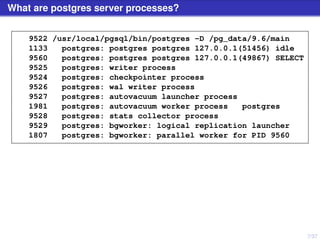
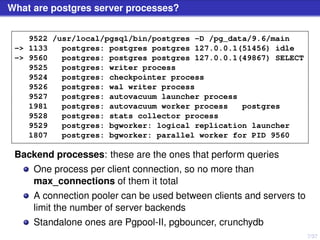
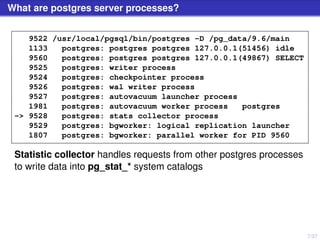
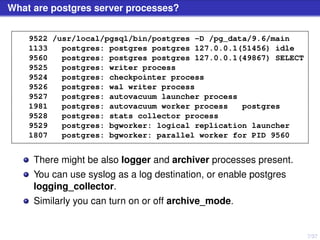
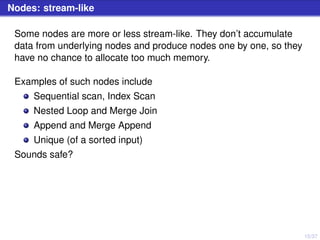
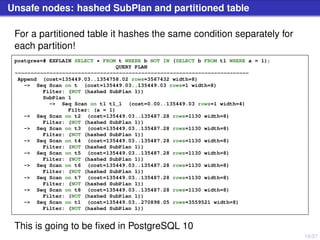
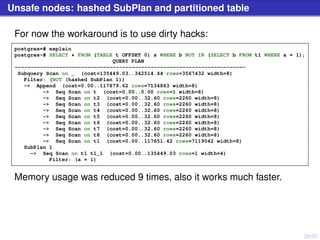
The document discusses PostgreSQL server processes and RAM usage, highlighting the importance of memory management to prevent issues like system crashes due to out of memory errors. It explains different server processes and their roles, including backends, writer, checkpointer, and autovacuum processes, as well as how shared memory and various configurations affect RAM consumption. Additionally, it emphasizes the need to monitor and optimize queries to handle memory effectively during execution.







































![26/37
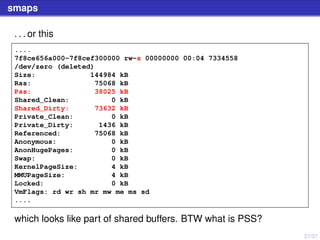
smaps
/proc/7194/smaps comprises a few sections like this
....
0135f000-0a0bf000 rw-p 00000000 00:00 0
[heap]
Size: 144768 kB
Rss: 136180 kB
Pss: 136180 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 136180 kB
Referenced: 114936 kB
Anonymous: 136180 kB
AnonHugePages: 2048 kB
Swap: 0 kB
KernelPageSize: 4 kB
MMUPageSize: 4 kB
Locked: 0 kB
VmFlags: rd wr mr mw me ac sd
....
which is a private memory segment . . .](https://image.slidesharecdn.com/talk-skiff-170228113325/85/PostgreSQL-and-RAM-usage-51-320.jpg)































































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)




