Download to read offline



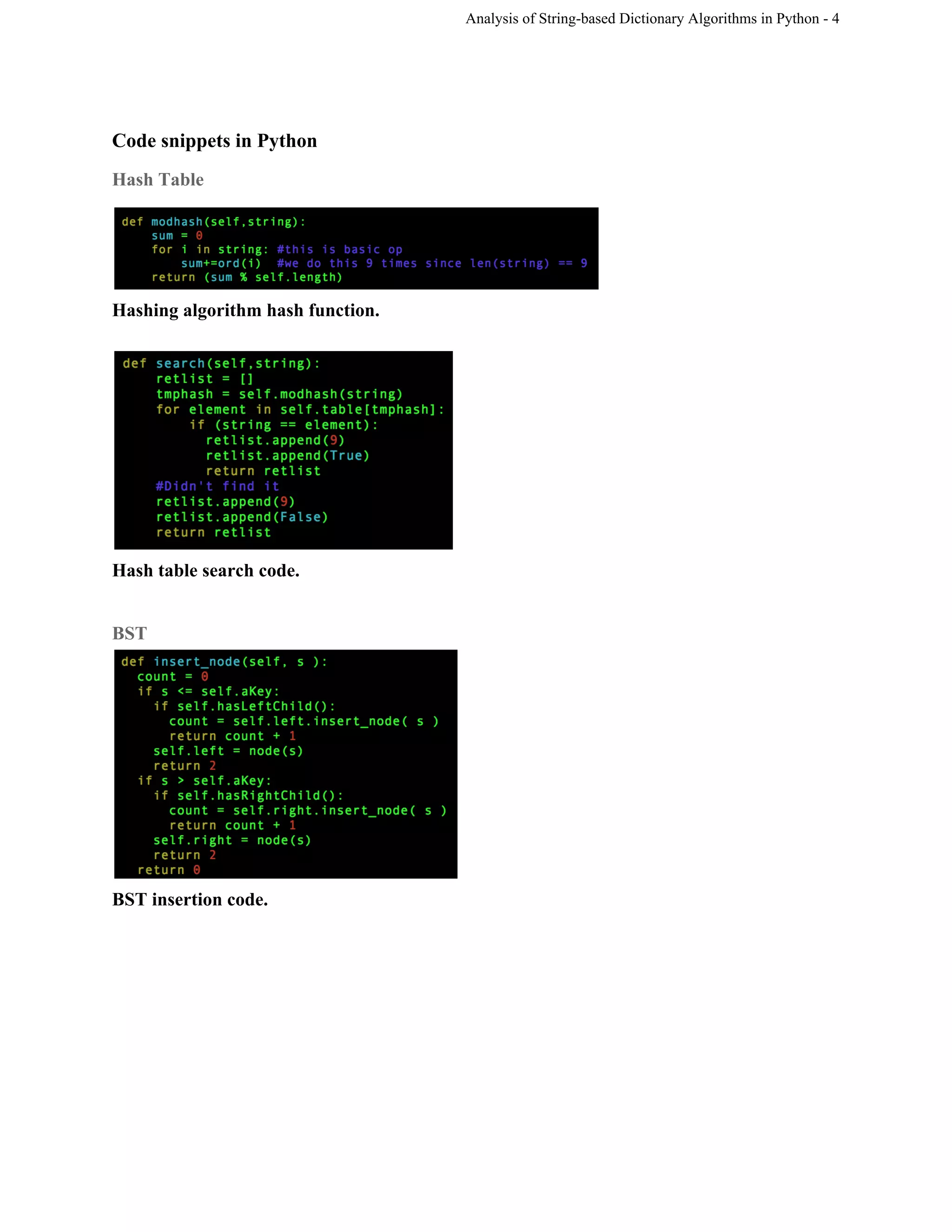
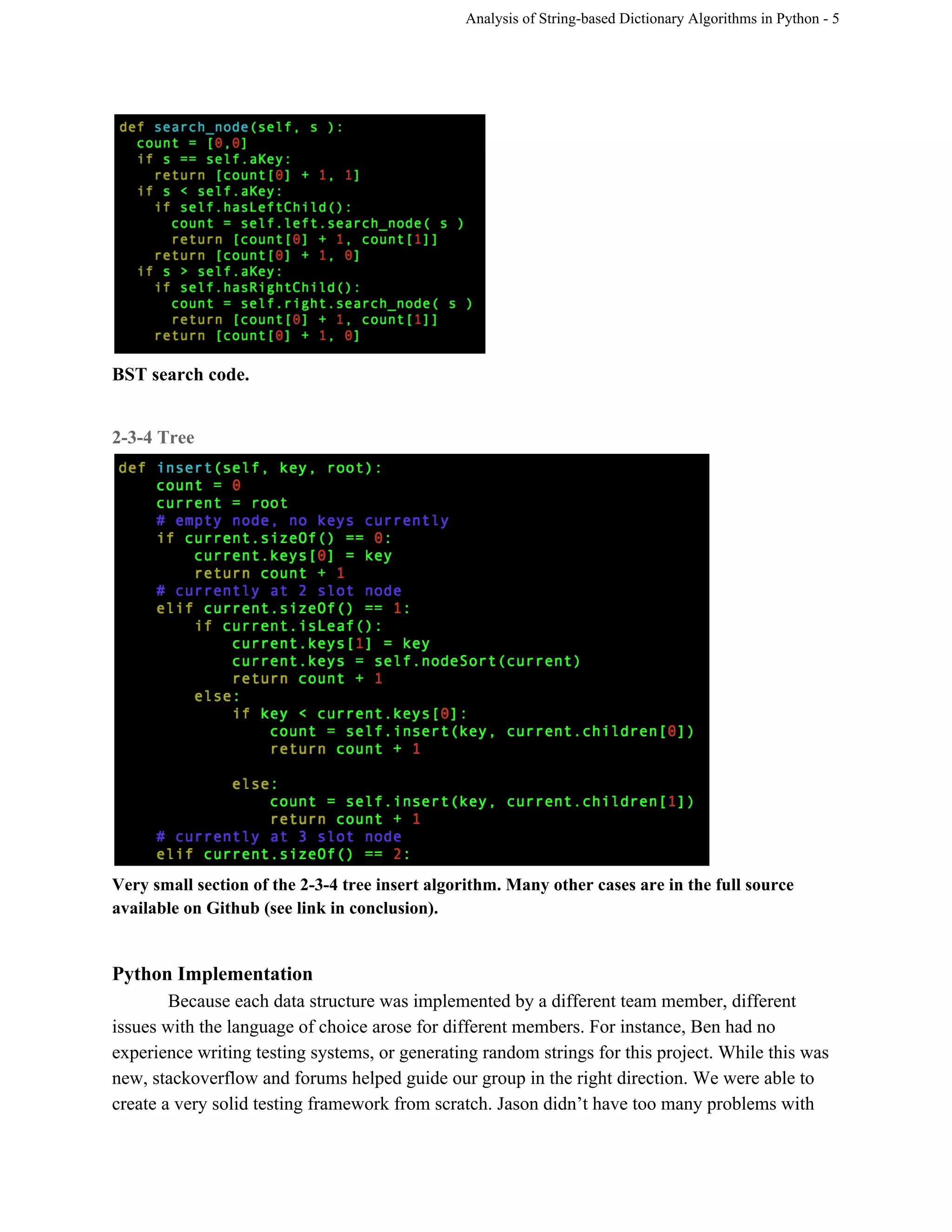





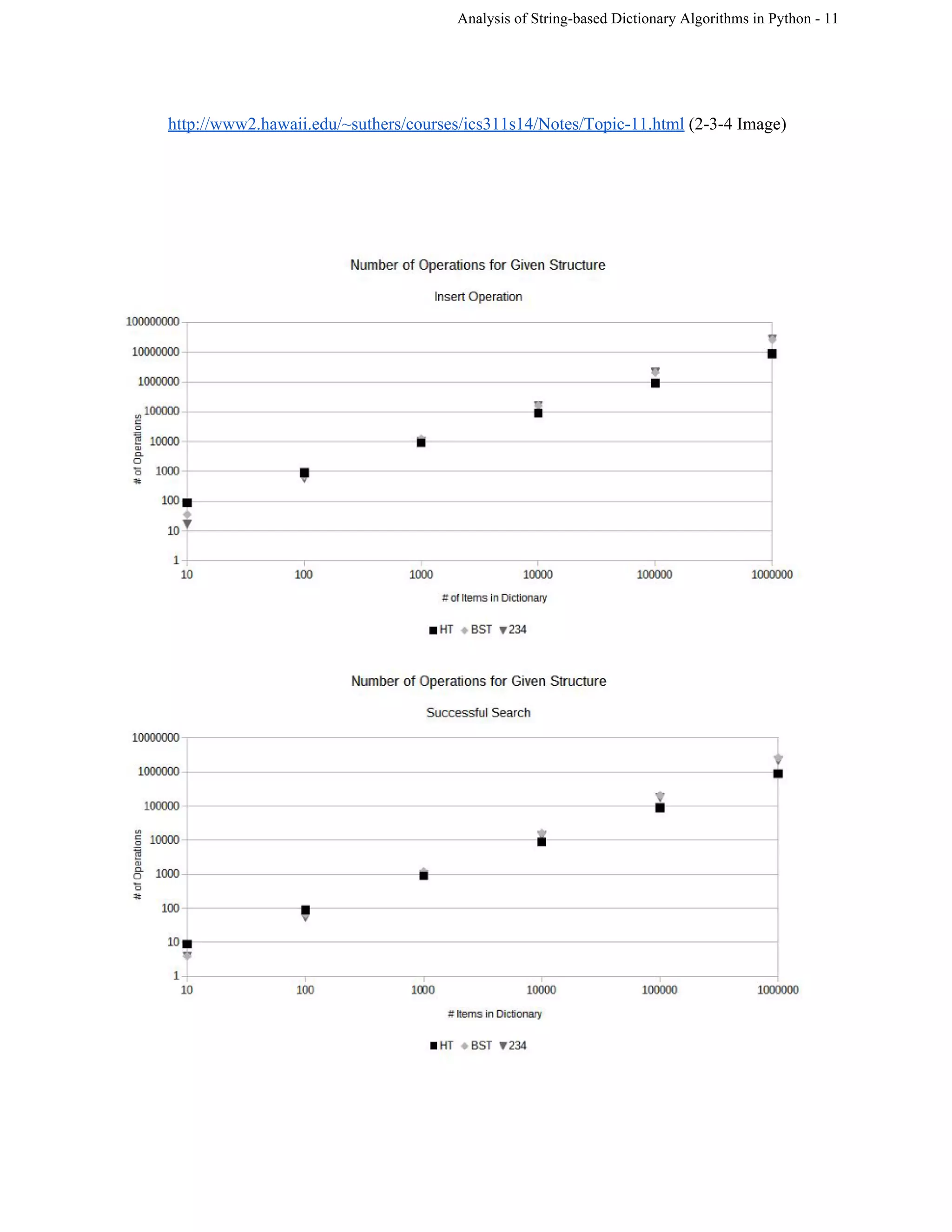



This document analyzes the implementations and efficiencies of three Python dictionary algorithms: an open-hashing table, binary search tree (BST), and 2-3-4 tree. The group implemented each data structure and tested their performance. The BST has insertion and selection times of O(log n) on average and O(n) worst-case. The 2-3-4 tree also has O(log n) average and worst-case times for insertion and searching due to self-balancing, though it requires more space. The open-hashing table uses hashing to distribute keys across buckets, but collisions degrade performance with many elements. The group encountered challenges with Python concepts like null values but overcame them through research