Download to read offline



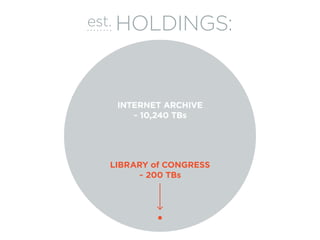
![The 80TB Wide Web
Scrape
[March - December 2011]](https://image.slidesharecdn.com/dh2014-presentation-140710042610-phpapp02/85/Clustering-Search-to-Navigate-A-Case-Study-of-the-Canadian-World-Wide-Web-as-a-Historical-Resource-4-320.jpg)
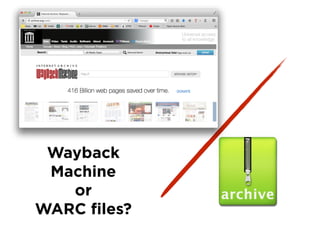


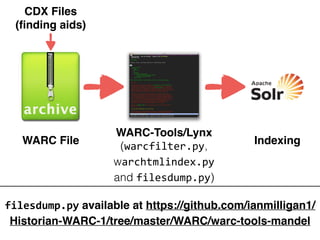
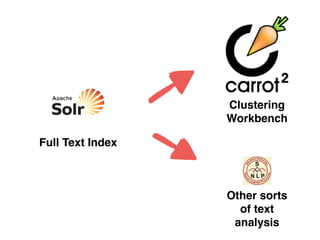

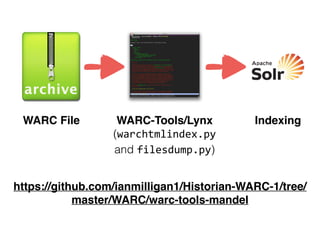

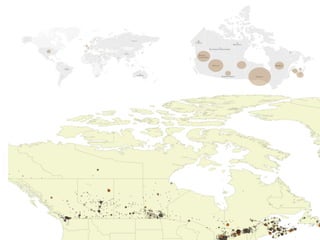


Ian Milligan's work focuses on using computational methods to analyze web archives, particularly a case study of the Canadian web. The study involves over 622,000 distinct URLs and utilizes various tools and formats, including WARC files, for indexing and text analysis. The document emphasizes the importance of historians adapting to digital resources to enhance their research capabilities.















































