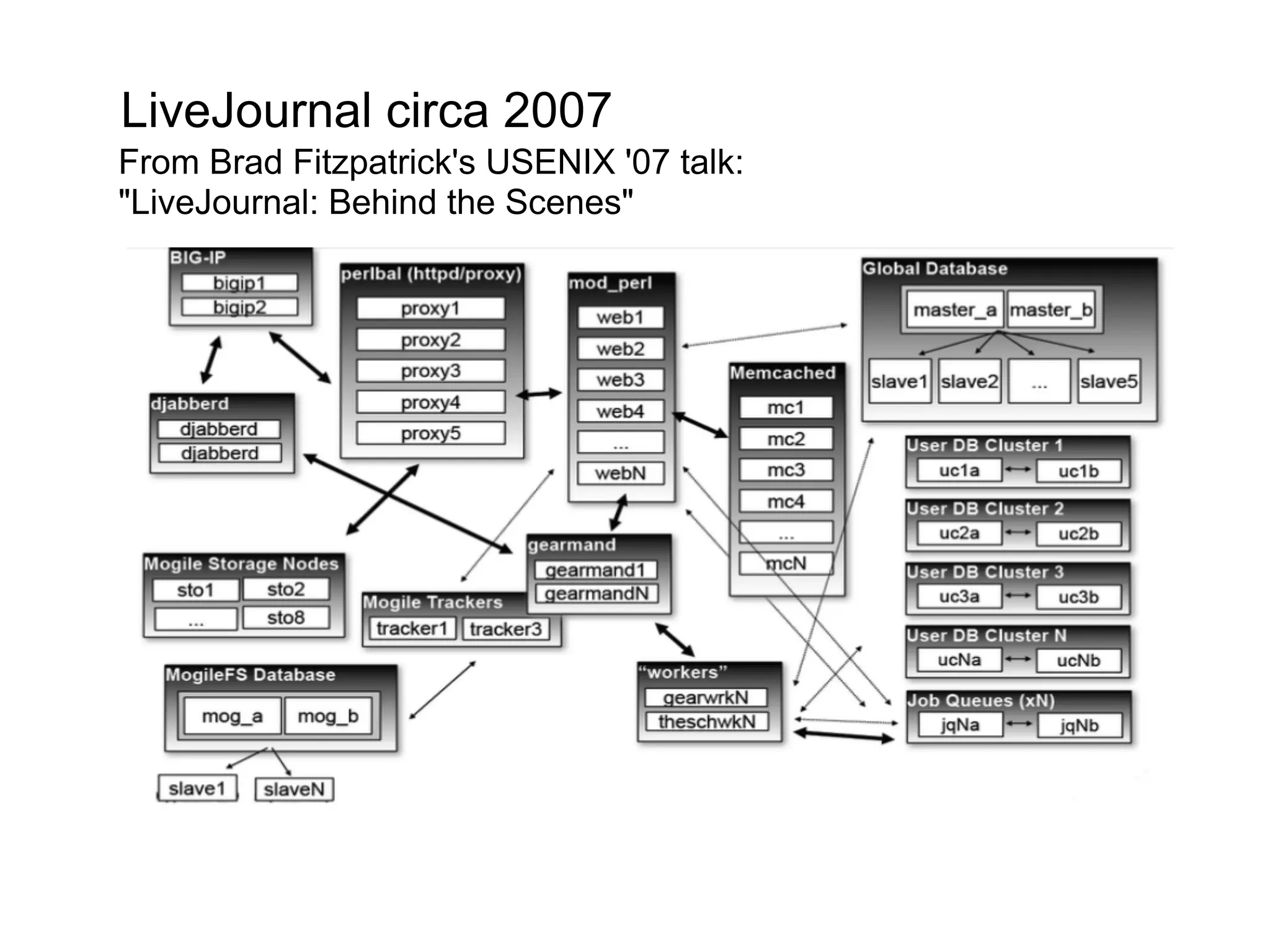
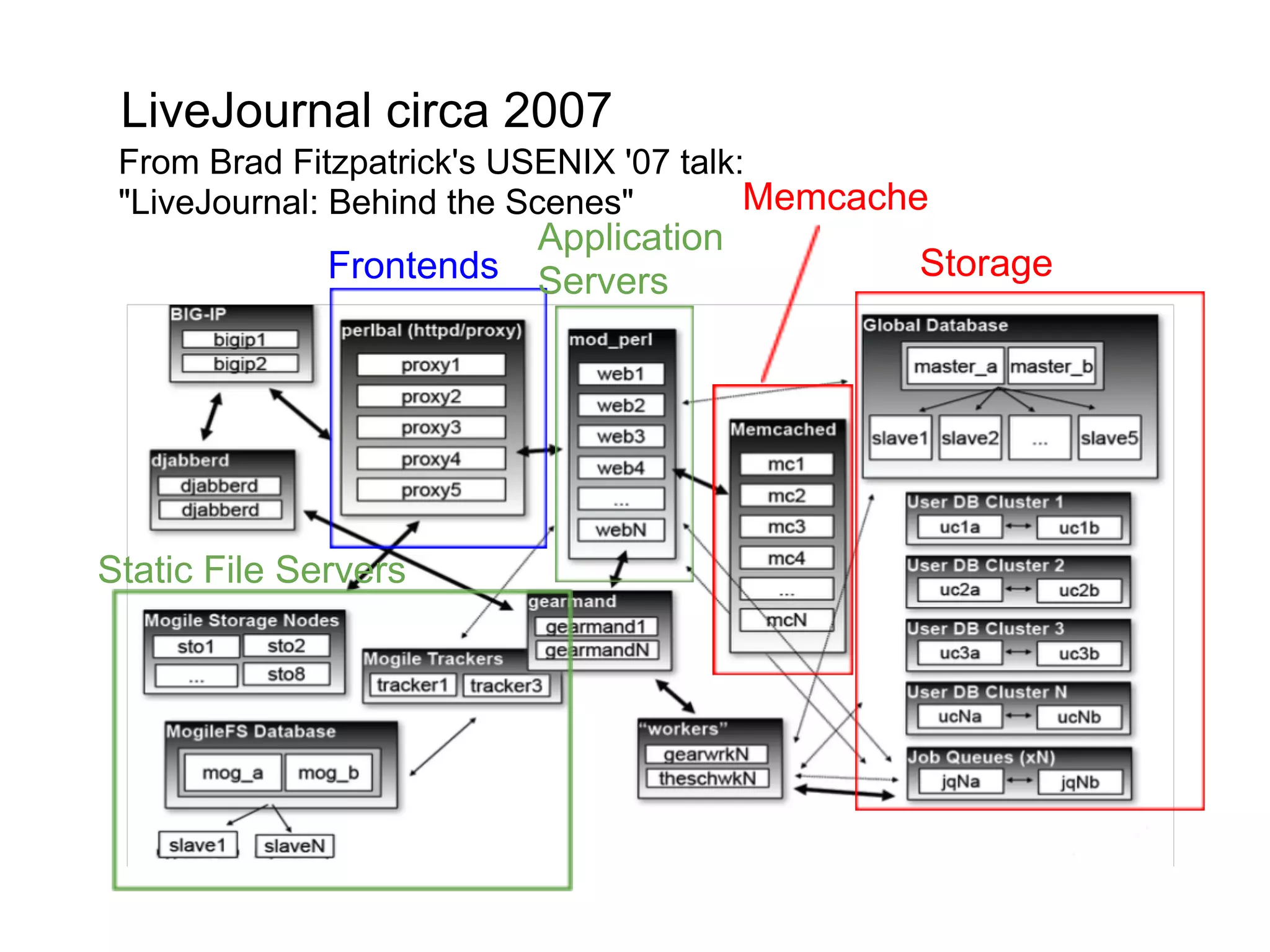
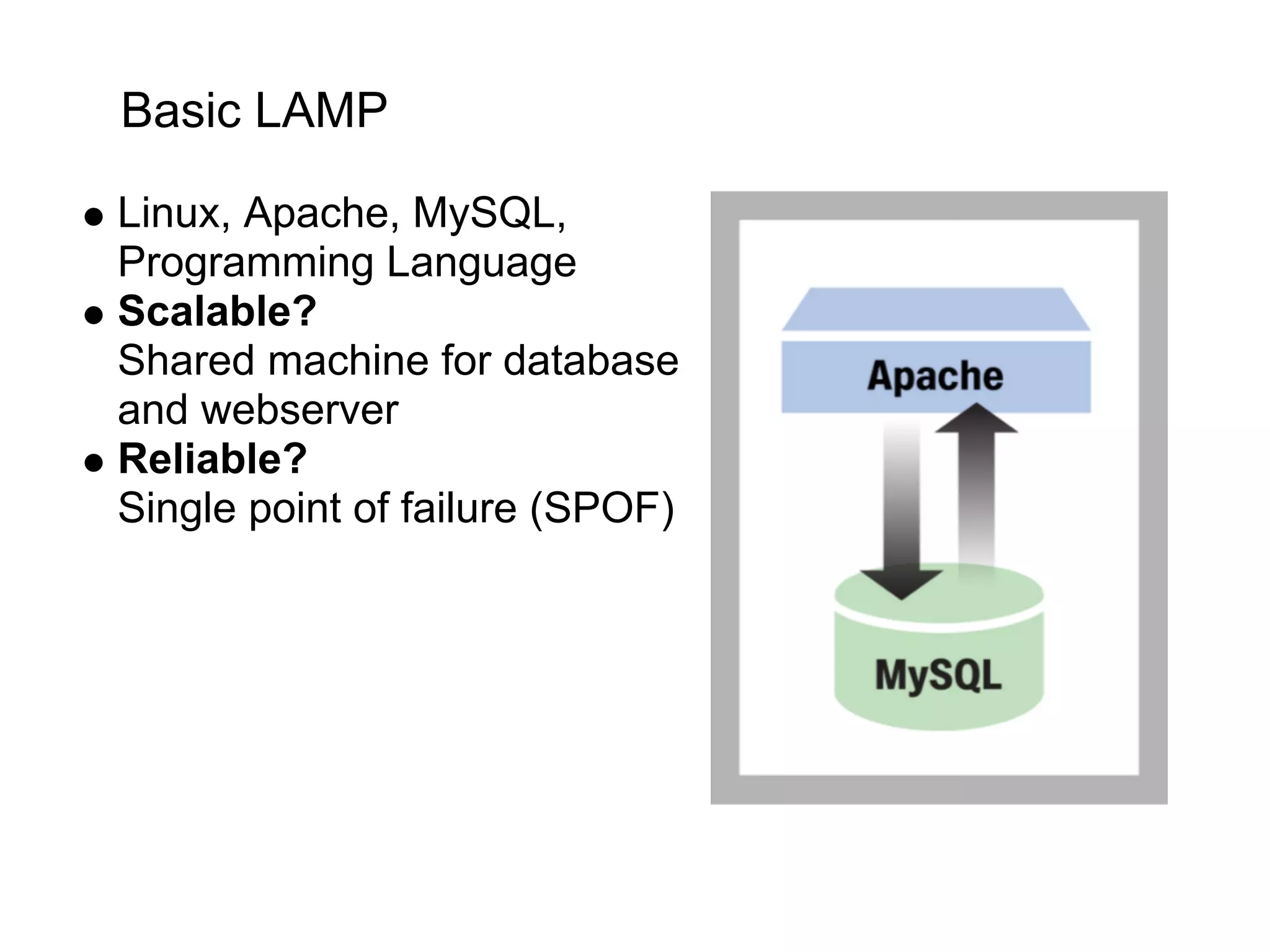
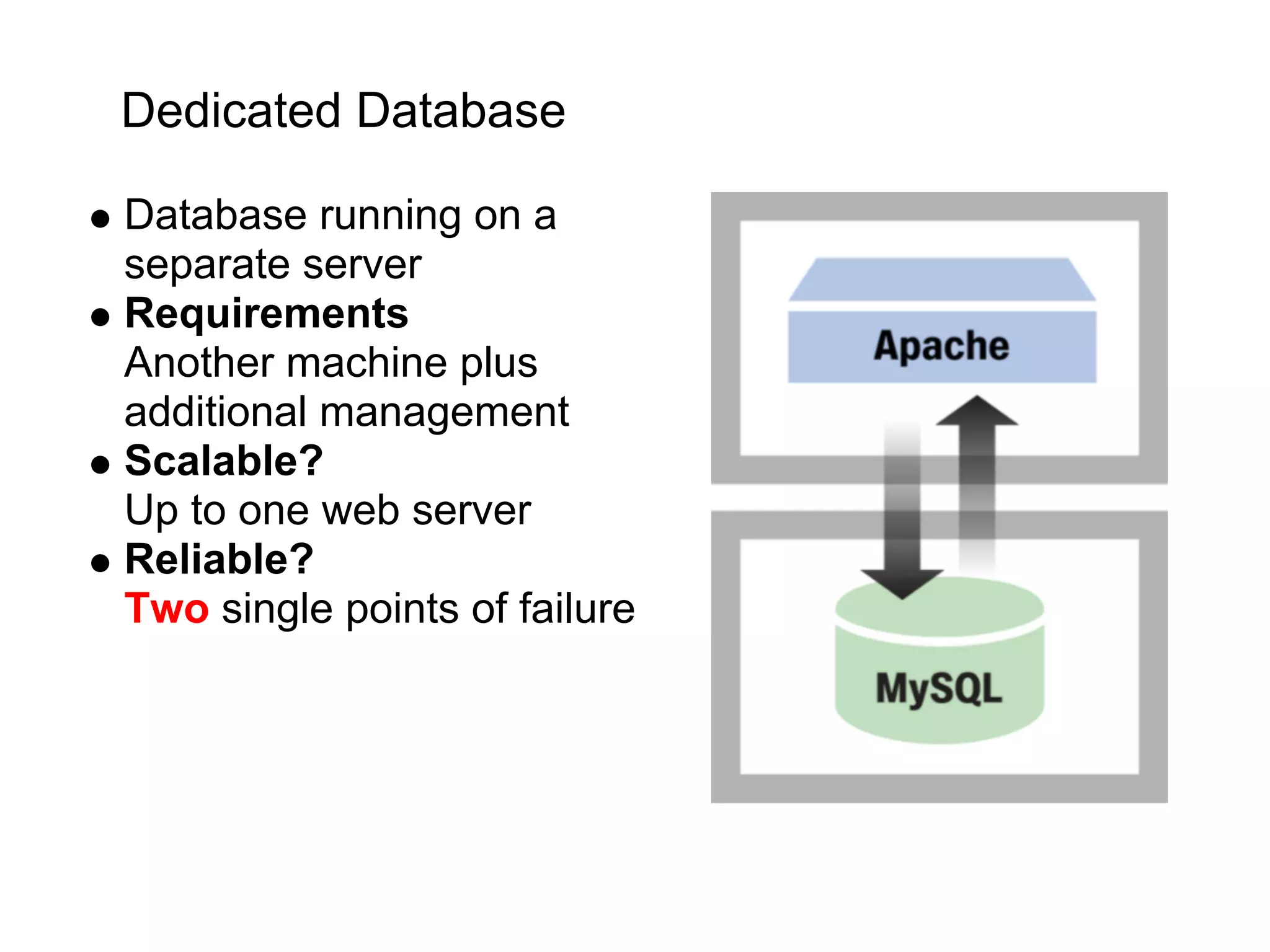
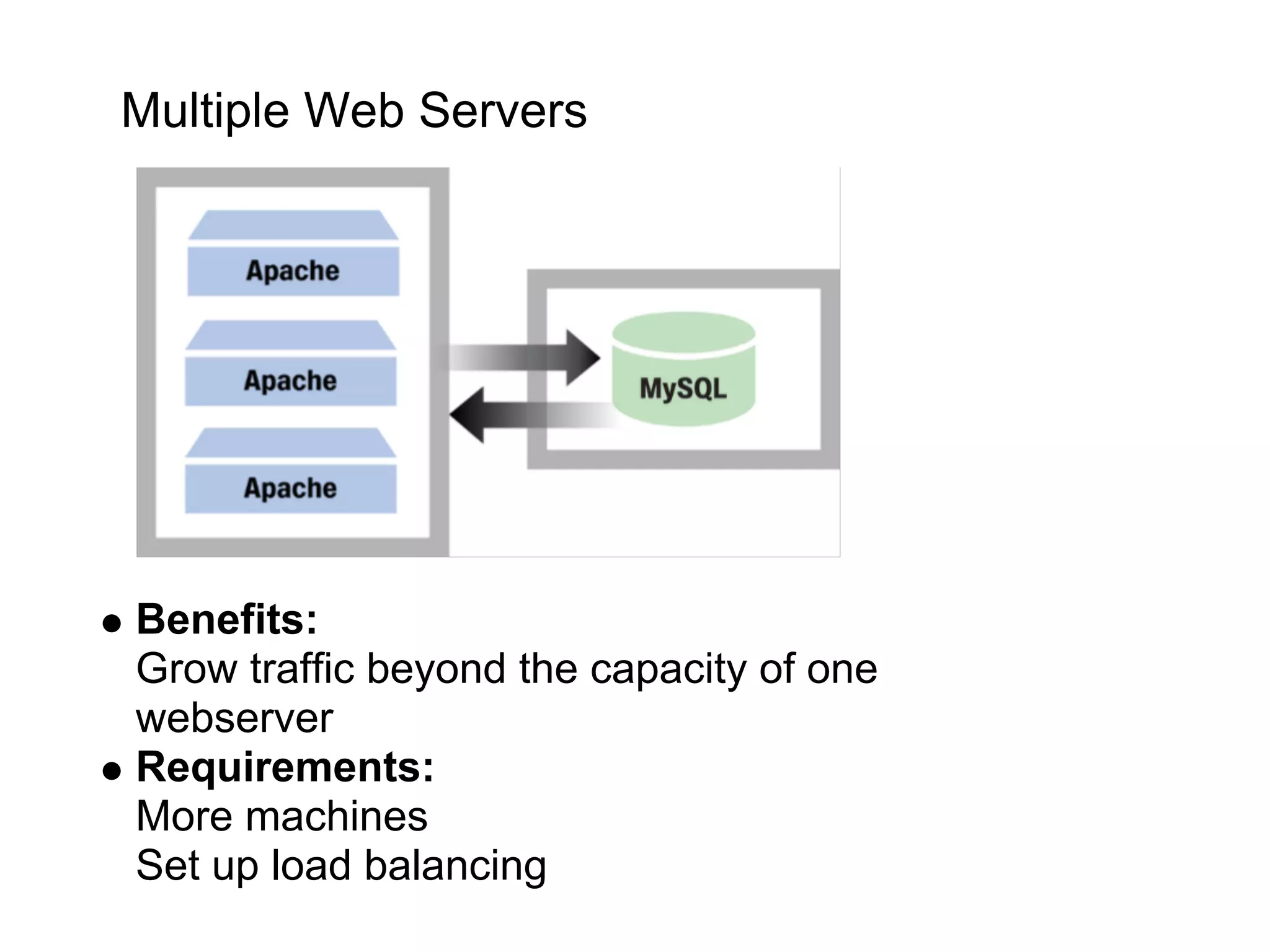
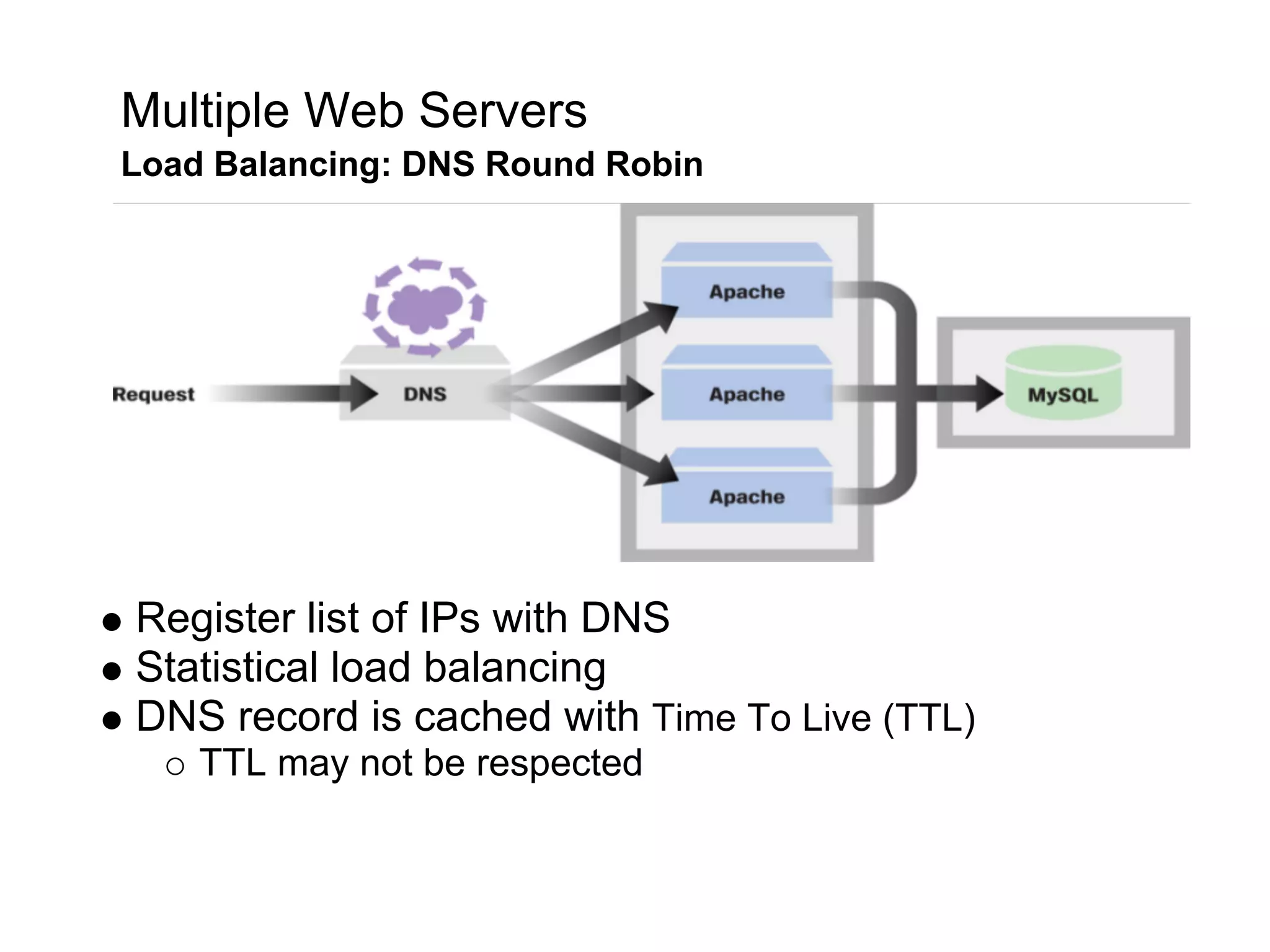
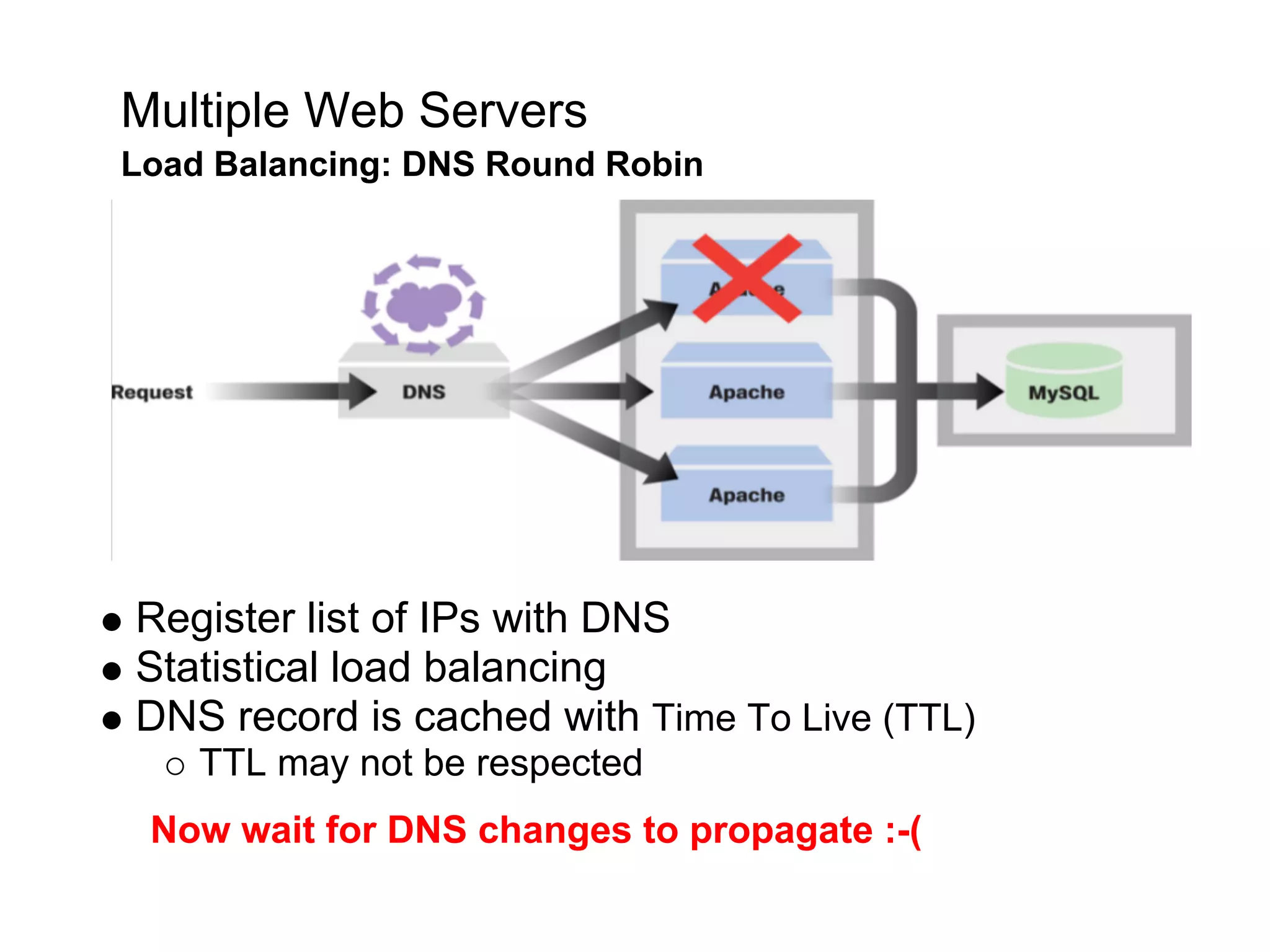
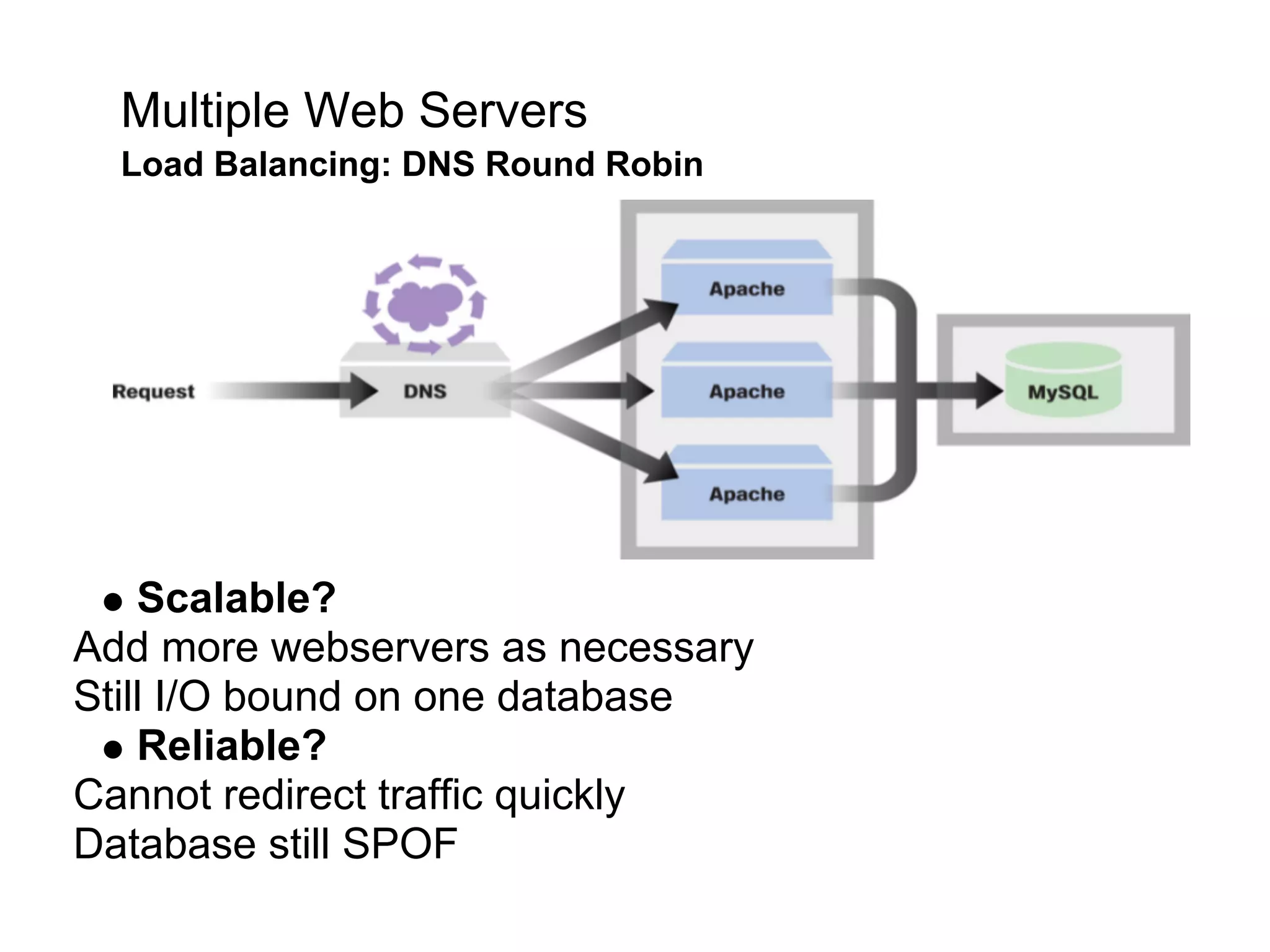
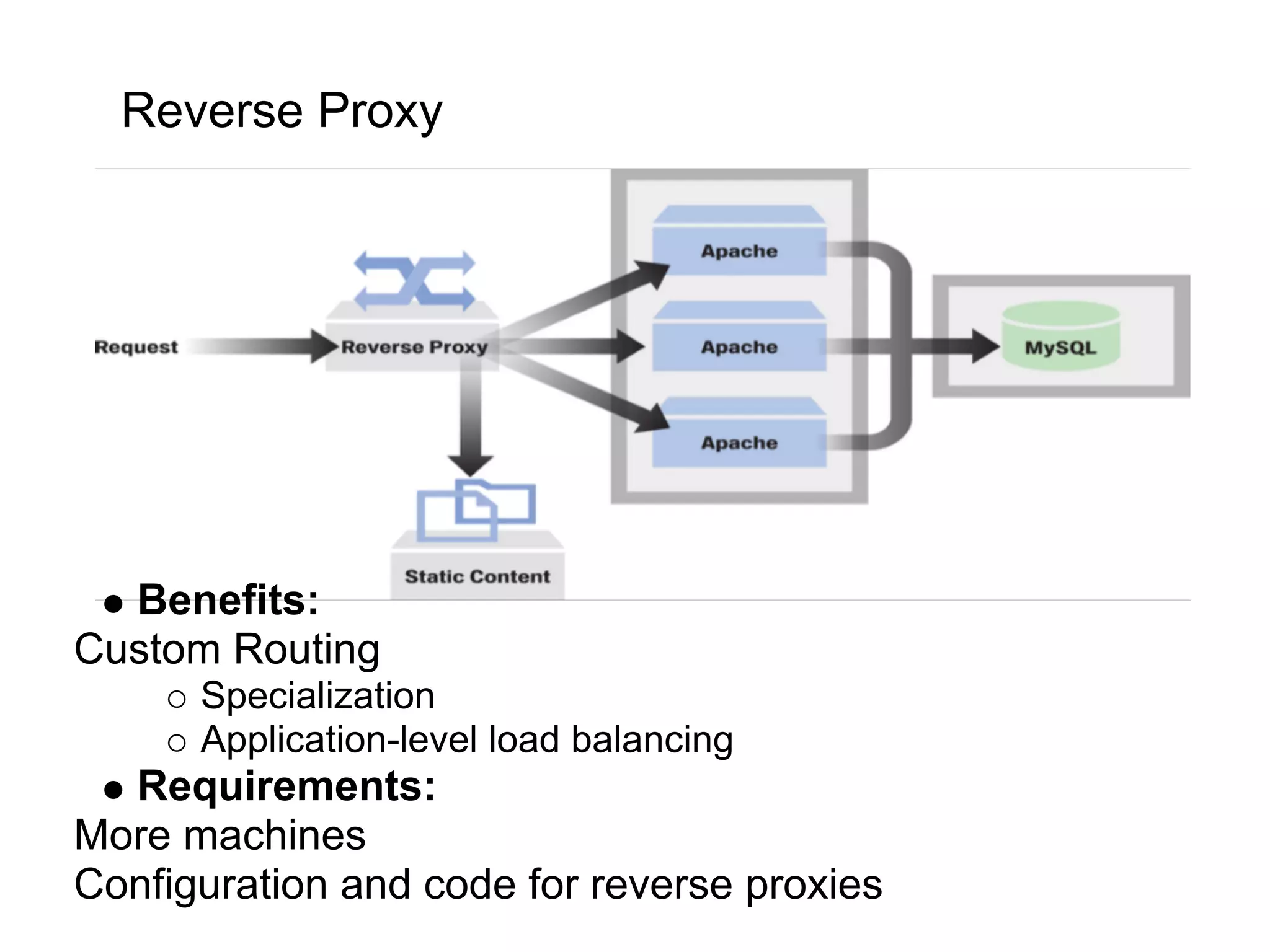

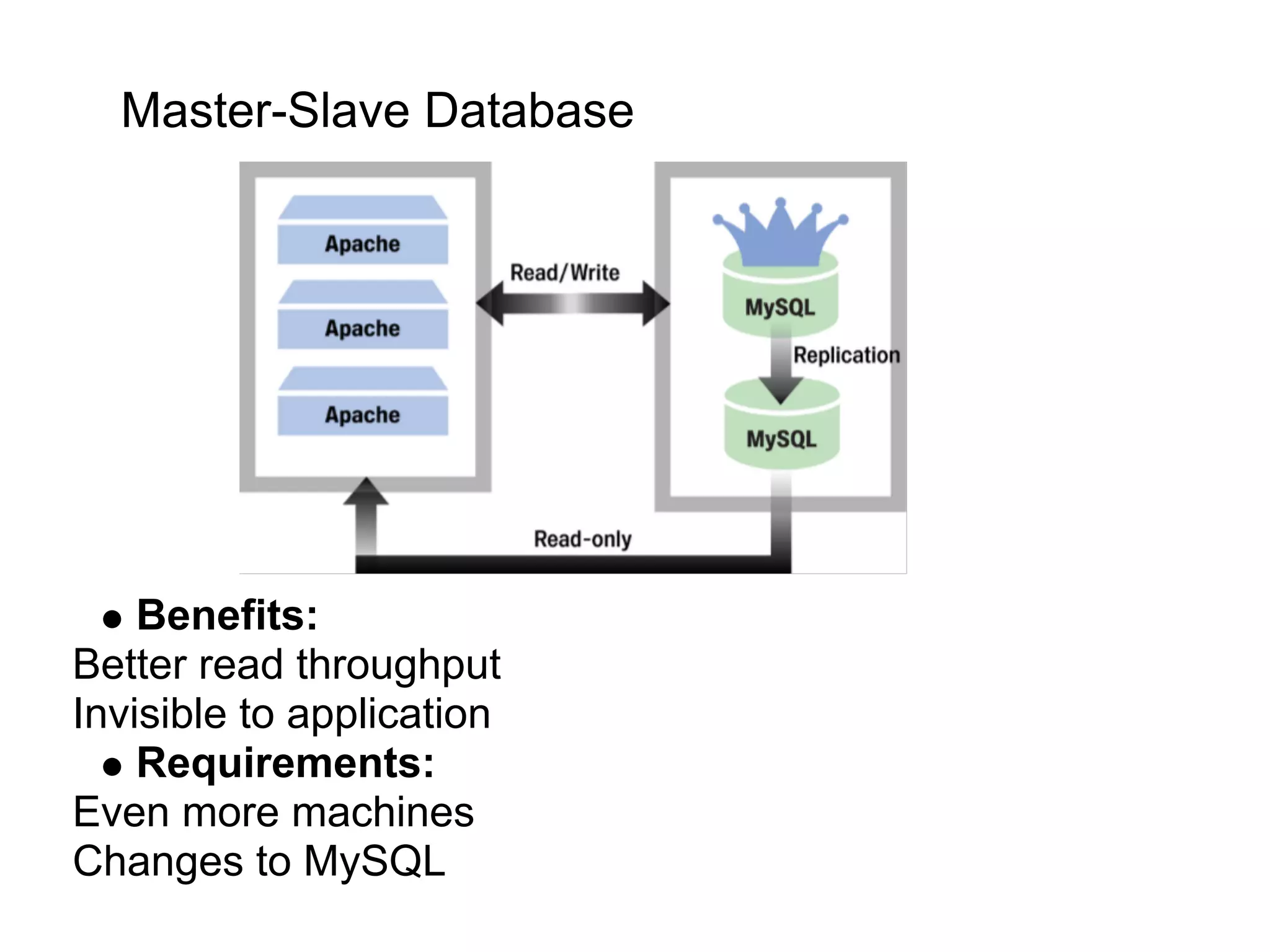
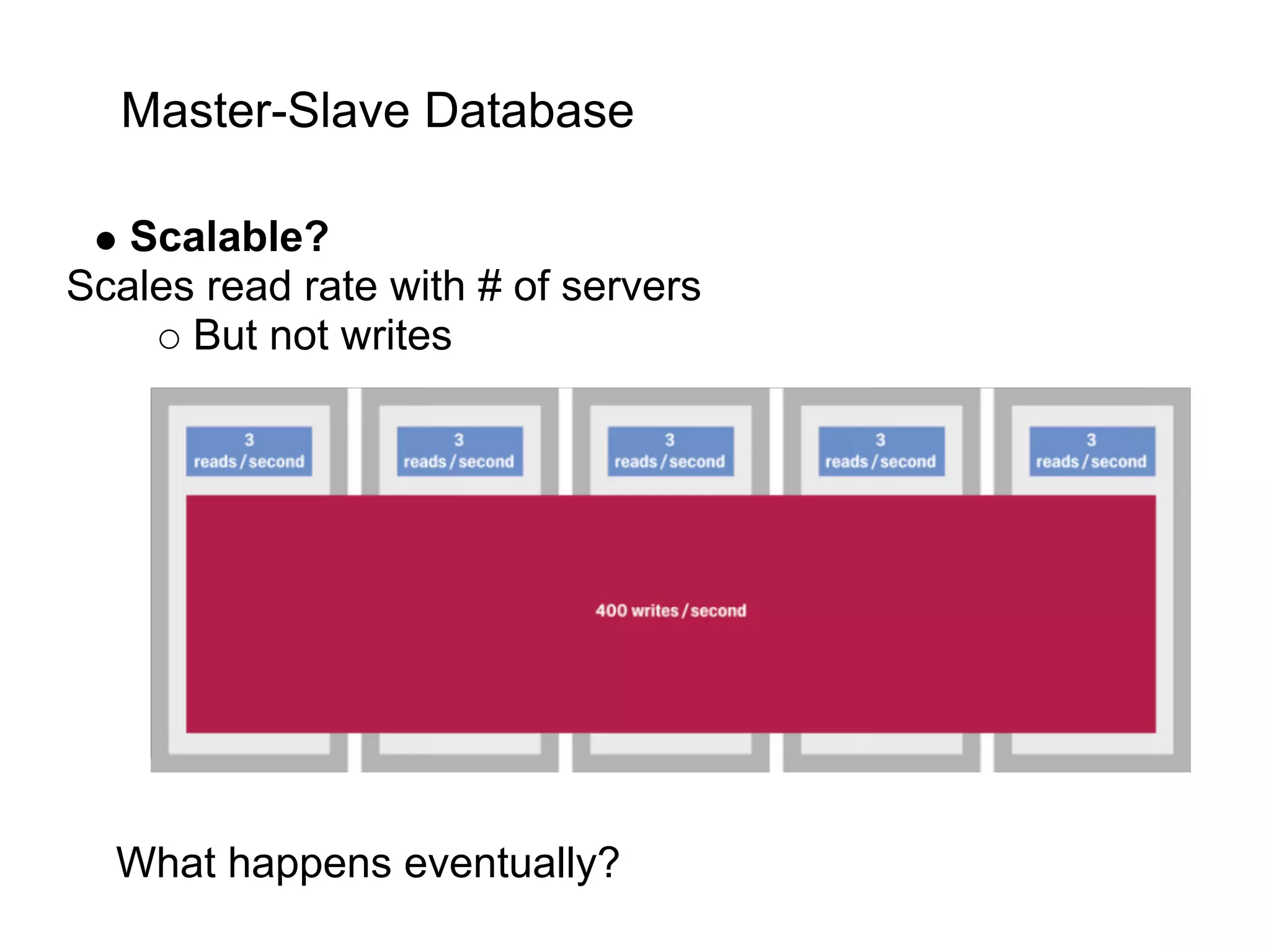

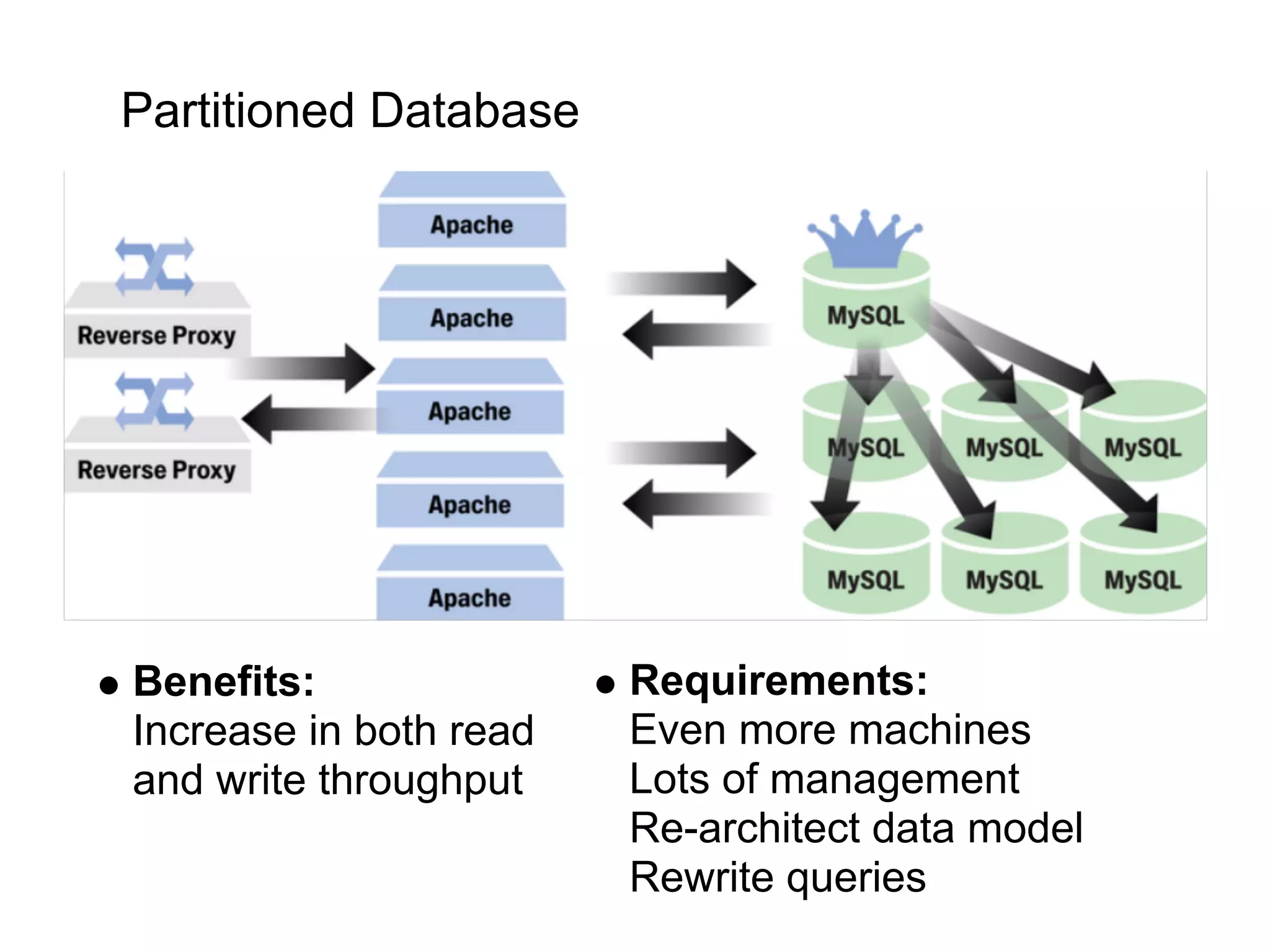
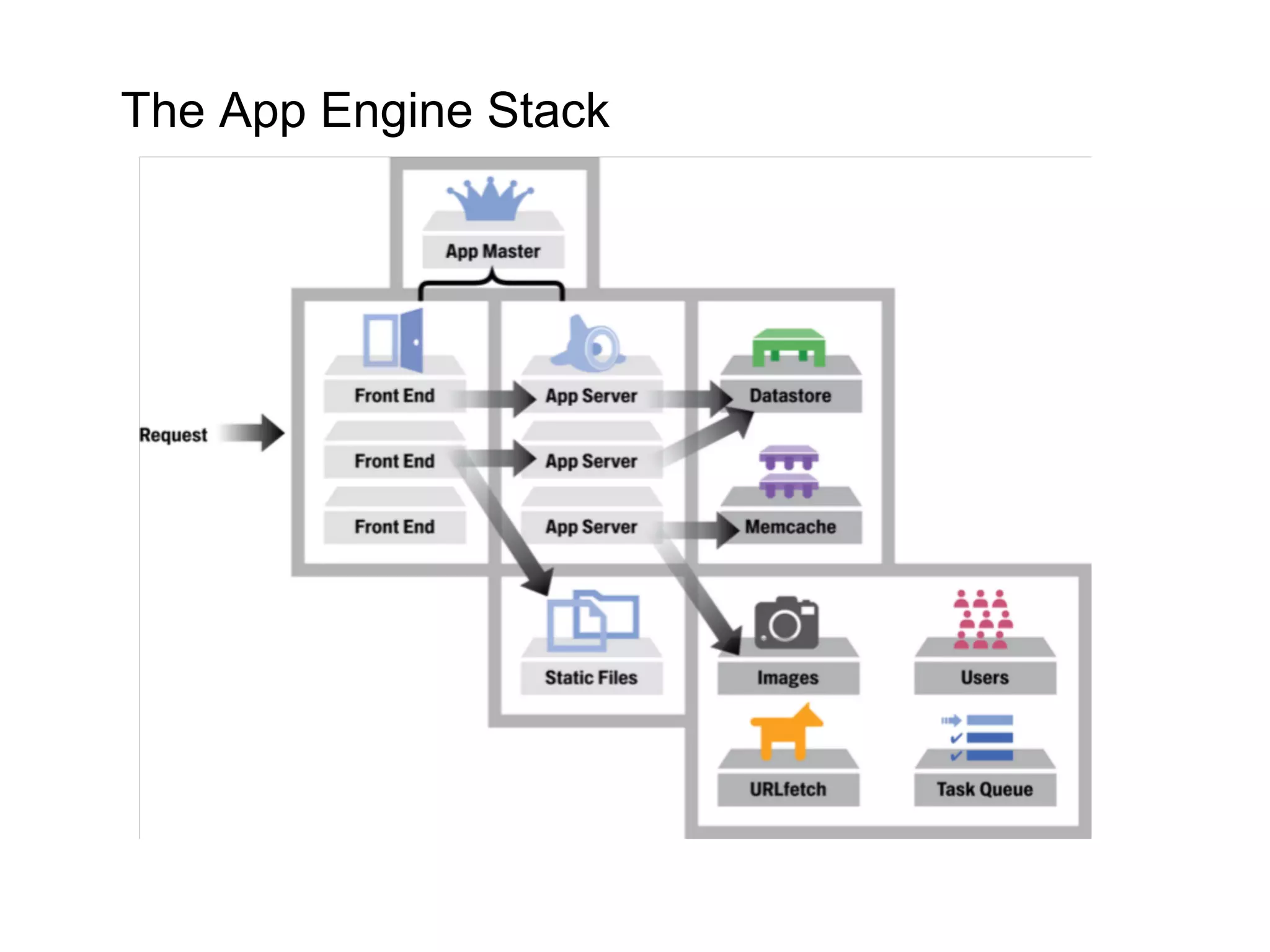



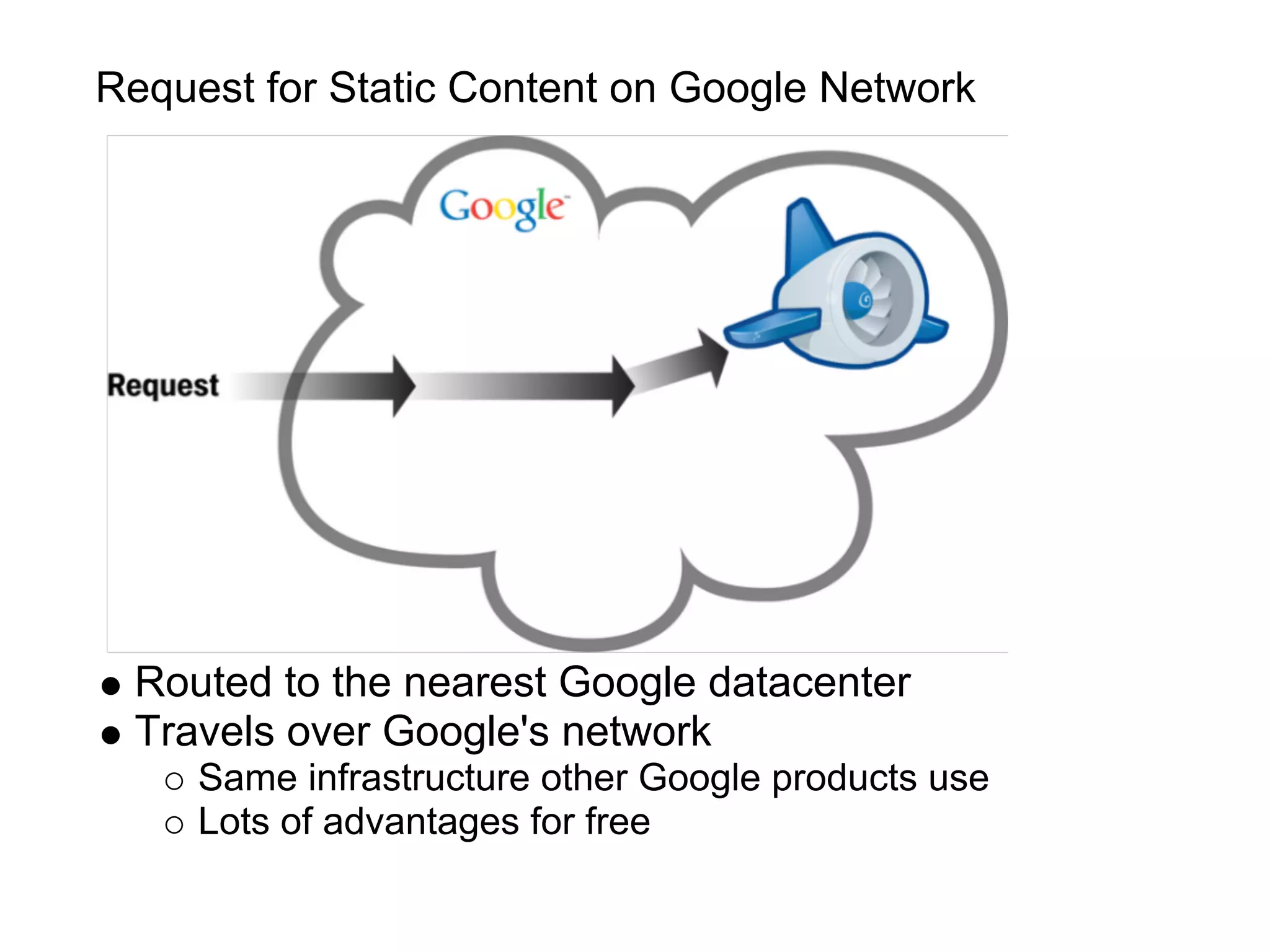
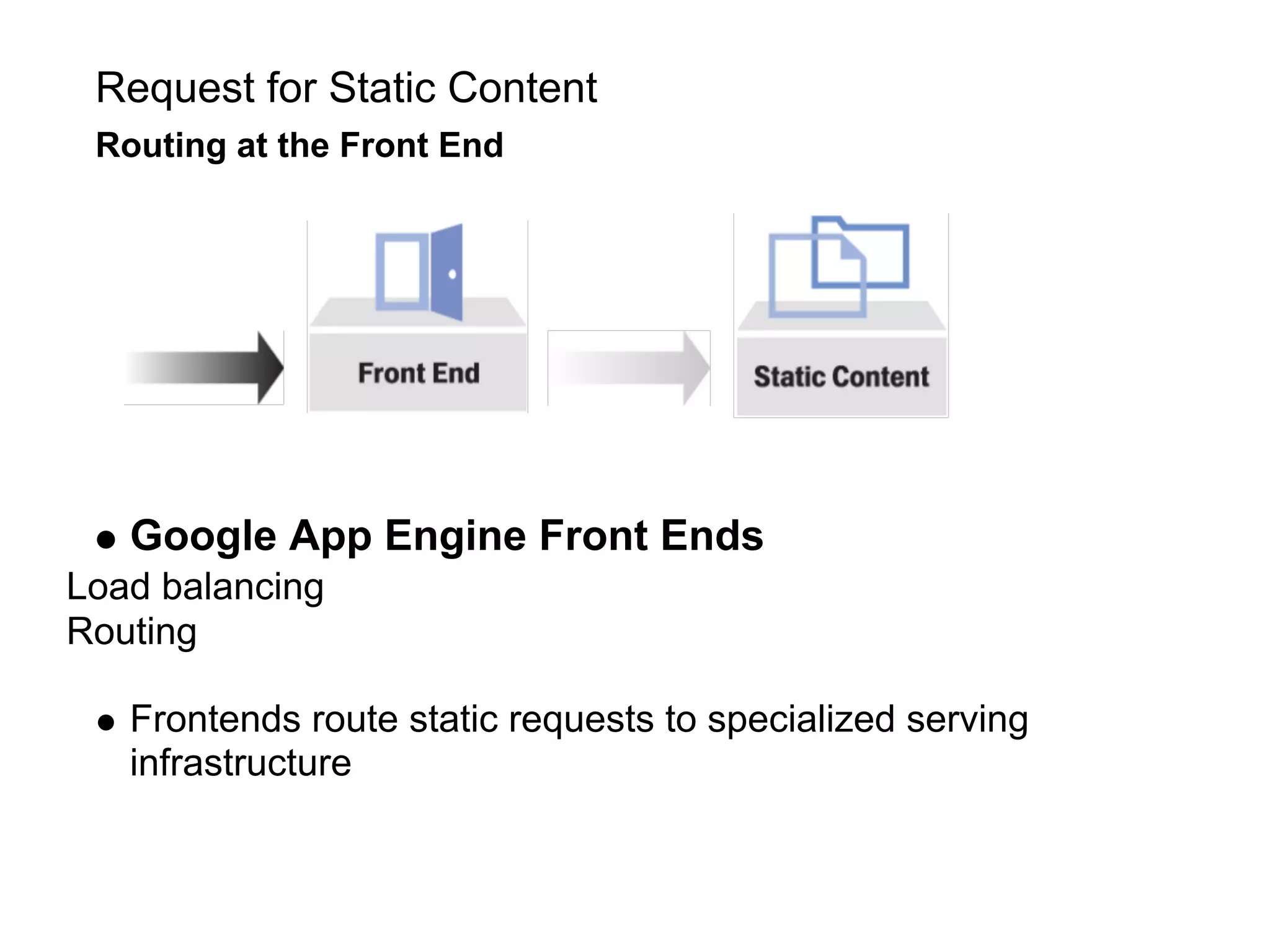
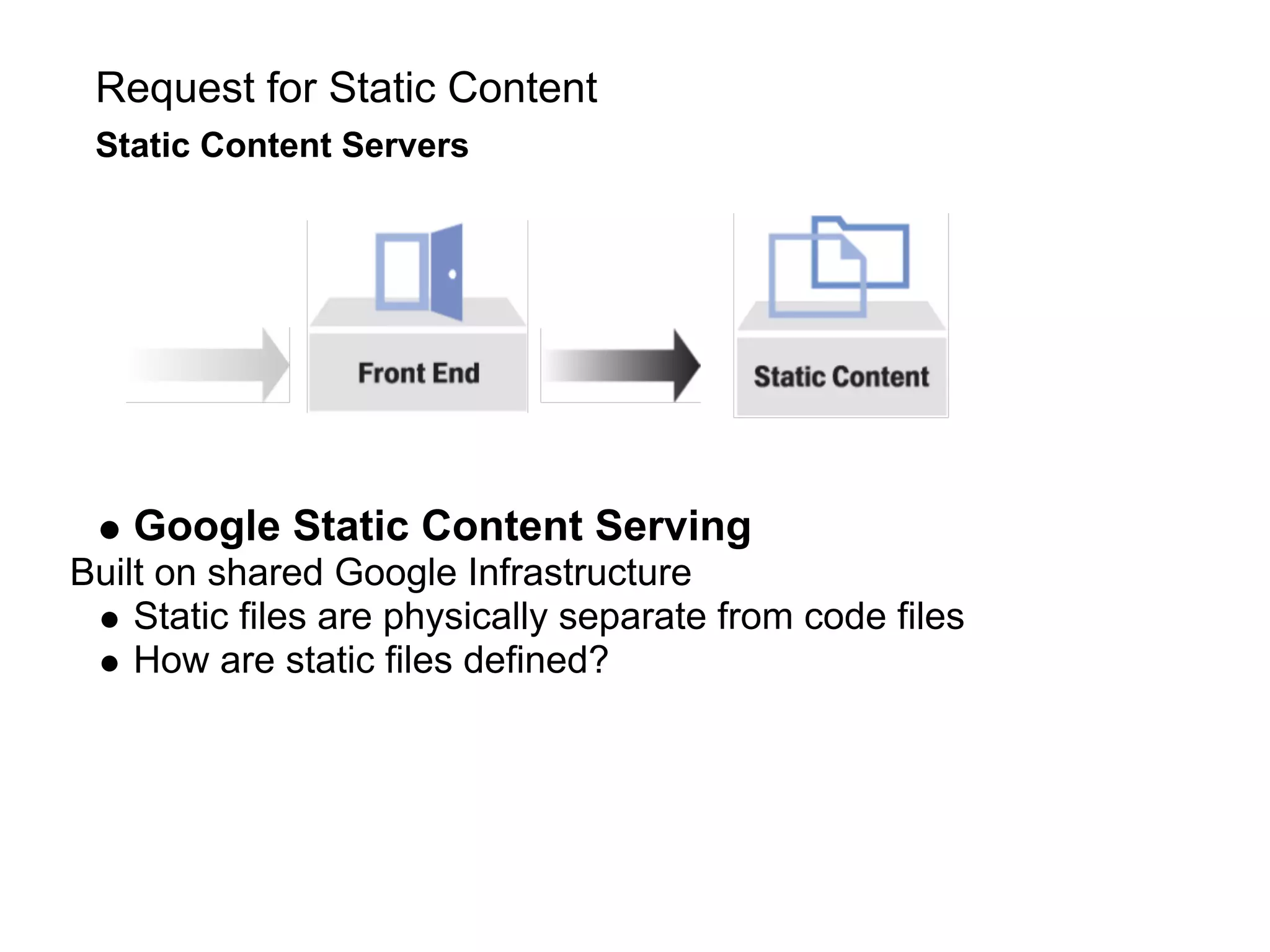



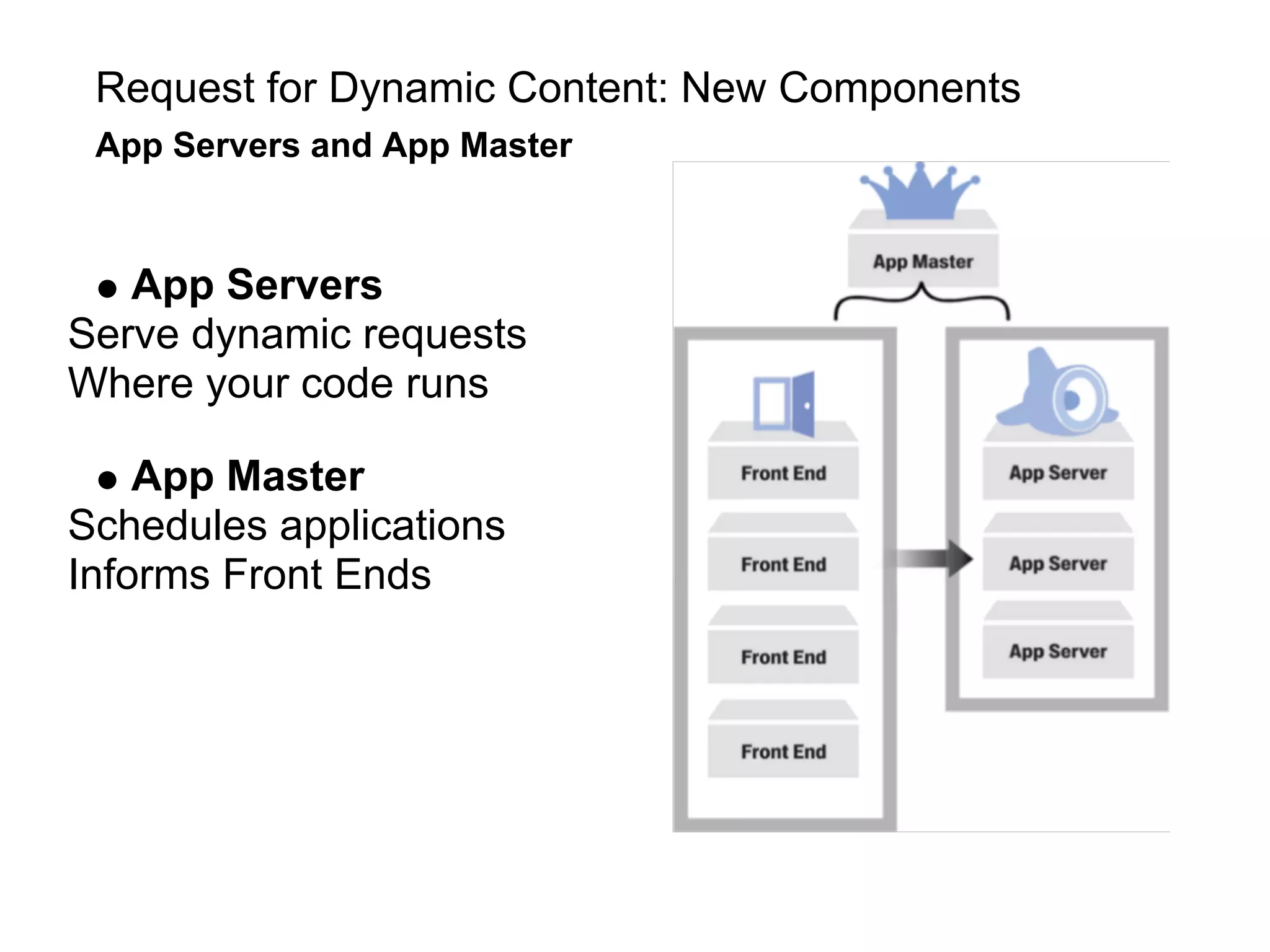

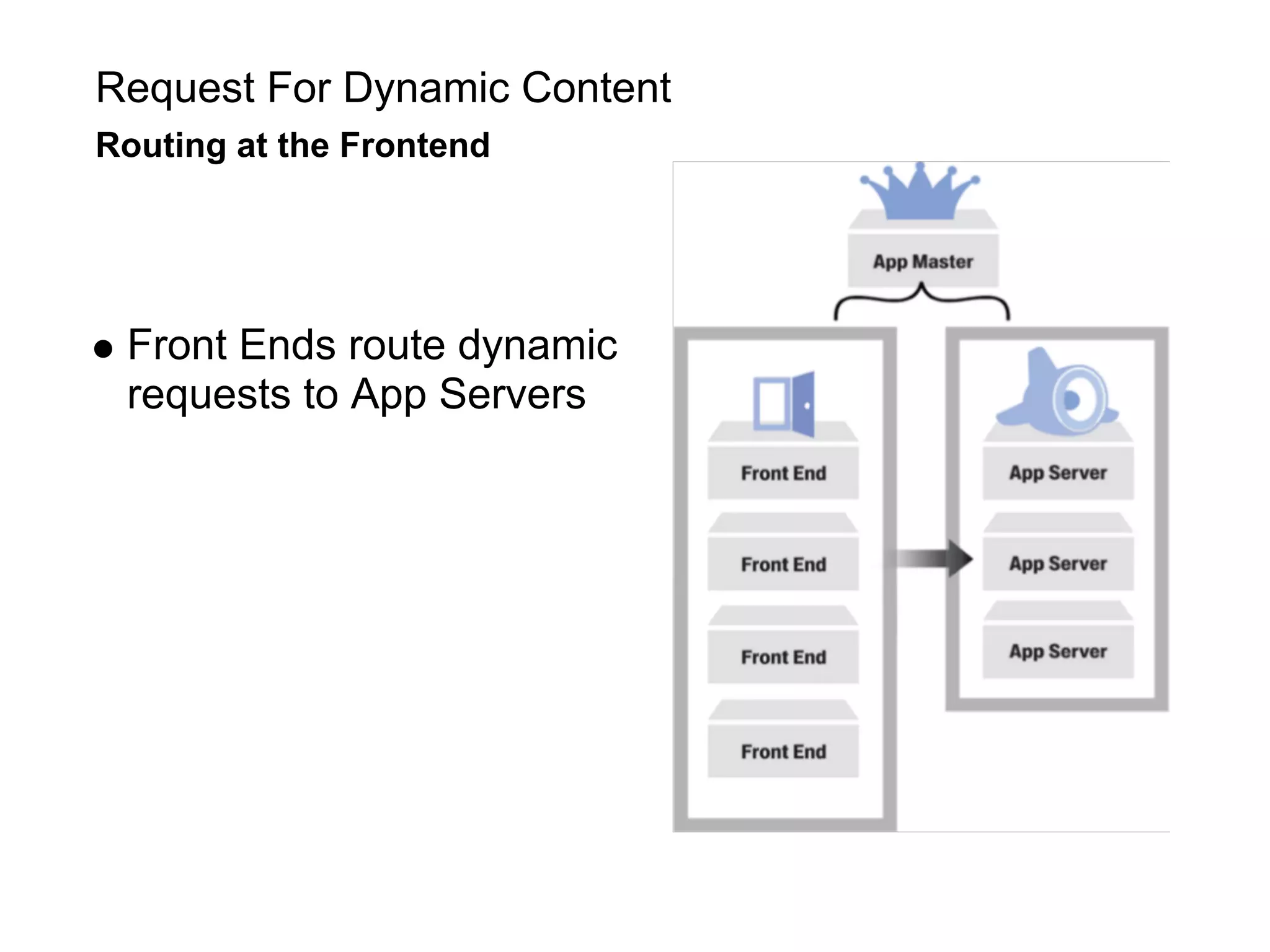


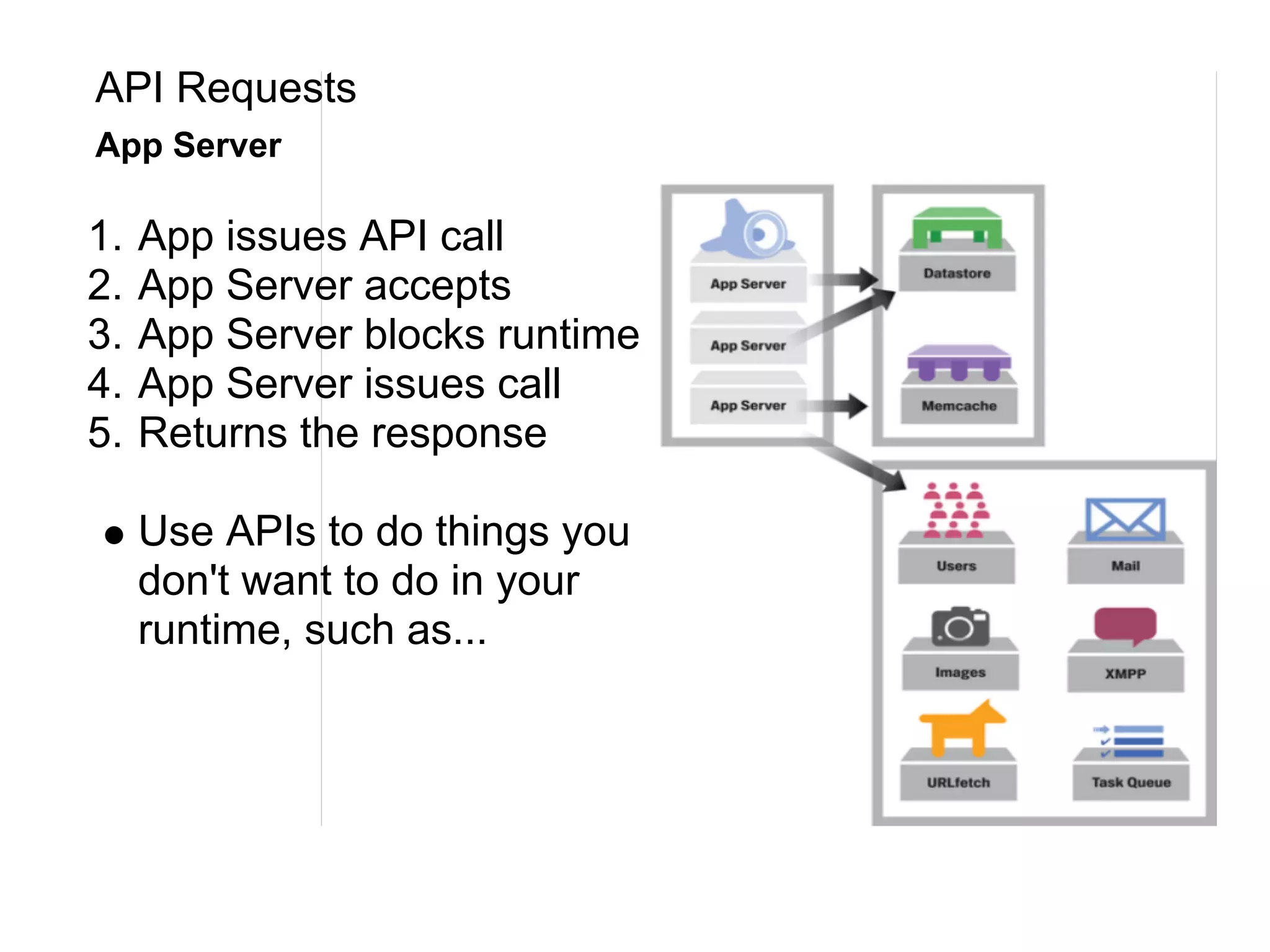



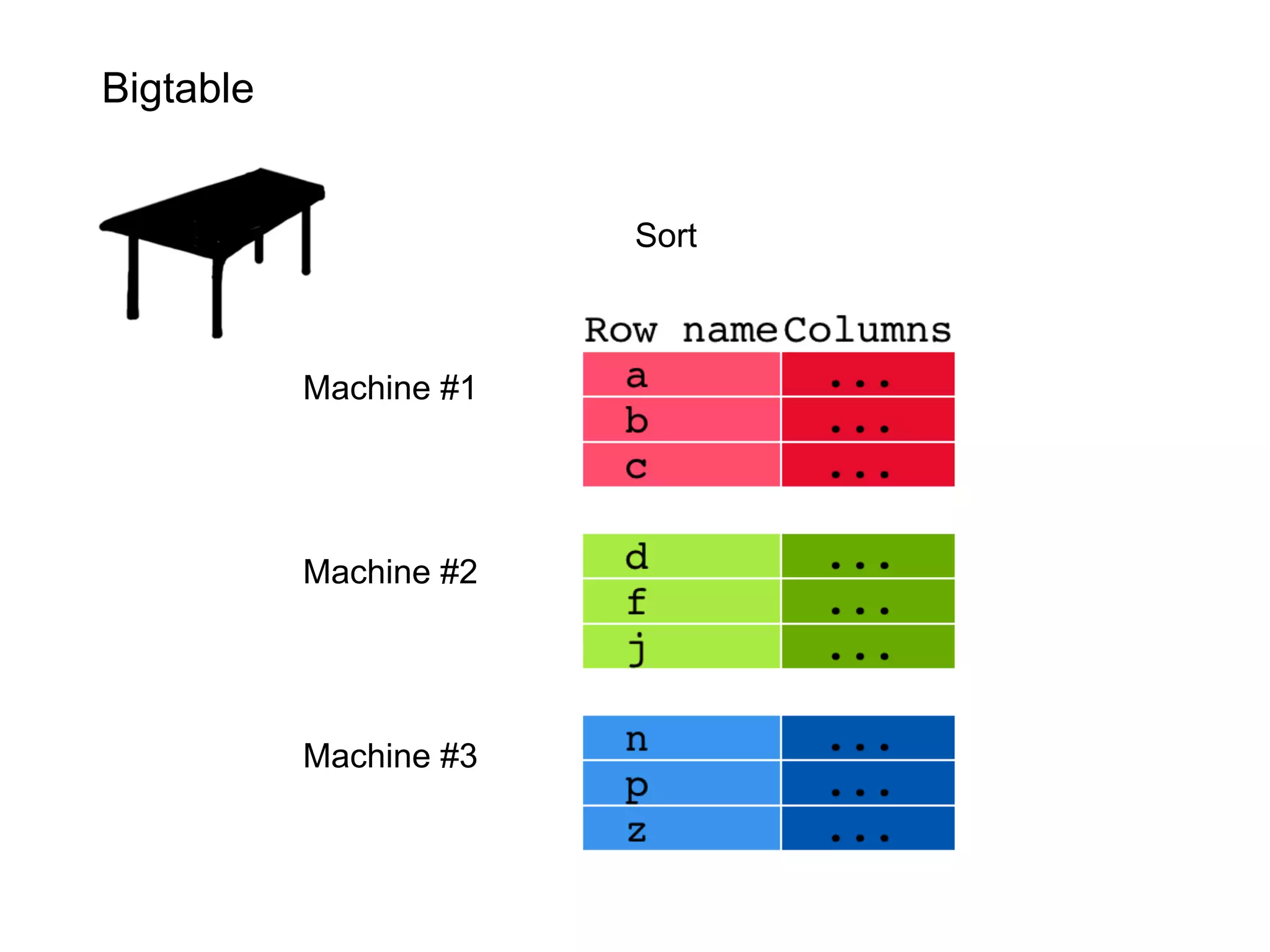
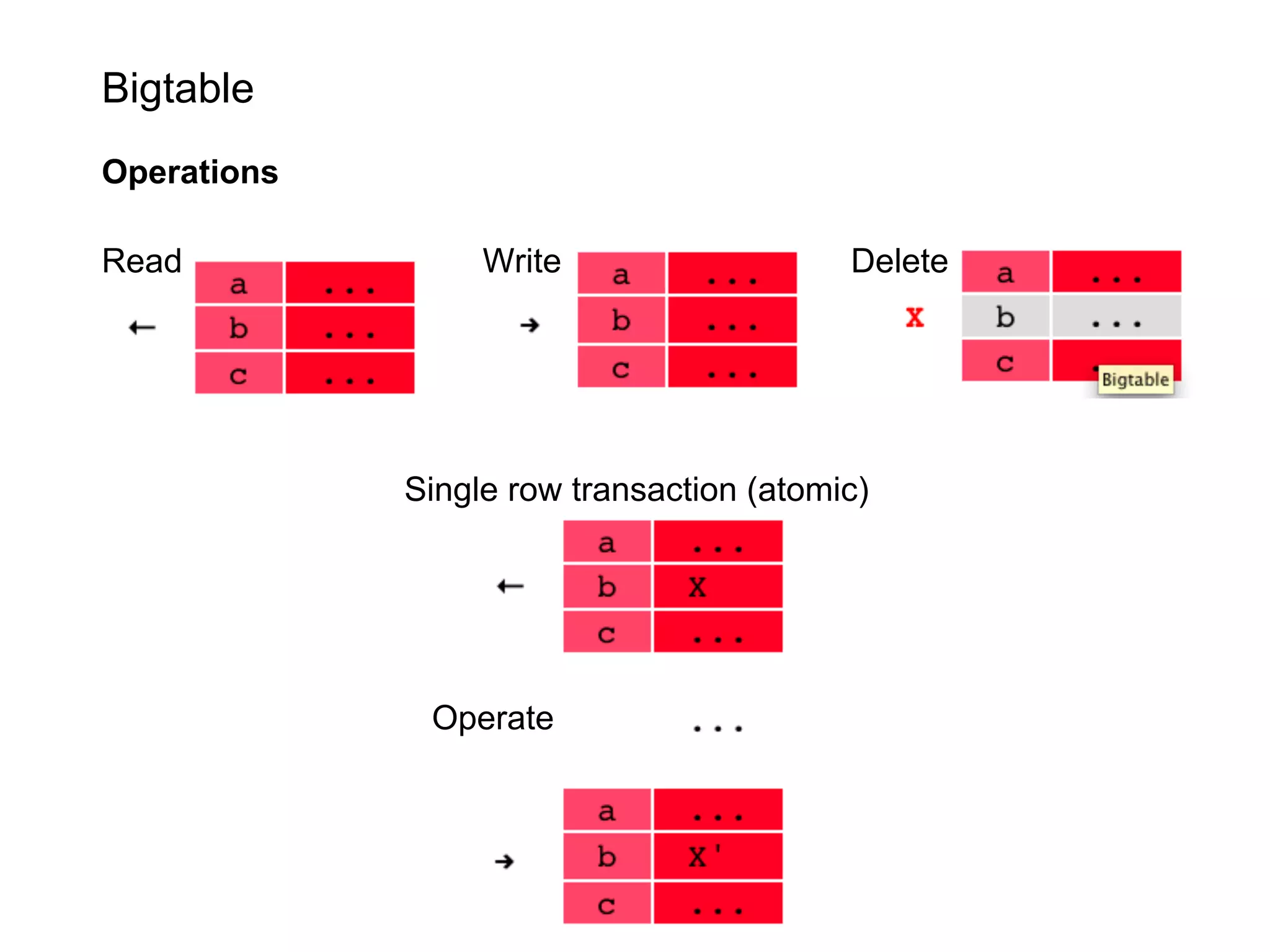

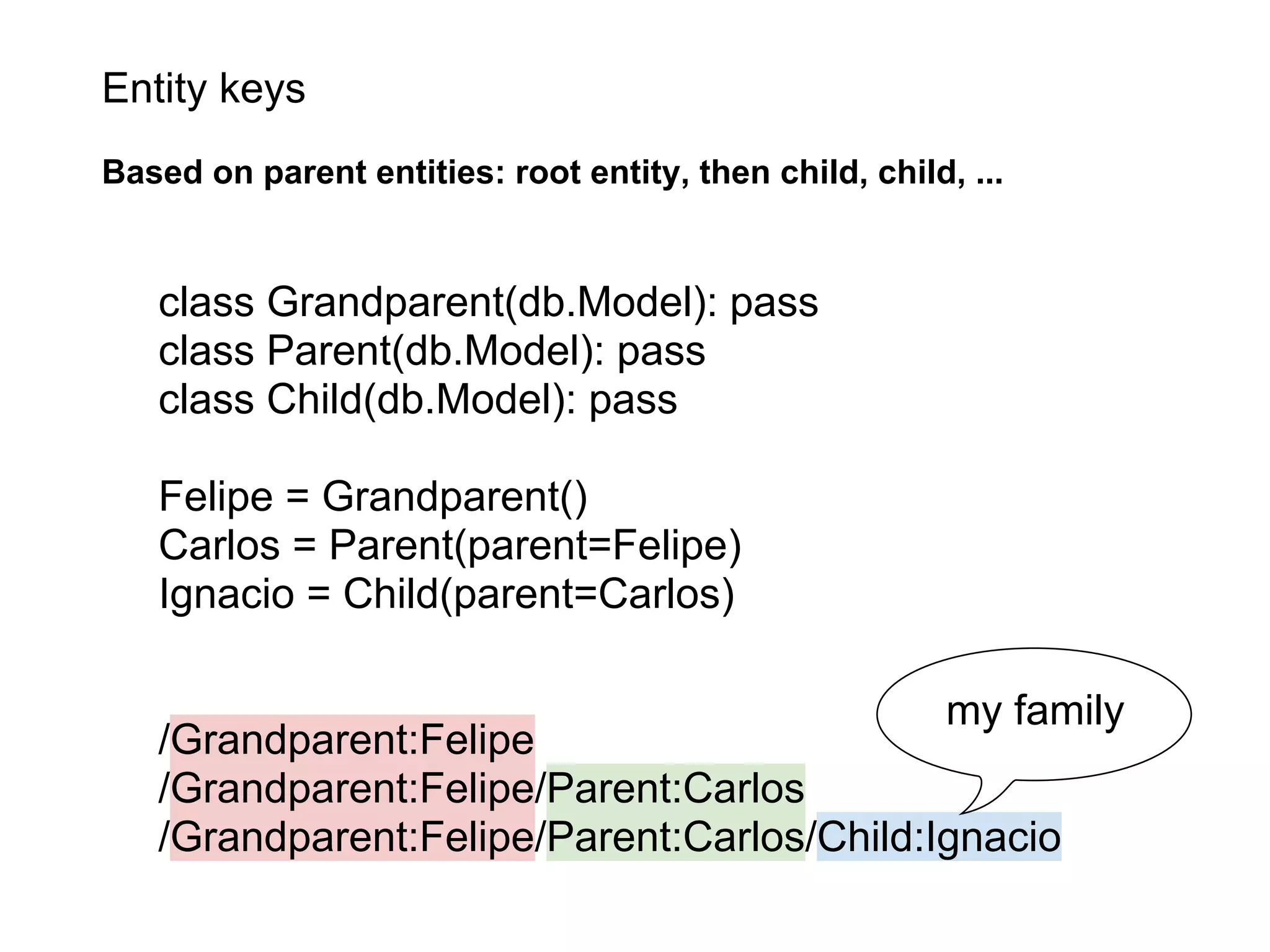




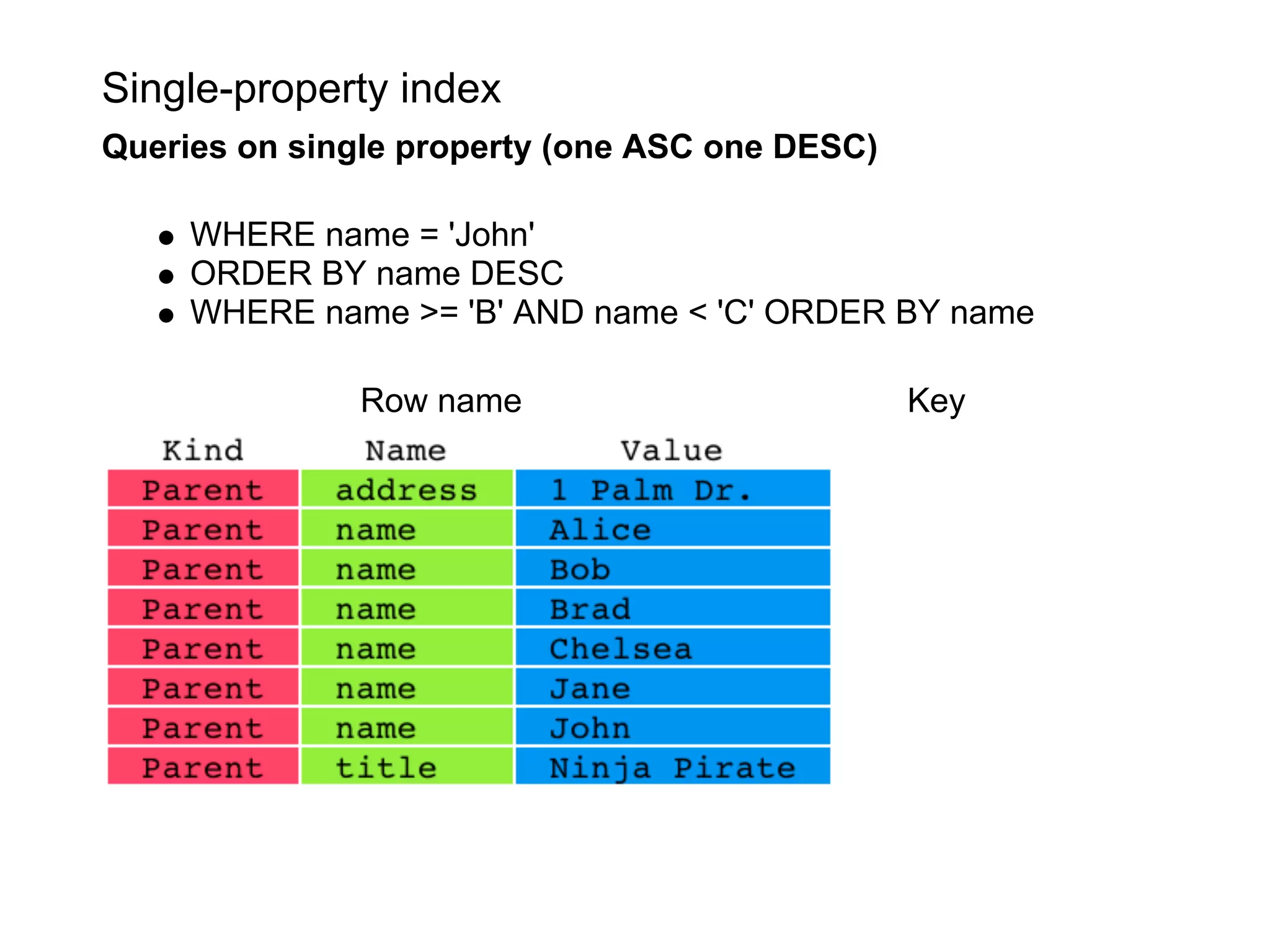
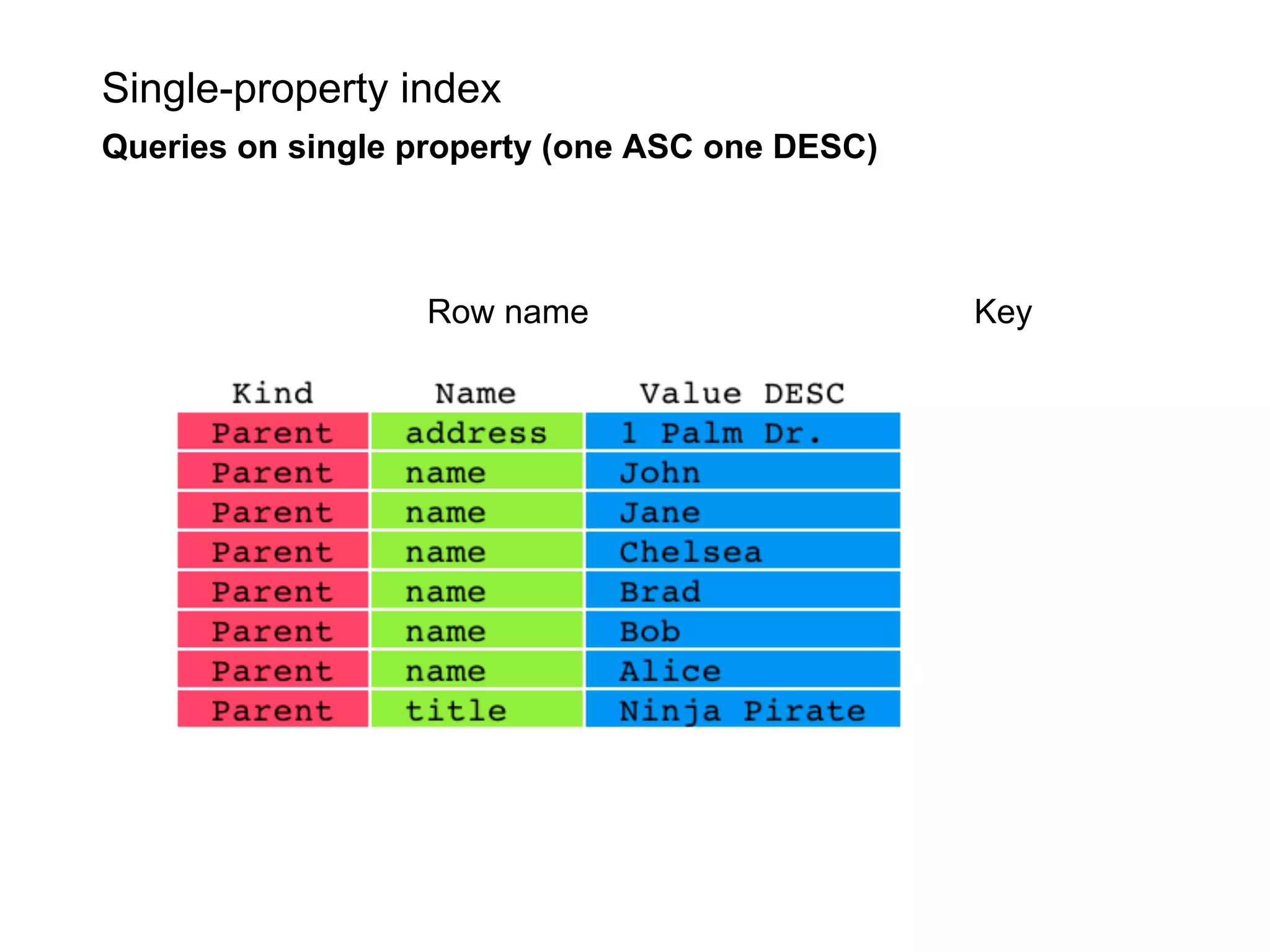

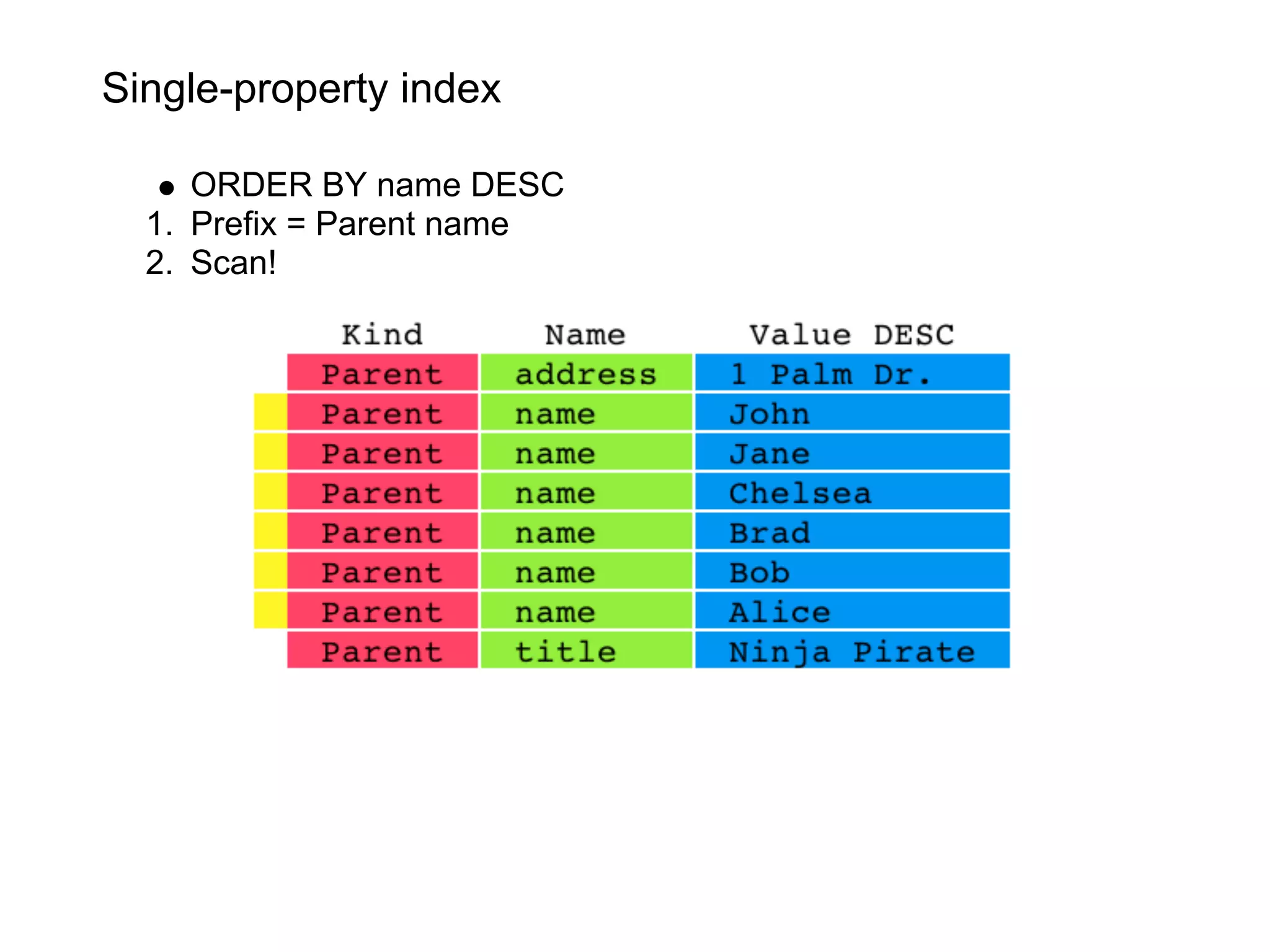




















This document summarizes the life of a request on Google App Engine. It describes how requests for static content are routed to specialized static content servers. Requests for dynamic content are routed to App Servers where the code runs. App Servers can also make API requests to services like Memcache and the Datastore. The document then recaps the design motivations behind App Engine like building on Google infrastructure, encouraging fast requests and statelessness, and requiring a partitioned data model.
















































































