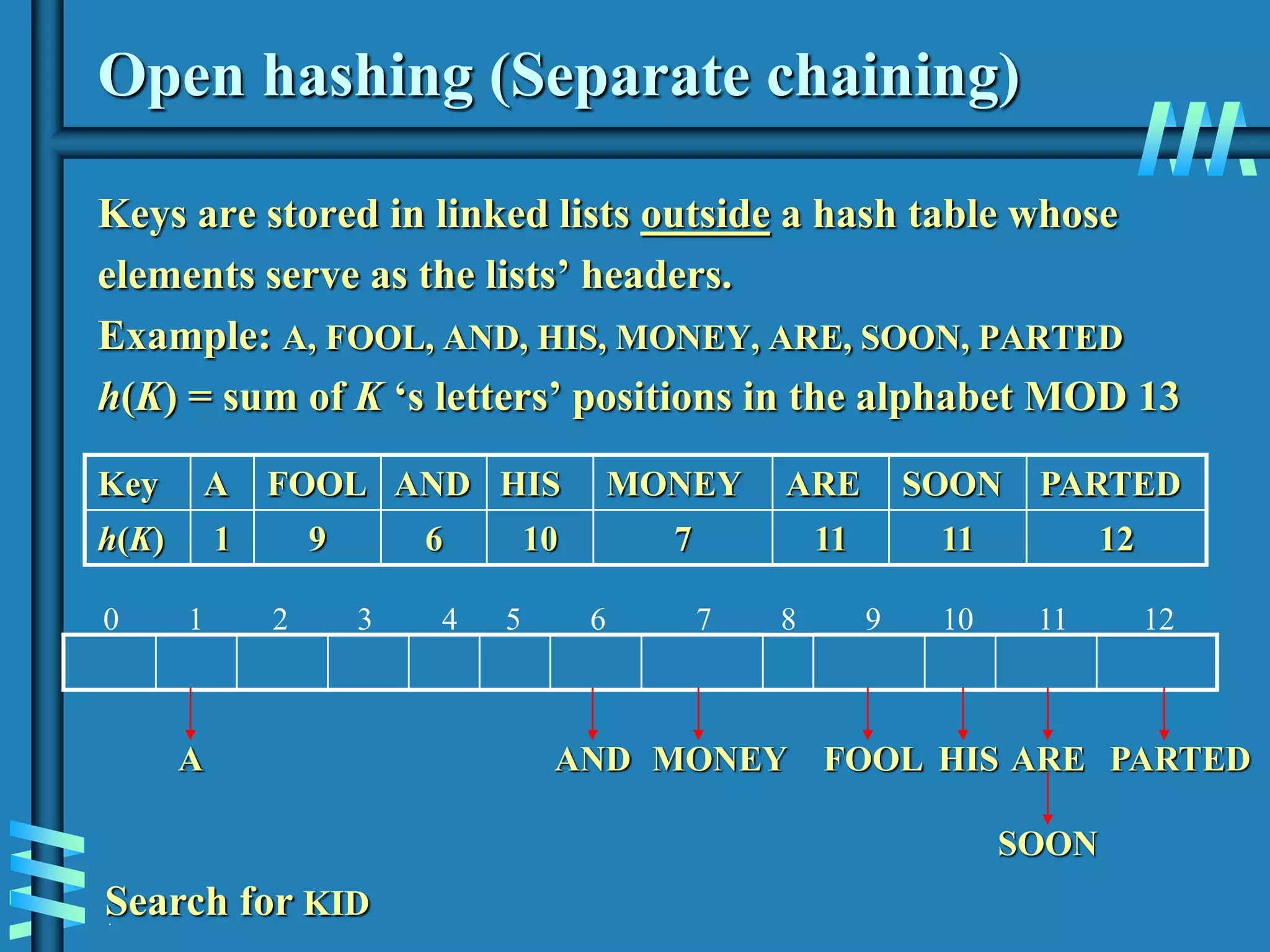
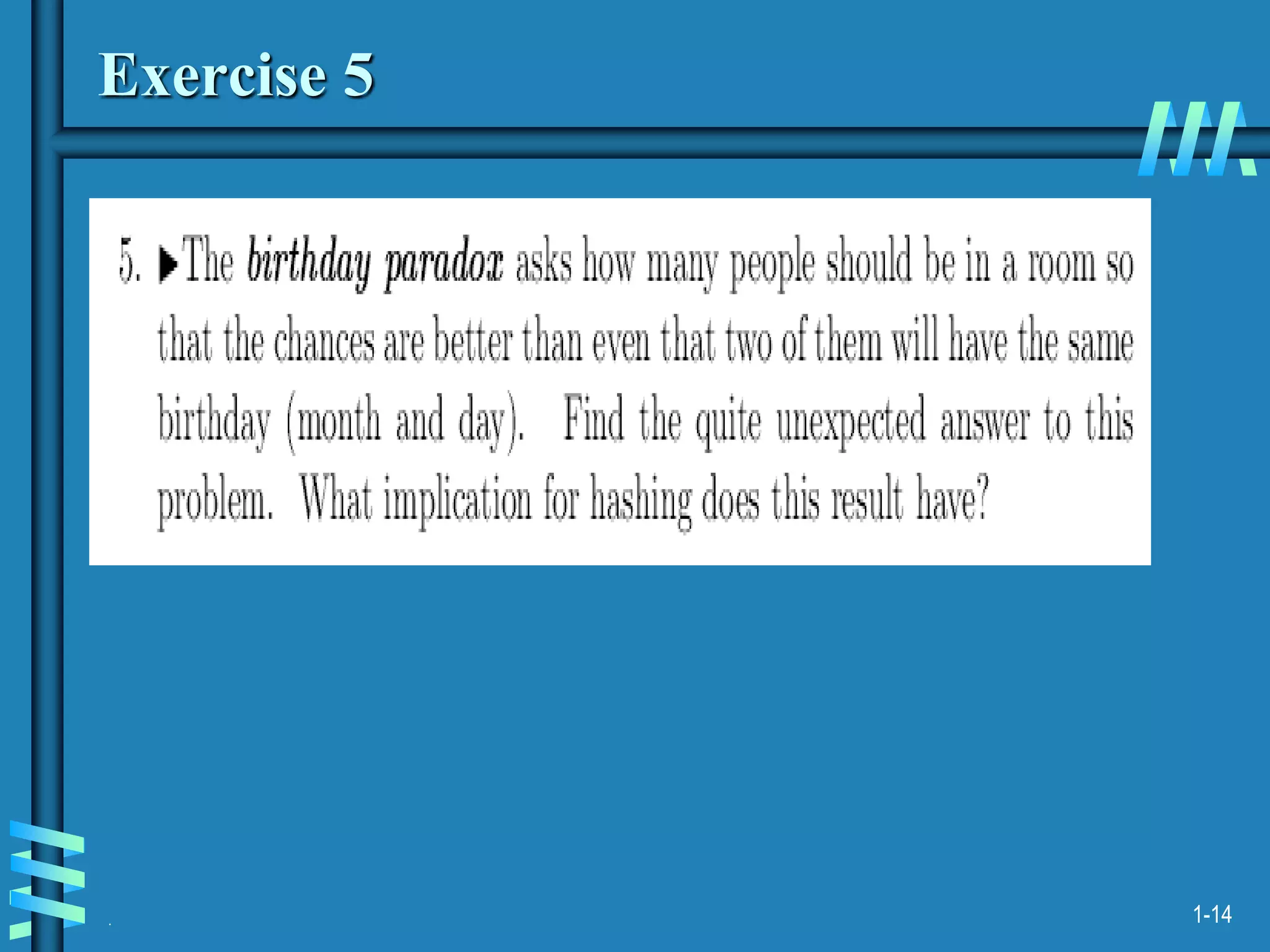
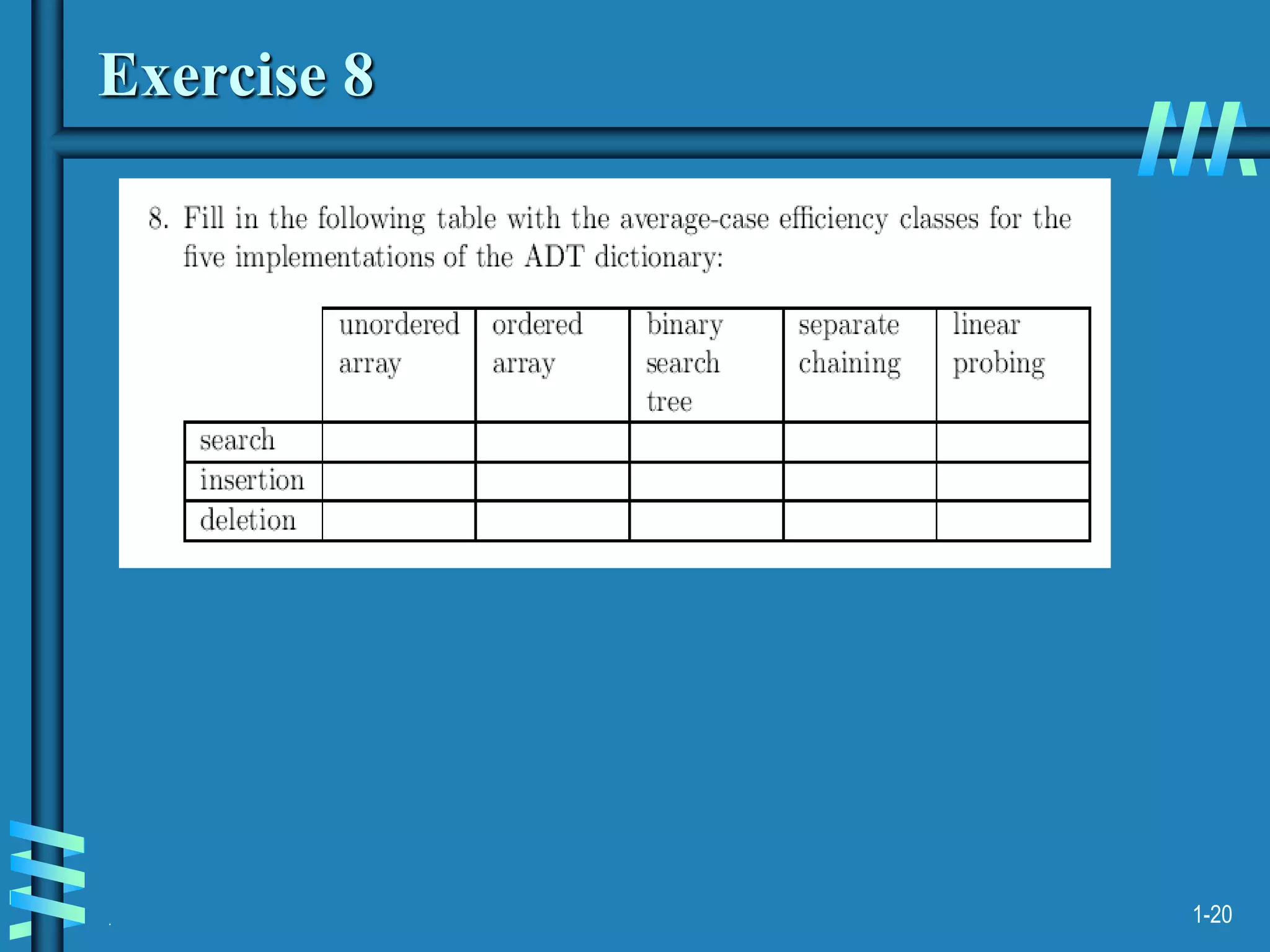
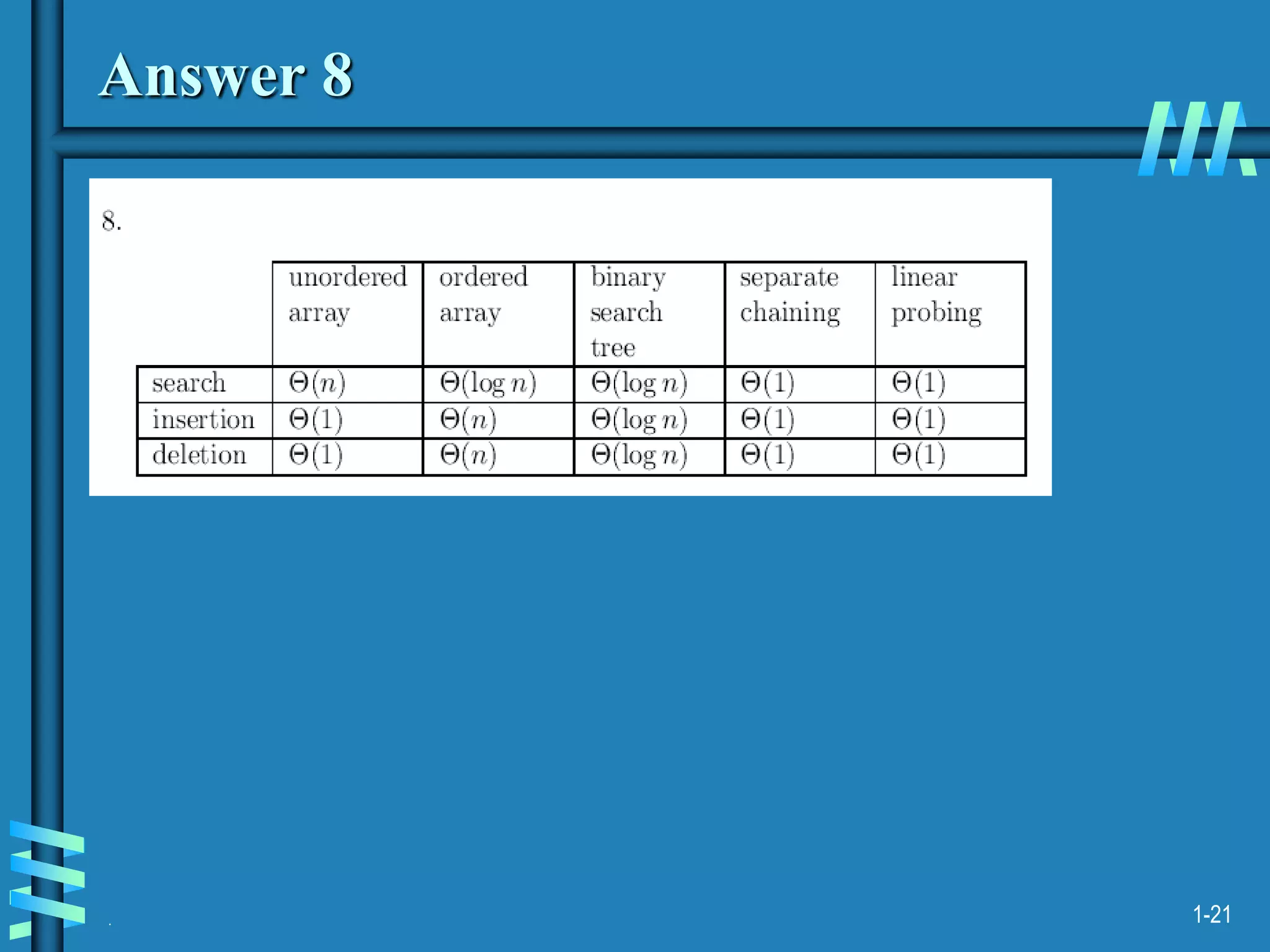
1. The document discusses algorithms for handling collisions in hashing, including open hashing which uses separate chaining with linked lists, and closed hashing which resolves collisions through techniques like linear probing.
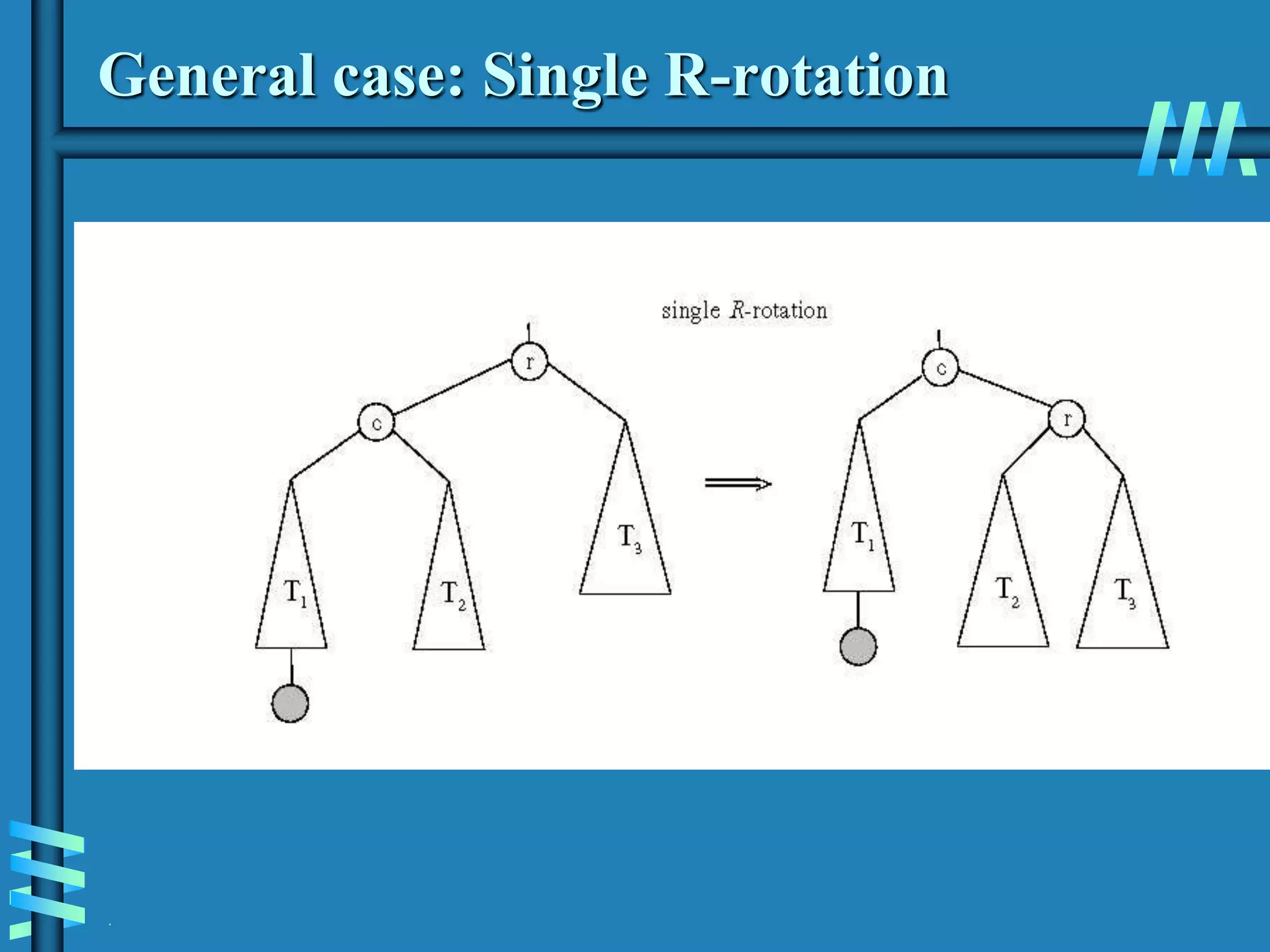
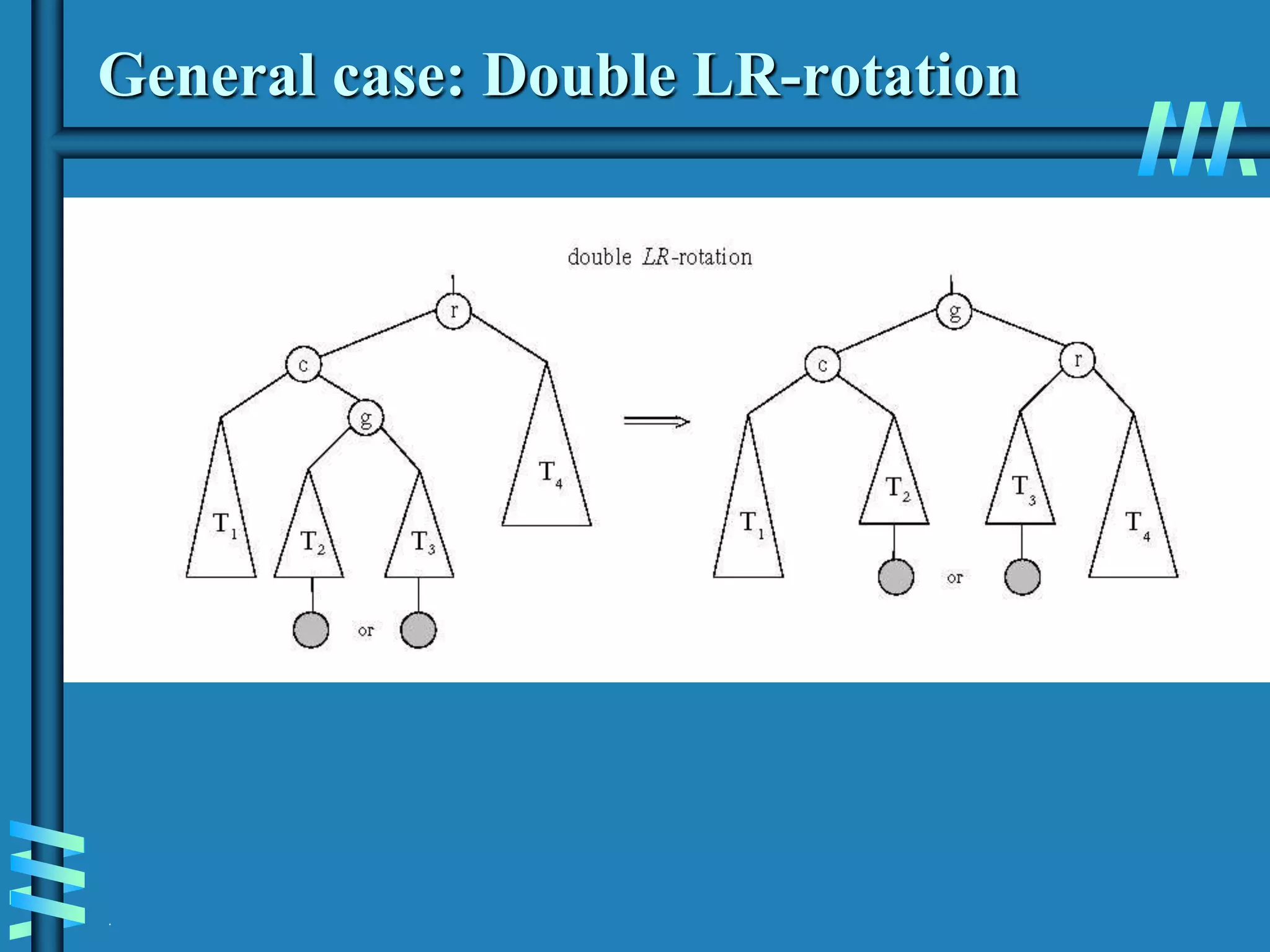
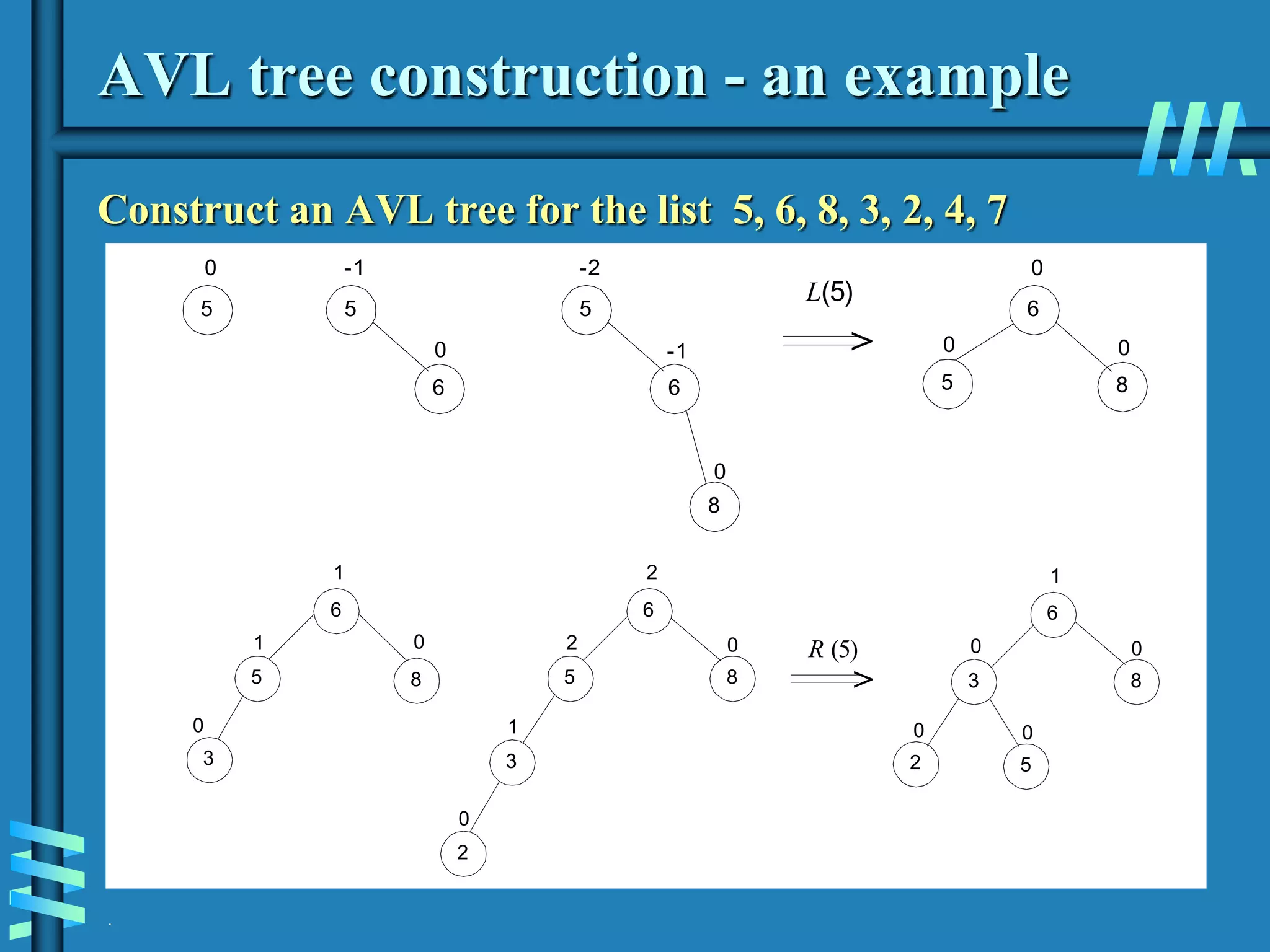
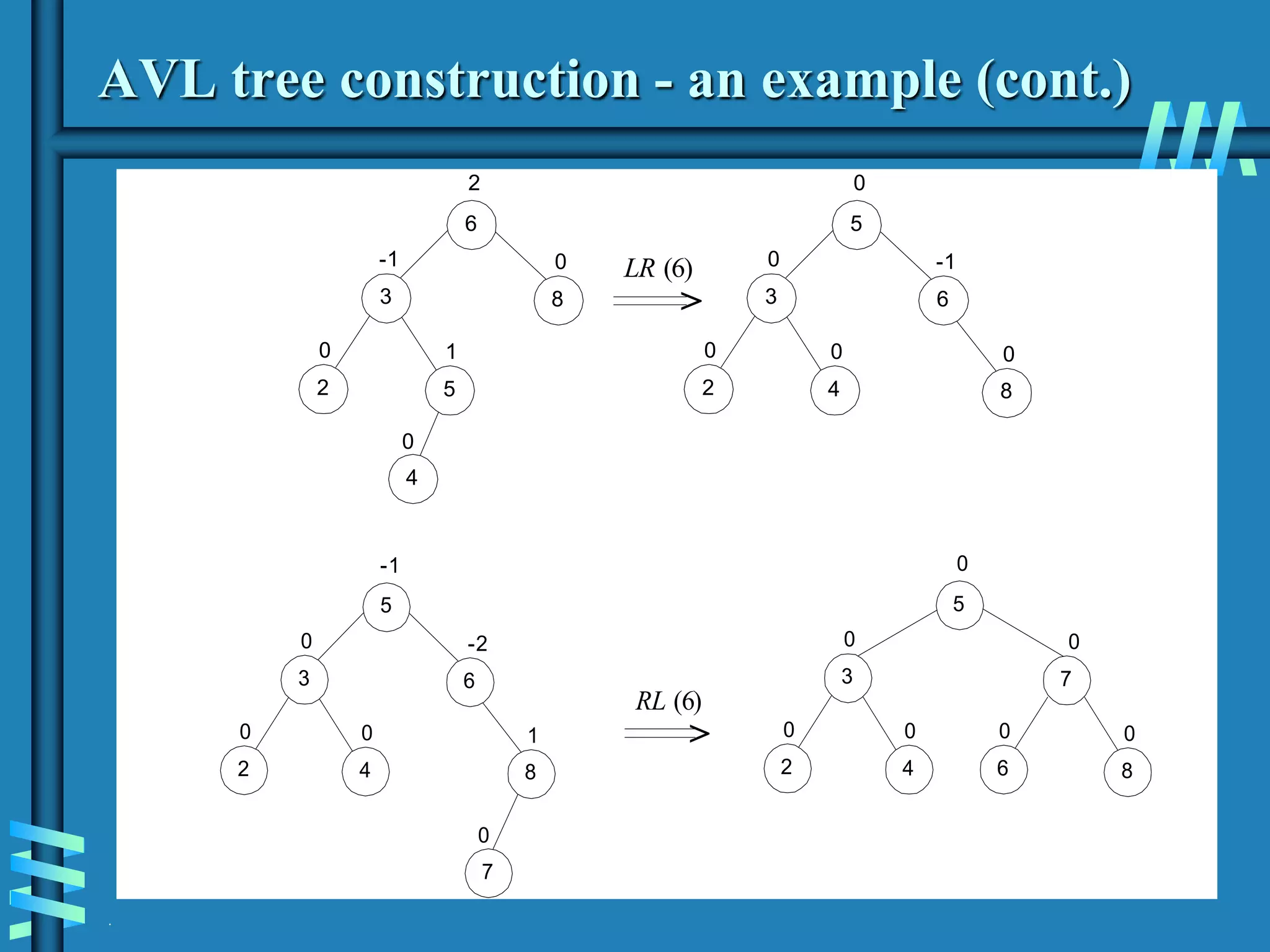
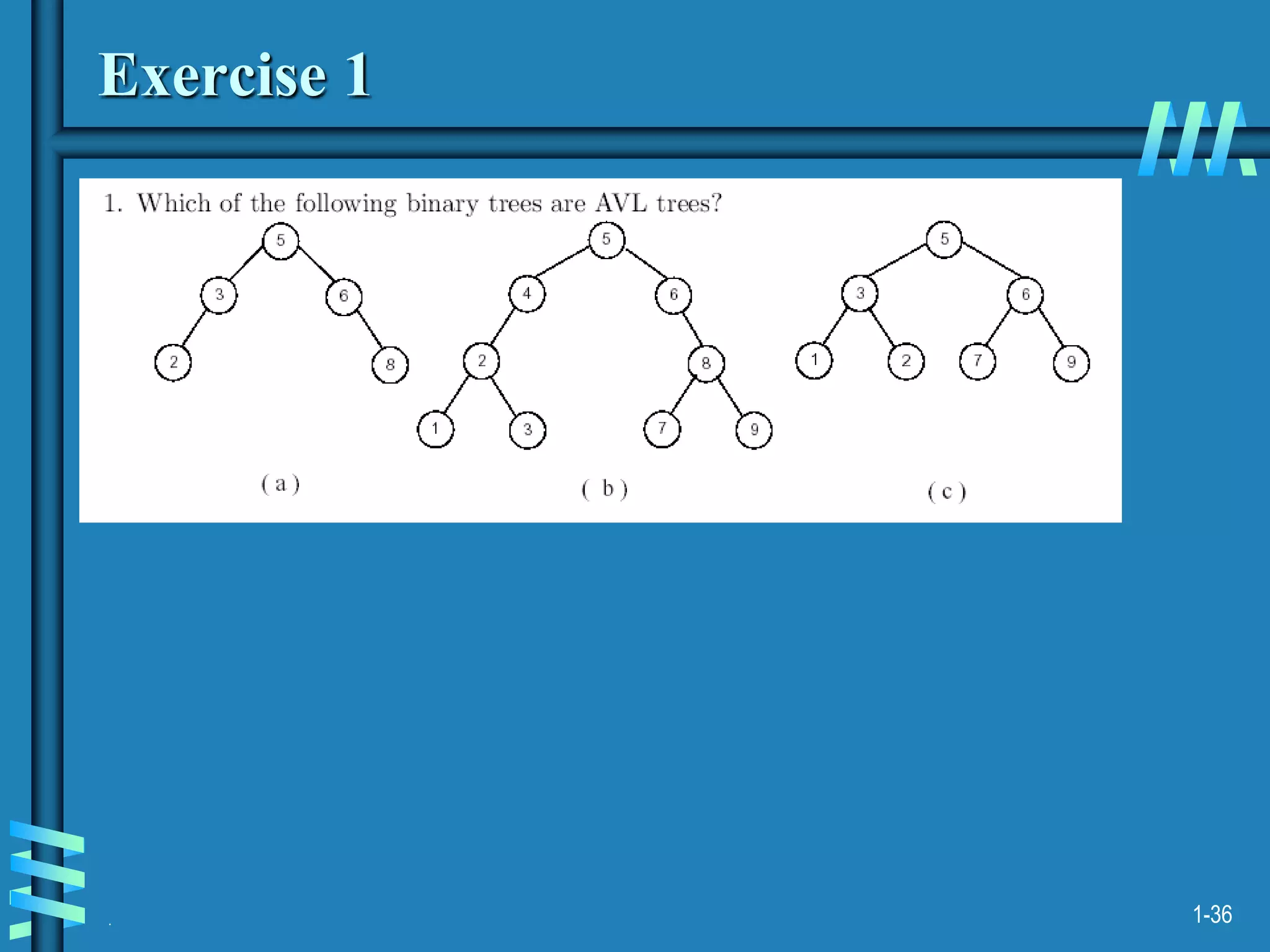
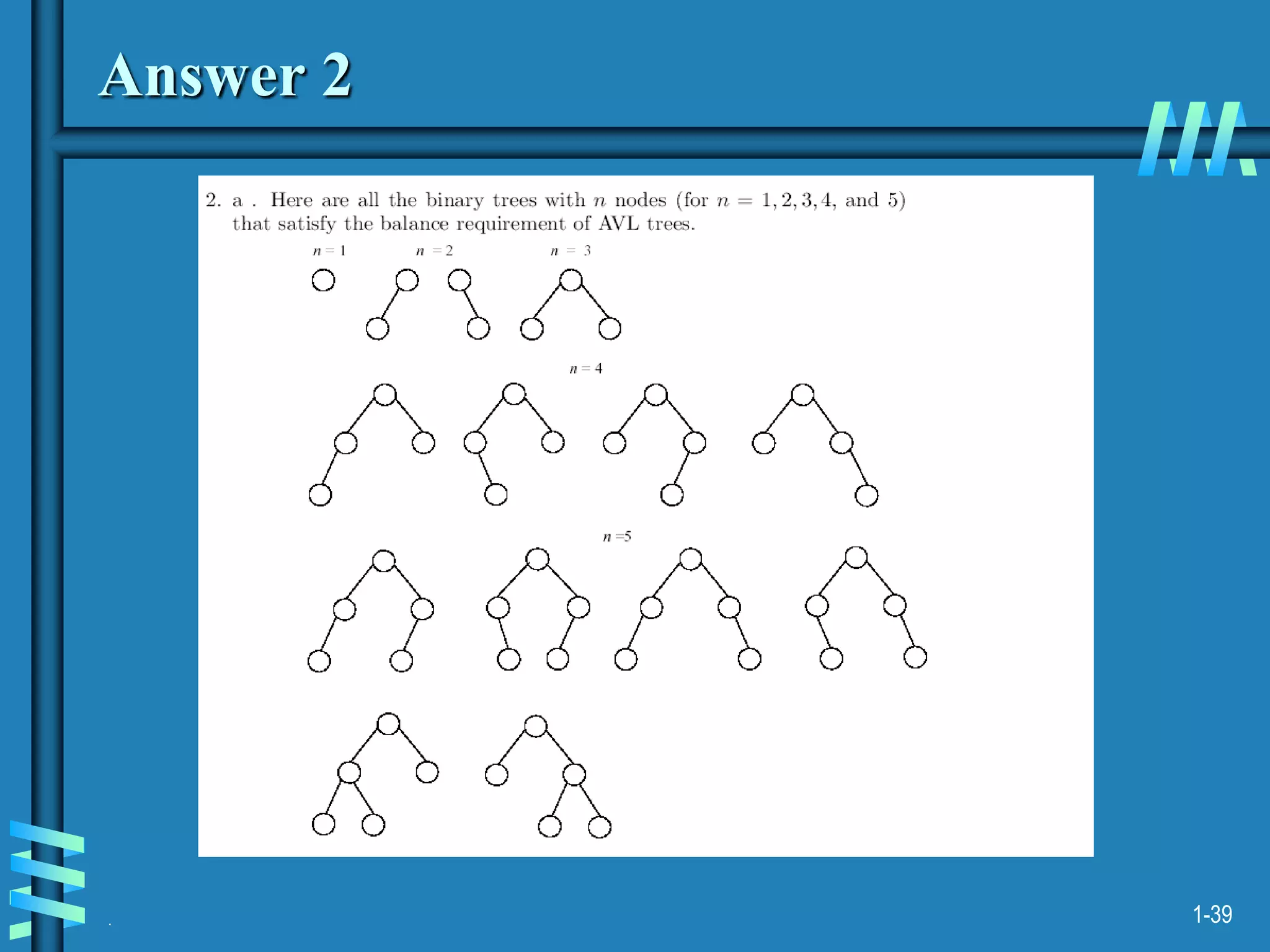
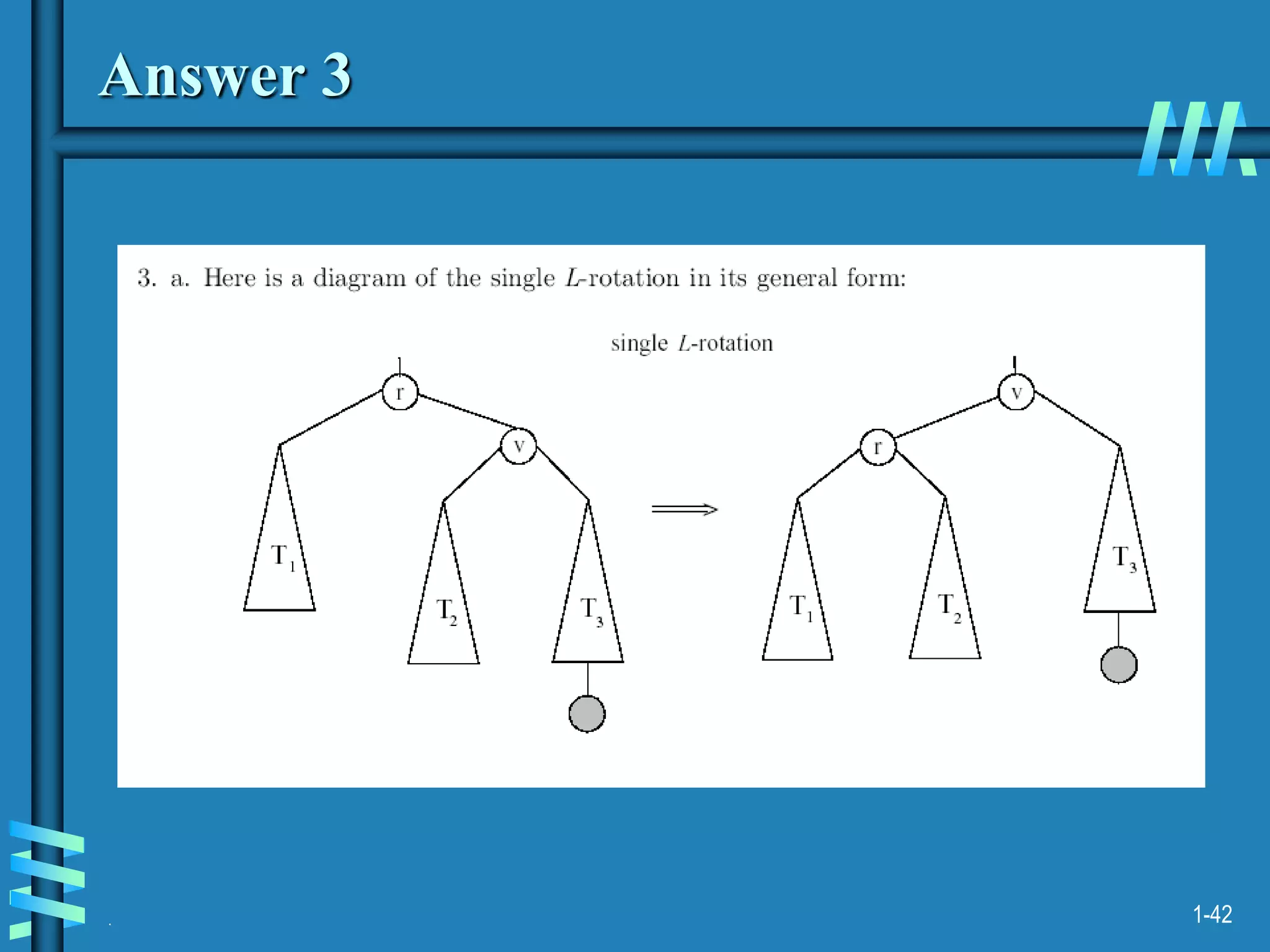
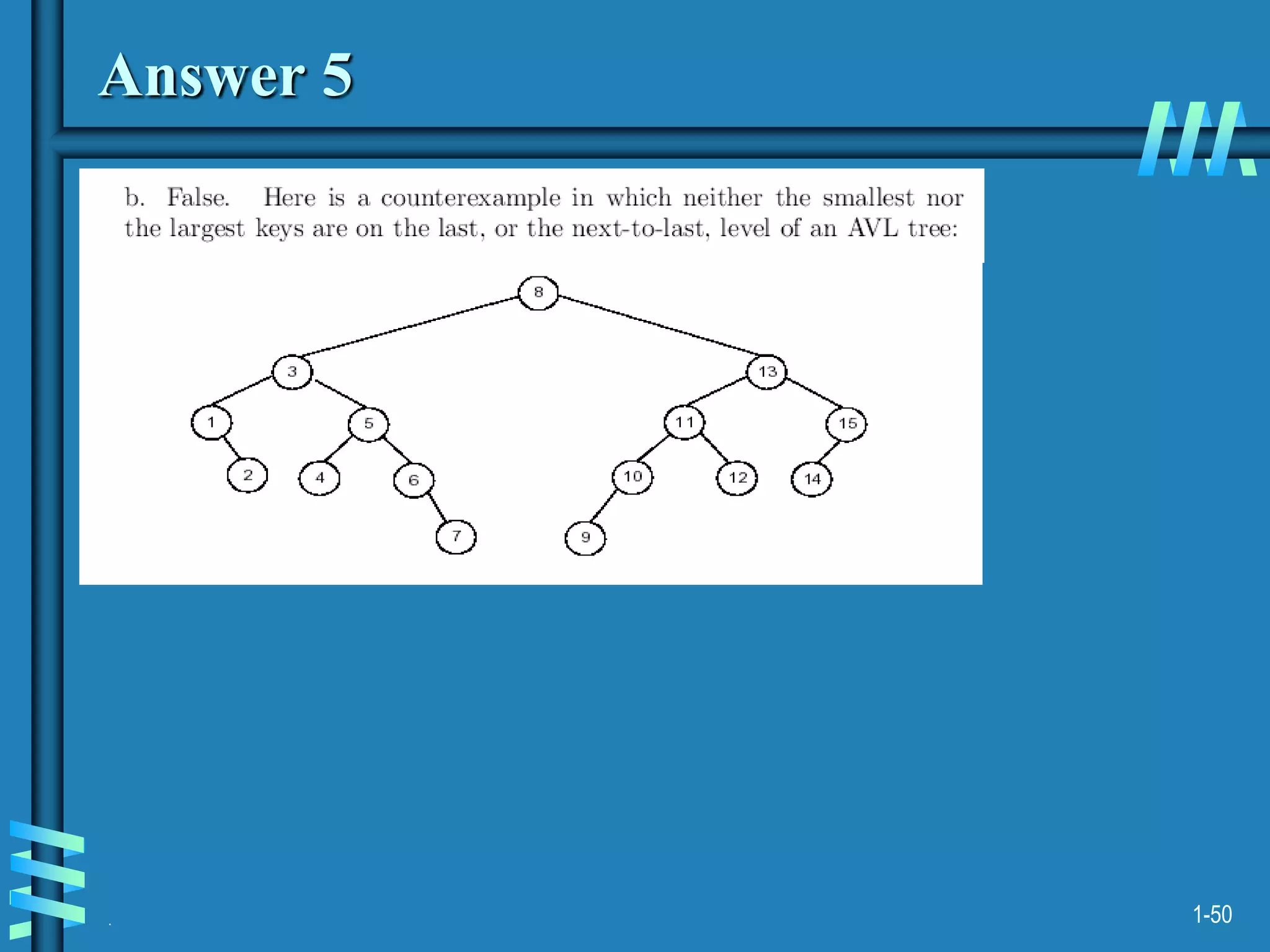
2. It also discusses binary search trees and their operations, as well as balanced search trees like AVL and red-black trees which have logarithmic time performance.
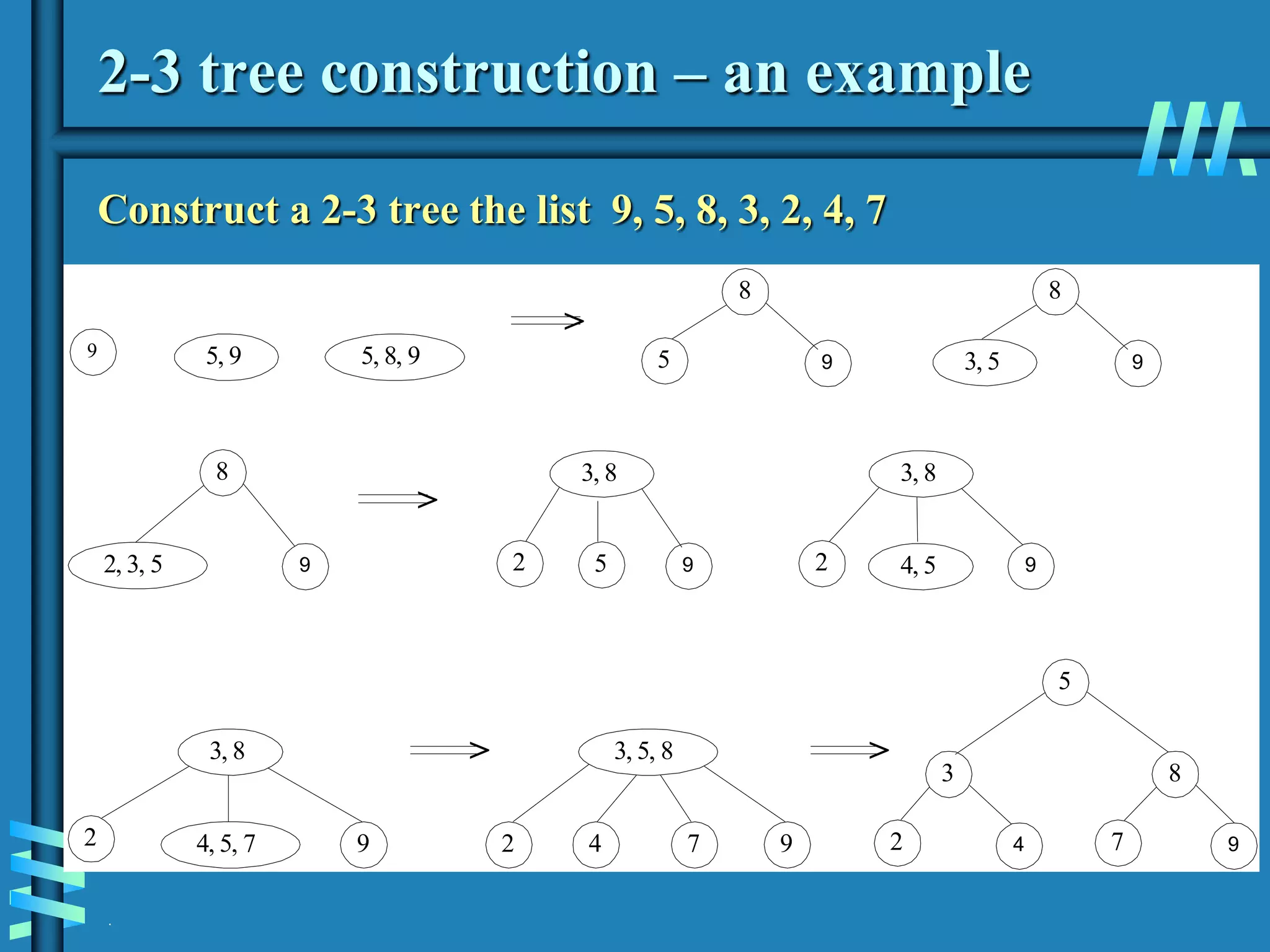
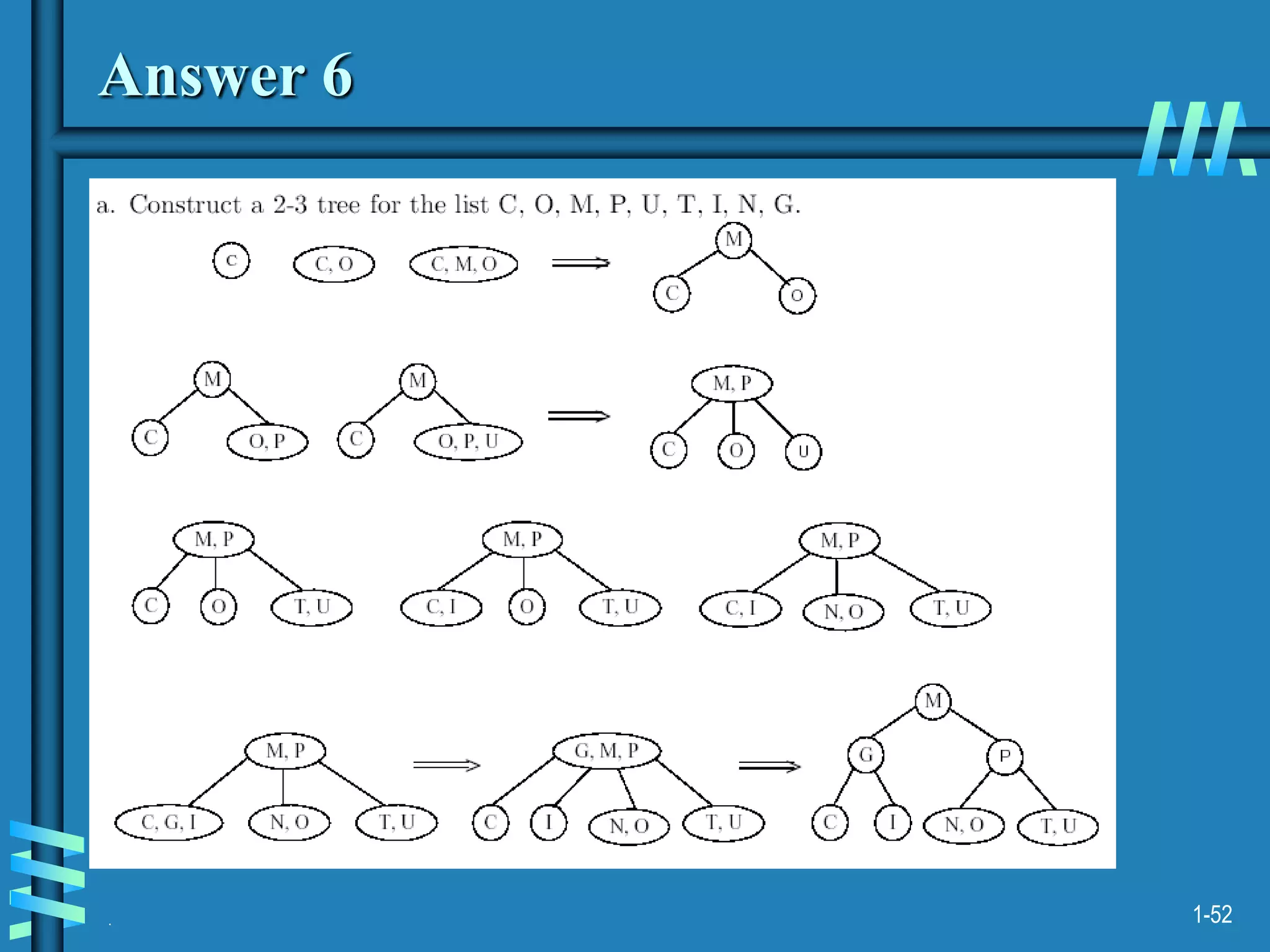
3. Finally, it covers multiway search trees including 2-3 trees and how they allow for more than one key per node, providing improved time performance over standard binary search trees.