Download as PDF, PPTX

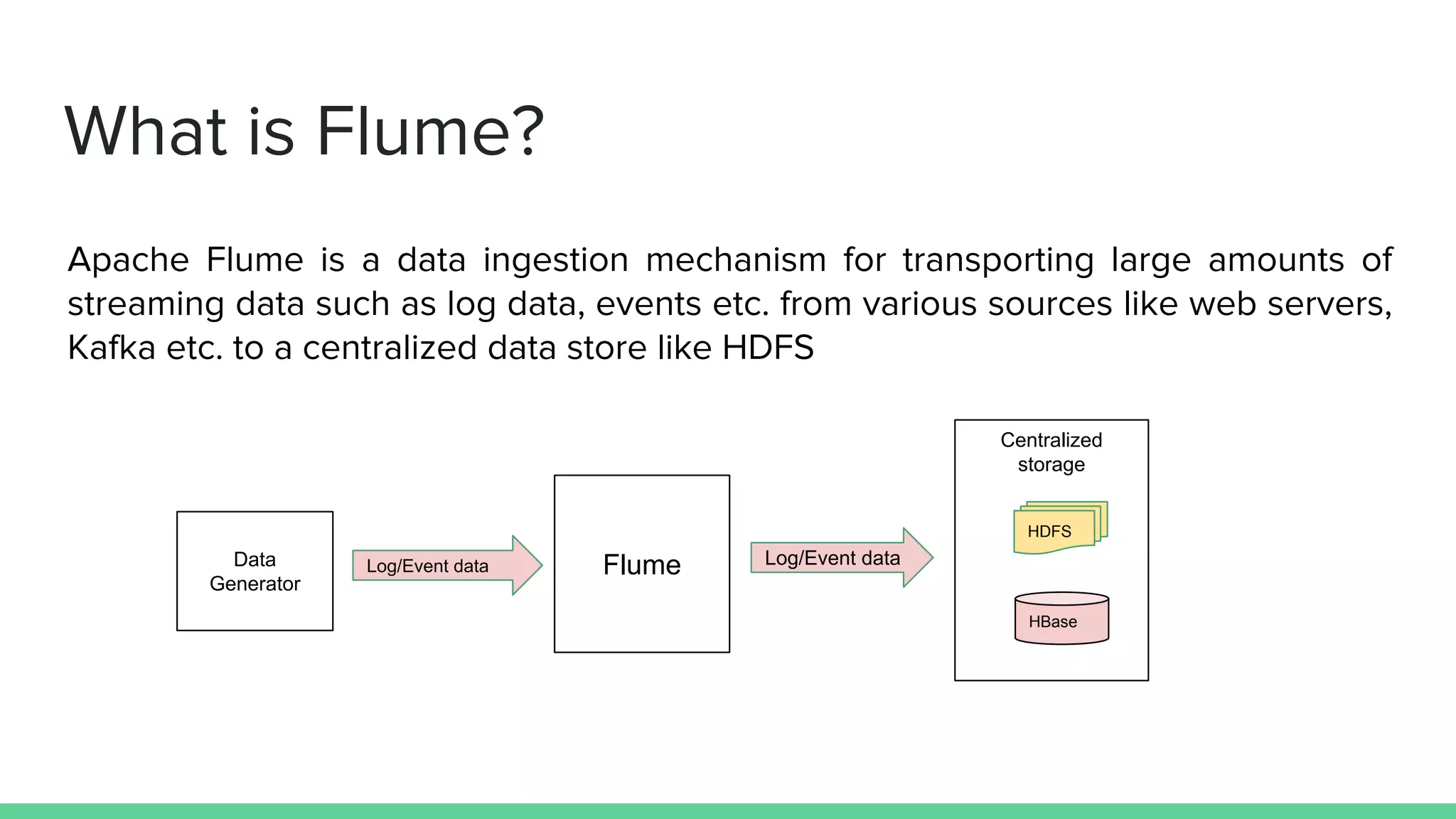

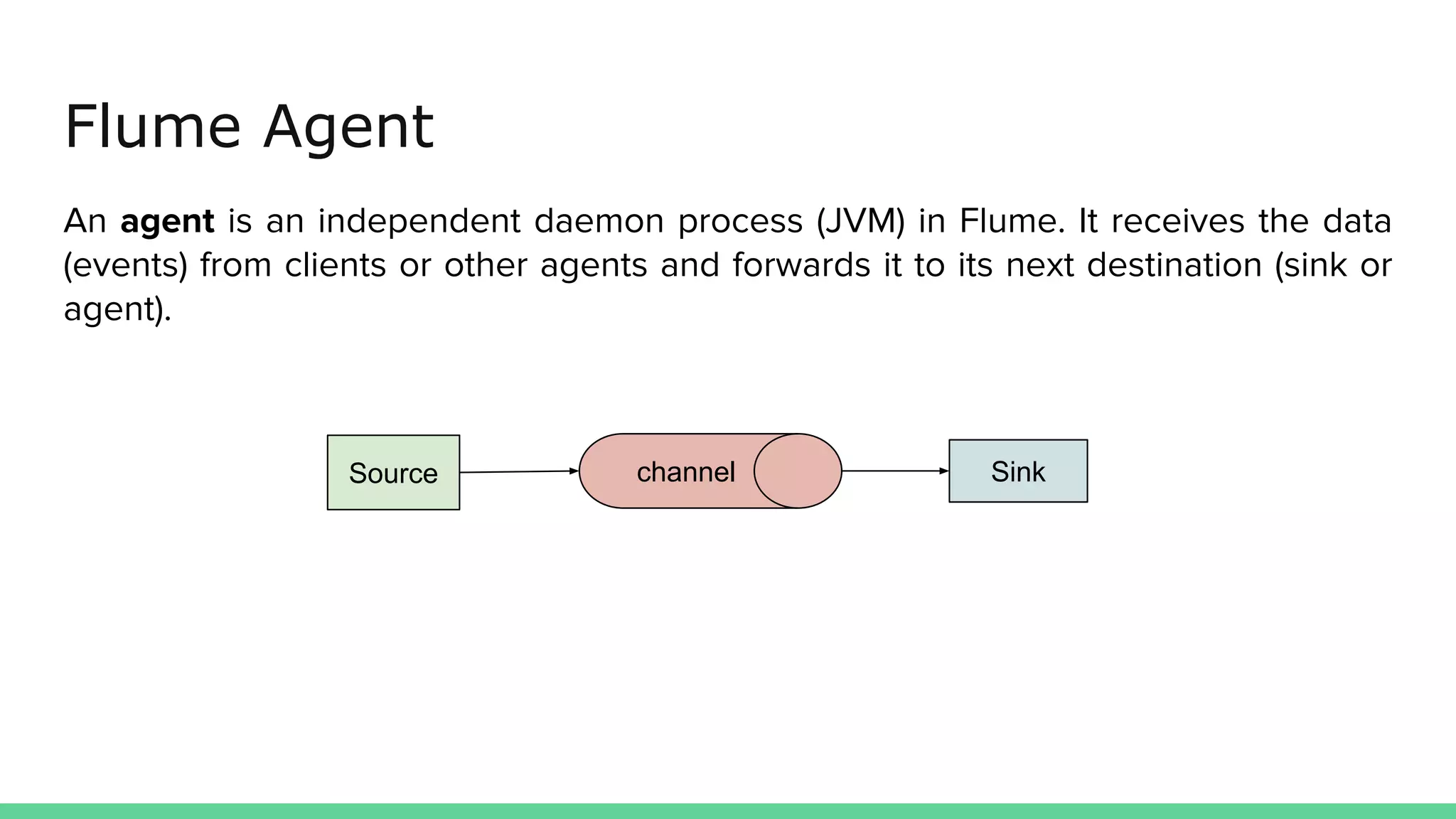
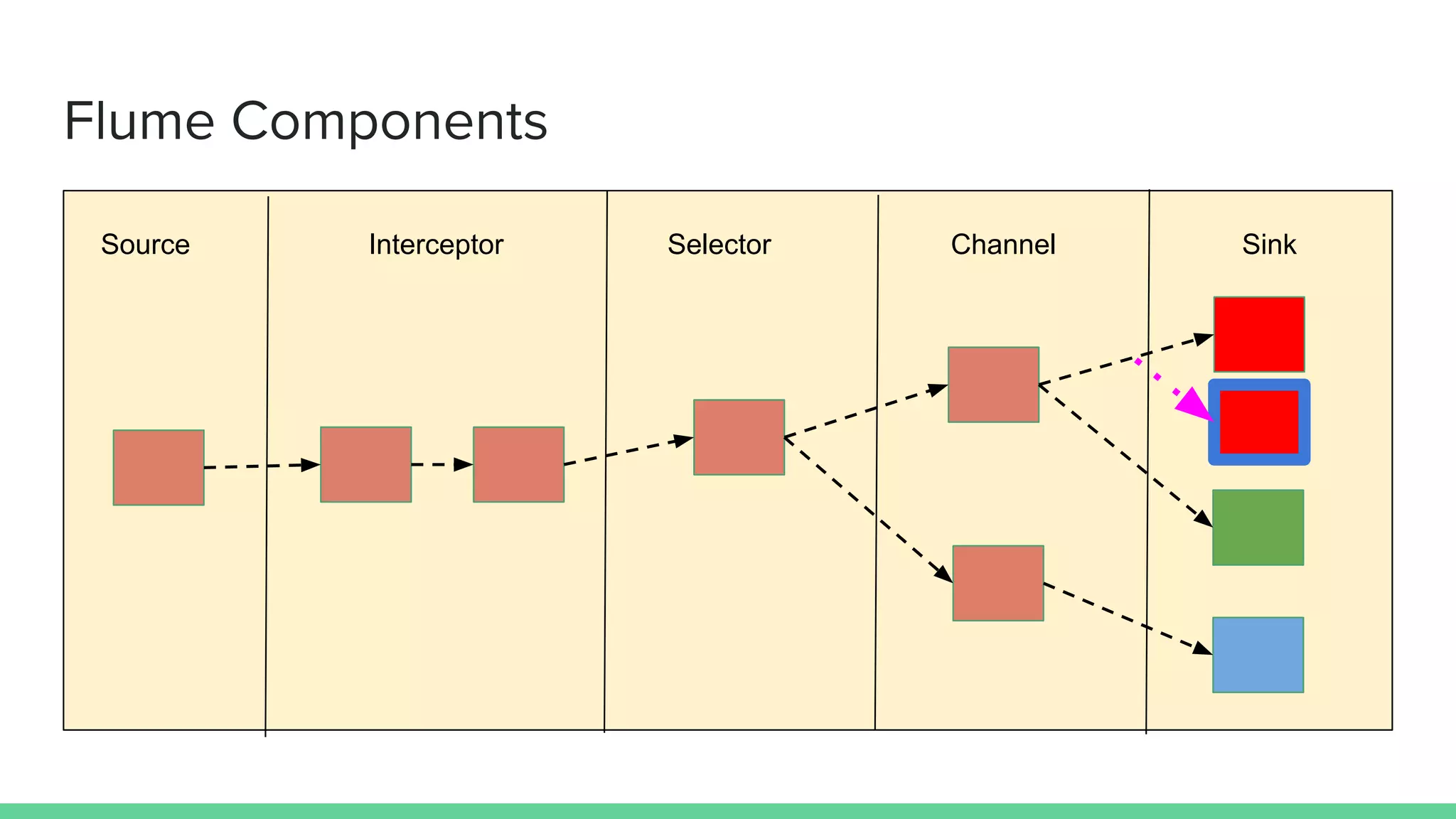
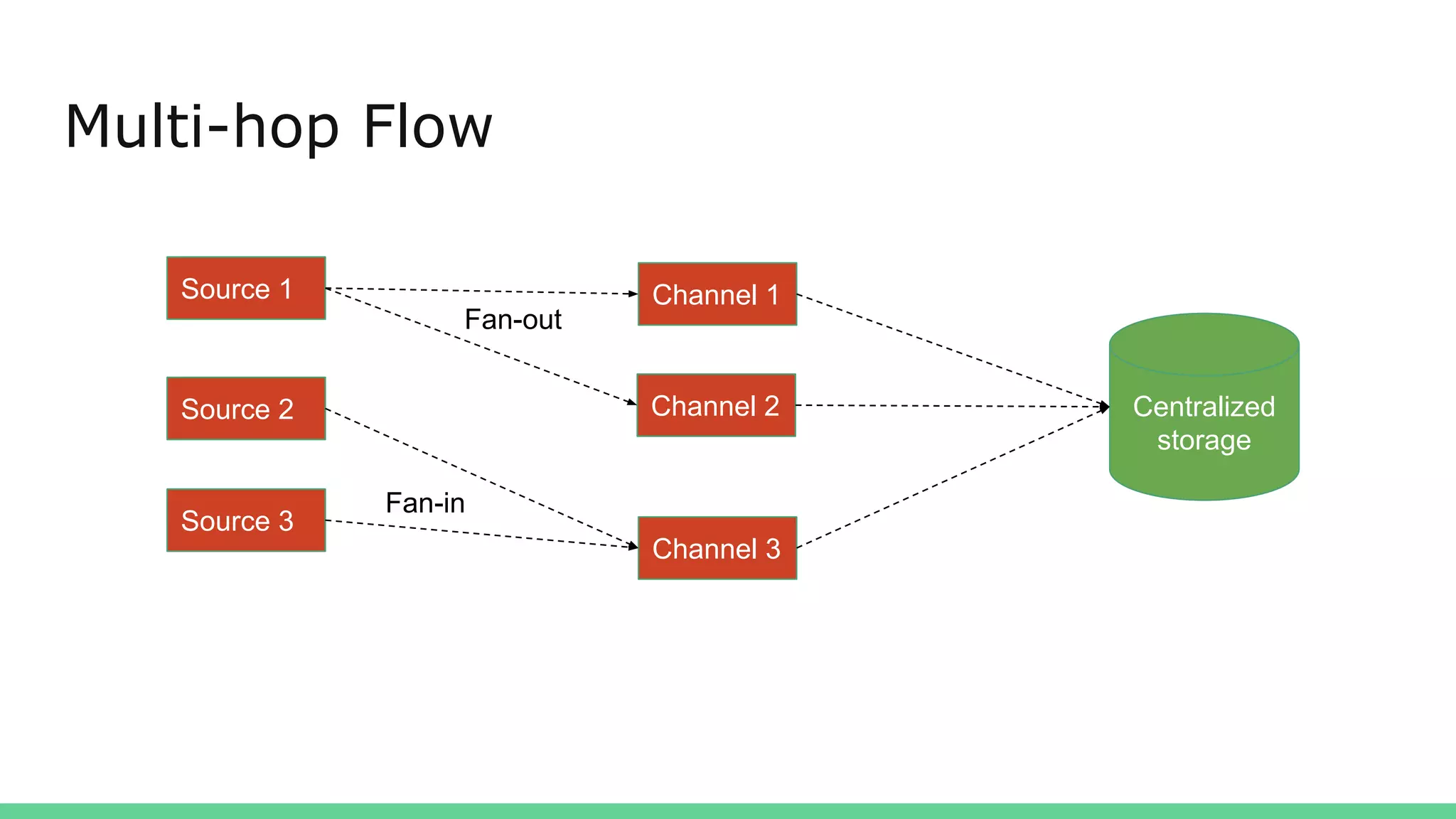

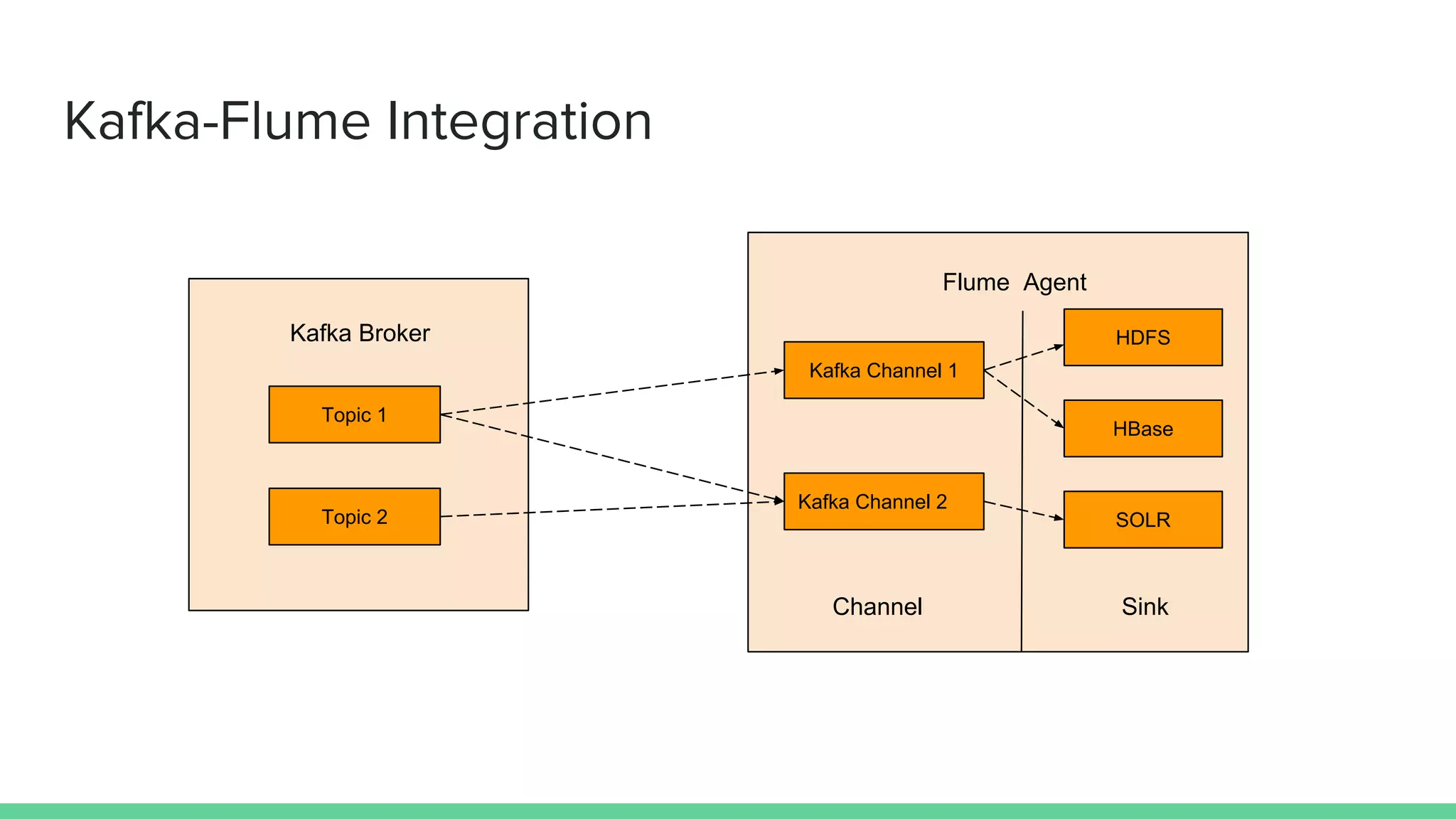





Apache Flume is a data ingestion system that transports streaming data from sources like web servers and Kafka to centralized data stores like HDFS. An event is the basic unit of data transported by Flume and contains a payload and optional headers. A Flume agent receives data from sources or other agents and forwards it to sinks or other agents. Flume uses sources, channels, and sinks to reliably move data between distributed systems with capabilities like load balancing and failover to prevent data loss.

























































































