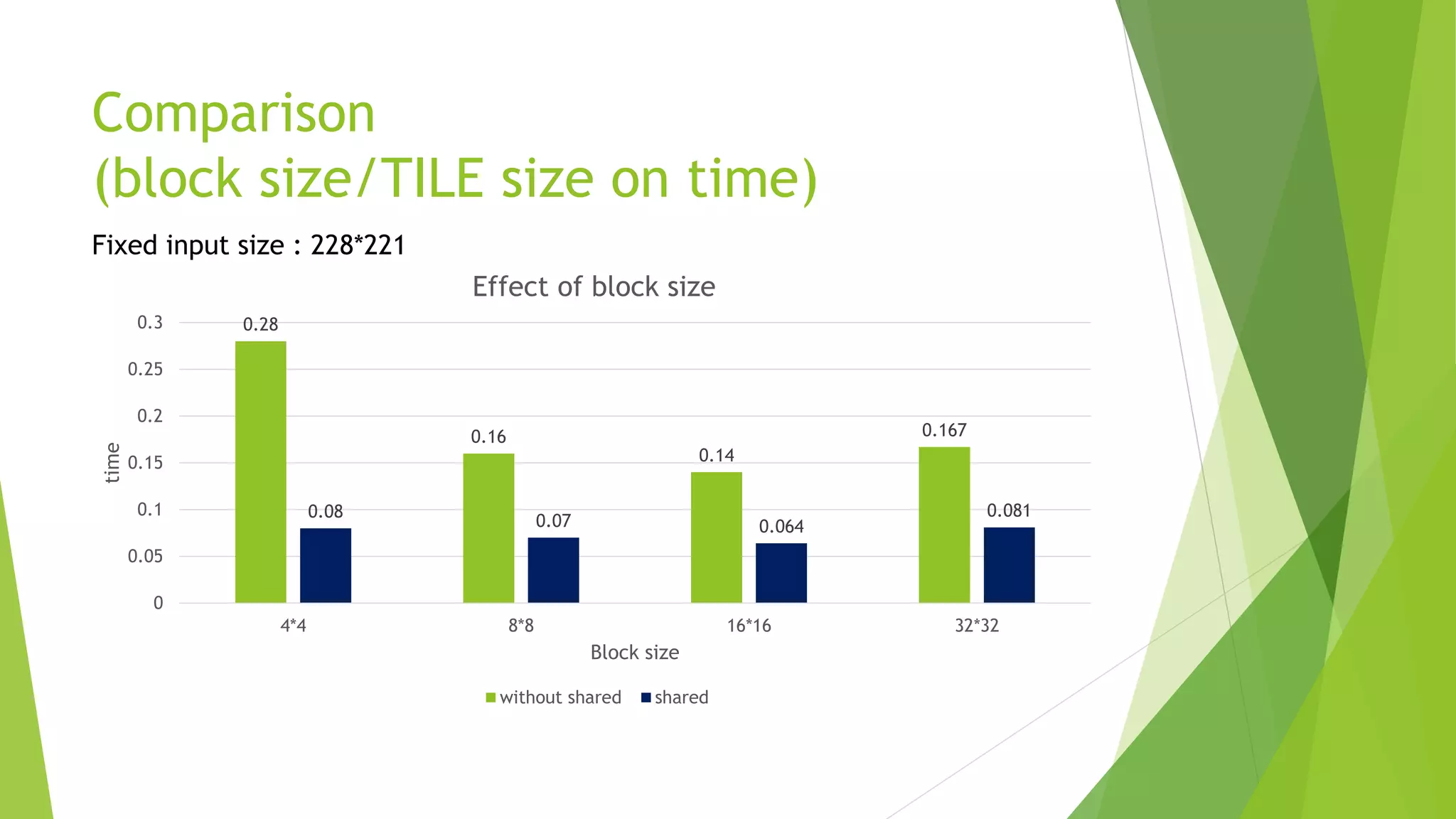
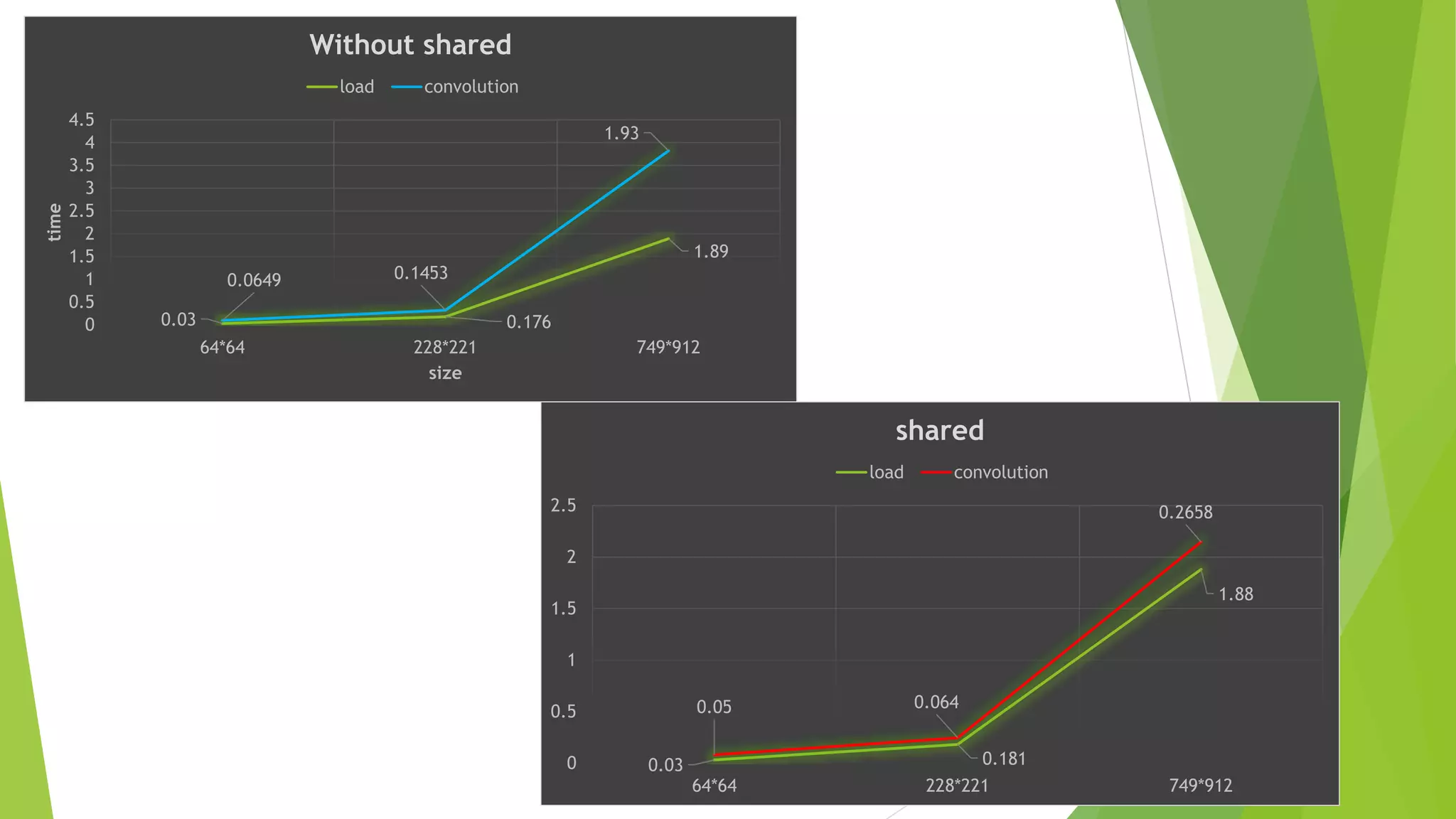
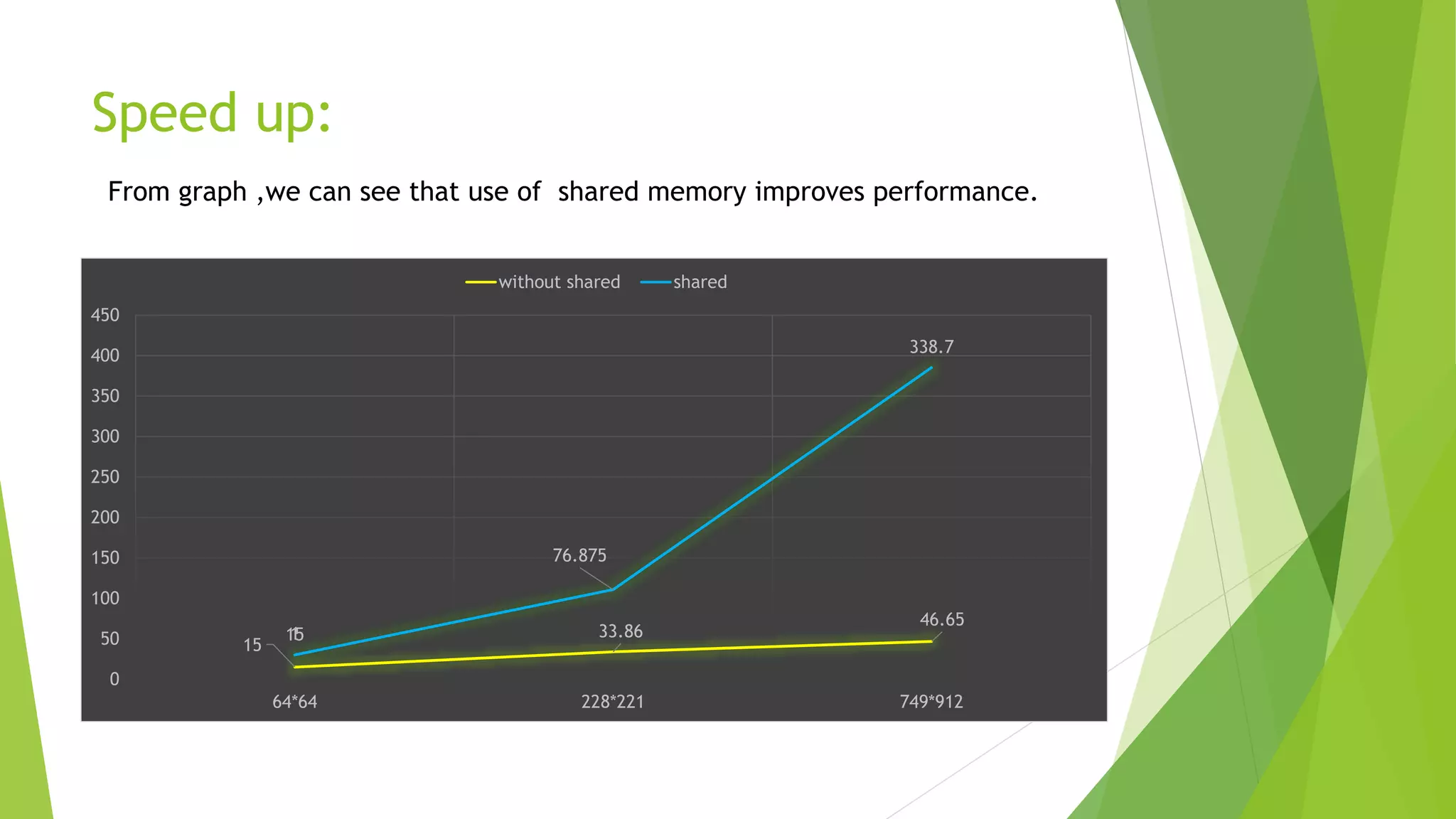
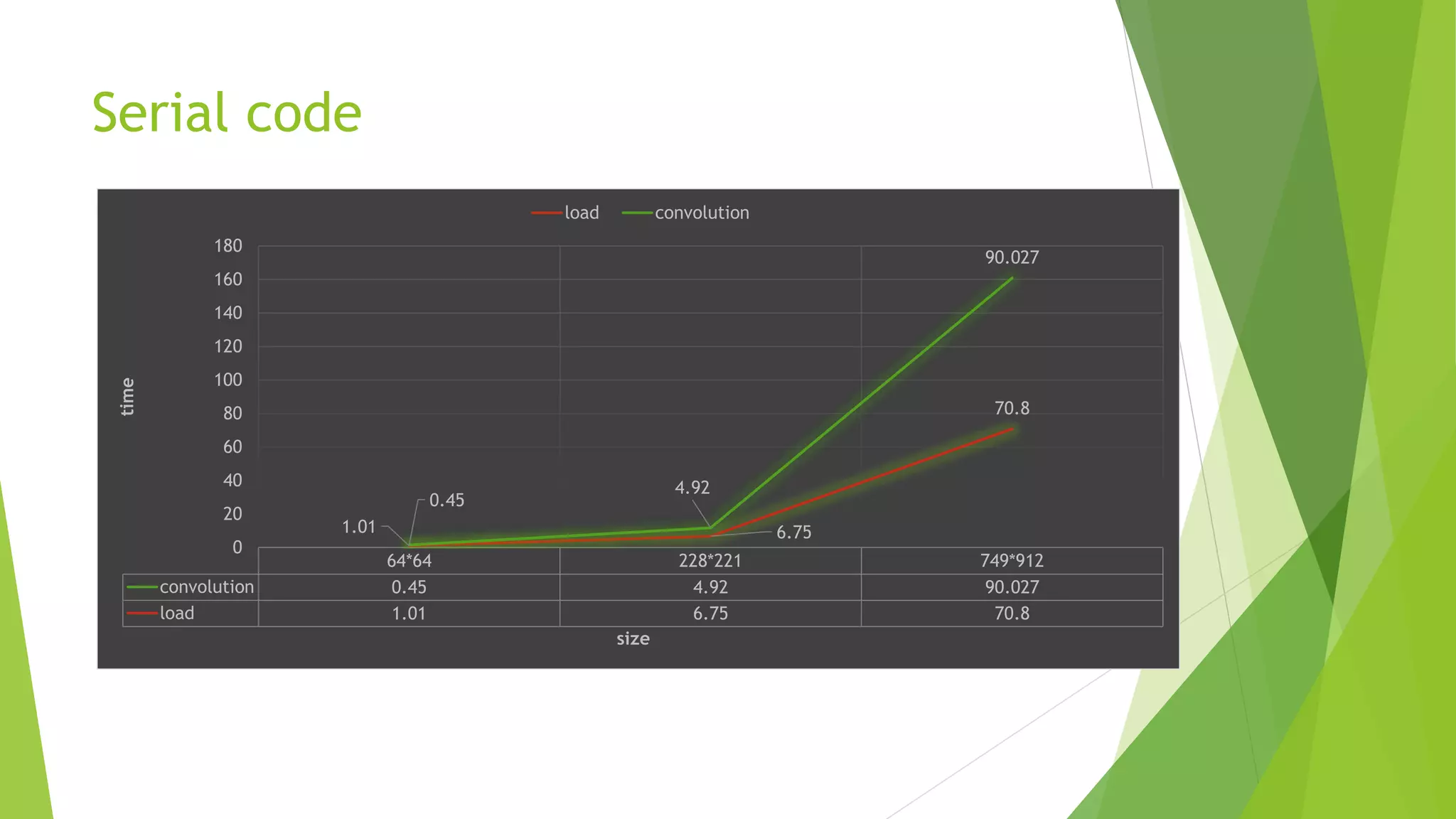
The document discusses Gaussian smoothing in image processing, explaining how it involves convolving images with a Gaussian function to reduce noise and detail. It outlines the complexities of both serial and parallel implementations, detailing code examples for each, including the use of shared and constant memory for performance enhancement. The conclusion highlights the significant speed improvements achievable through the use of shared memory, with a noted speed up of approximately 10x compared to naive implementations.
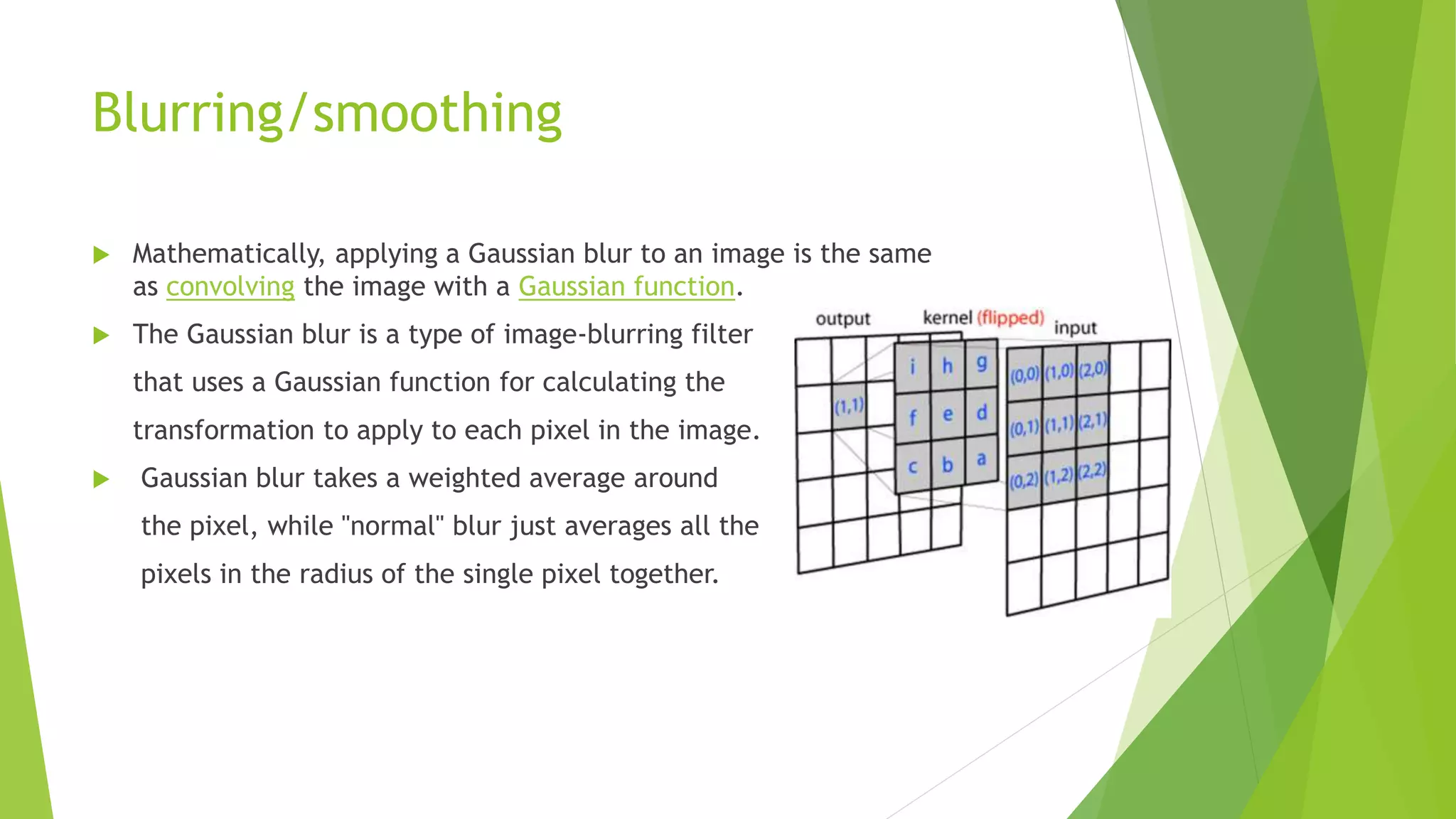
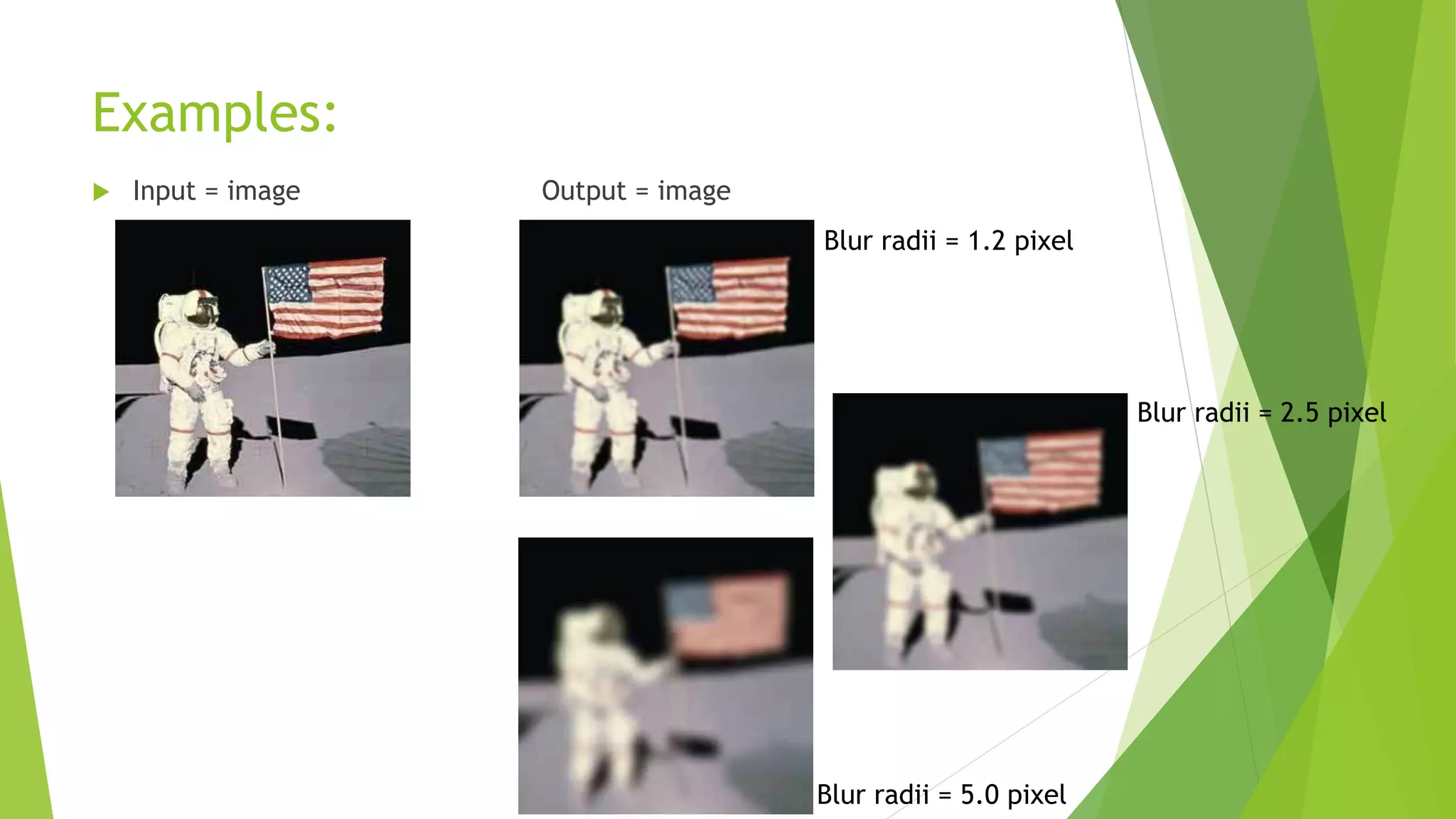
Blurring/smoothing
Mathematically, applyinga Gaussian blur to an image is the same
as convolving the image with a Gaussian function.
The Gaussian blur is a type of image-blurring filter
that uses a Gaussian function for calculating the
transformation to apply to each pixel in the image.
Gaussian blur takes a weighted average around
the pixel, while "normal" blur just averages all the
pixels in the radius of the single pixel together.
How it works?kernel type : Gaussian
Complexity = O(N*r*r) ; r = blur radii. N = total no. of pixels
It is a widely used effect in graphics software, typically to
reduce image noise and reduce image detail.
Ref: https://en.wikipedia.org/wiki/Gaussian_blur
Strategy & NaïveImplementation
Each thread generates a single output pixel.
Simple implementation => load image, launch kernel, compute output
A block of pixels from the image is loaded into an array in shared memory.
And load filter into constant memory
9.
Parallel code:
(without shared)
Here,Block size = 16*16;
__global__ void image(int * in, int *out, int width)
{
//masks
int Mx[5][5] =
{ { 1,4,7,4,1 },{4,16,26,16,4 },{7,26,41,26,7},{ 4,16,26,16,4
},{1,4,7,4,1} };
int sumX = 0;
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if(row <= 0 || row >= n-1 || col <= 0 || col >=
n-1)
{
out[row*width + col] = 0;
}
else
{
for(int i = -2; i < 3; i++)
{
for(int j = -2; j < 3; j++)
{
int pixel = in[(row + i) * width + (col + j)];
sumX += pixel * Mx[i+2][j+2];
}
}
__syncthreads();
int ans = abs(sumX)/273;
//if the value of sum exceeds general pixels
measures then assign boundaries
if(ans > 255) ans = 255;
if(ans < 0) ans = 0;
//save the convolved pixel to out array
out[row*width + col] = ans;
}
}
10.
Parallel code:
(shared)
Useof constant and shared
memory
Tile size = block size = 16*16
//kernel
__global__ void image(int * in, int *out, int width, int
height)
{
__shared__ int smem[BLOCK_W*BLOCK_H];
__const__ int Mx[5][5] =
{ { 1,4,7,4,1 },{4,16,26,16,4 },{7,26,41,26,7},{ 4,16,26,16,4
},{1,4,7,4,1} };
int x =blockIdx.x*TILE_W+threadIdx.x - R;
int y = blockIdx.y*TILE_H + threadIdx.y -R;
x = min(max(0, x), width-1);
y = min(max(0,x), height-1);
unsigned int index = y*width+x;
unsigned int bindex = threadIdx.y*blockDim.y+threadIdx.x;
smem[bindex] = in[index];
__syncthreads();
if((threadIdx.x>=R)&&(threadIdx.x<(BLOCK_W-
R))&&(threadIdx.y>=R)&&(threadIdx.y<(BLOCK_H-R)))
{
int sum =0;
for(int dy = -R; dy<R;dy++){
for(int dx=-R;dx<R;dx++){
int i = smem[bindex+(dy*blockDim.y)+dx];
sum += Mx[dy][dx]*i;
}
}
out[index]= sum/273;
}
}



![Serial code
Complexity = O(N*r*r); N=total no. of pixel
So, in parallel code we can just launch threads based on output image(like in
matrix multiplication)
for(row = 0; row < height; row++){
for(col = 0; col < width; col++){
int sumX = 0,sumY = 0,ans = 0;
int r = row;
int c = col;
for(i = -filterWidth/2; i < filterWidth/2; i++){
for(j = -filterWidth/2; j < filterWidth/2; j++){
row = row+i;
col = col+j;
row = min(max(0, row), width - 1);
col = min(max(0, col), height - 1);
int pixel = input[row][col];
sumX += pixel*Mx[i + filterWidth/2][j +
filterWidth/2]; }
}
ans = abs(sumX/273) ;
if(ans > 255) ans = 255;
if(ans < 0) ans = 0;
output[r][c] = ans;
}
}](https://image.slidesharecdn.com/imageproc-ppt-160110063912/75/Gaussian-Image-Blurring-in-CUDA-C-6-2048.jpg)

![Parallel code:
(without shared)
Here, Block size = 16*16;
__global__ void image(int * in, int *out, int width)
{
//masks
int Mx[5][5] =
{ { 1,4,7,4,1 },{4,16,26,16,4 },{7,26,41,26,7},{ 4,16,26,16,4
},{1,4,7,4,1} };
int sumX = 0;
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if(row <= 0 || row >= n-1 || col <= 0 || col >=
n-1)
{
out[row*width + col] = 0;
}
else
{
for(int i = -2; i < 3; i++)
{
for(int j = -2; j < 3; j++)
{
int pixel = in[(row + i) * width + (col + j)];
sumX += pixel * Mx[i+2][j+2];
}
}
__syncthreads();
int ans = abs(sumX)/273;
//if the value of sum exceeds general pixels
measures then assign boundaries
if(ans > 255) ans = 255;
if(ans < 0) ans = 0;
//save the convolved pixel to out array
out[row*width + col] = ans;
}
}](https://image.slidesharecdn.com/imageproc-ppt-160110063912/75/Gaussian-Image-Blurring-in-CUDA-C-9-2048.jpg)
![Parallel code:
(shared)
Use of constant and shared
memory
Tile size = block size = 16*16
//kernel
__global__ void image(int * in, int *out, int width, int
height)
{
__shared__ int smem[BLOCK_W*BLOCK_H];
__const__ int Mx[5][5] =
{ { 1,4,7,4,1 },{4,16,26,16,4 },{7,26,41,26,7},{ 4,16,26,16,4
},{1,4,7,4,1} };
int x =blockIdx.x*TILE_W+threadIdx.x - R;
int y = blockIdx.y*TILE_H + threadIdx.y -R;
x = min(max(0, x), width-1);
y = min(max(0,x), height-1);
unsigned int index = y*width+x;
unsigned int bindex = threadIdx.y*blockDim.y+threadIdx.x;
smem[bindex] = in[index];
__syncthreads();
if((threadIdx.x>=R)&&(threadIdx.x<(BLOCK_W-
R))&&(threadIdx.y>=R)&&(threadIdx.y<(BLOCK_H-R)))
{
int sum =0;
for(int dy = -R; dy<R;dy++){
for(int dx=-R;dx<R;dx++){
int i = smem[bindex+(dy*blockDim.y)+dx];
sum += Mx[dy][dx]*i;
}
}
out[index]= sum/273;
}
}](https://image.slidesharecdn.com/imageproc-ppt-160110063912/75/Gaussian-Image-Blurring-in-CUDA-C-10-2048.jpg)