Download as PDF, PPTX




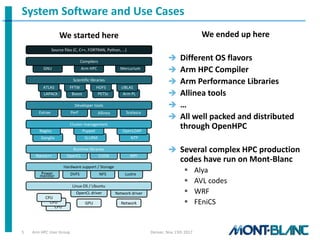


















The Mont-Blanc project aims to harness mobile technology for high-performance computing (HPC) and data centers, focusing on hardware and software development across multiple phases from 2012 to 2018. It has involved experiments with real hardware, software solutions, and simulations to explore next-generation architectures and improve HPC efficiency. Collaborations include the evaluation of ARM-based libraries and compilers, and the project seeks to engage in educational initiatives such as student competitions.























































































