Download to read offline






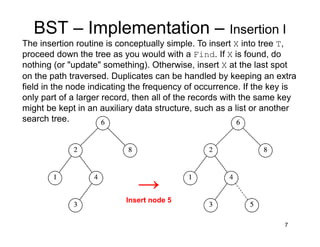


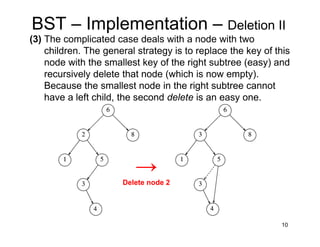







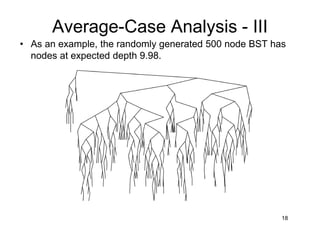
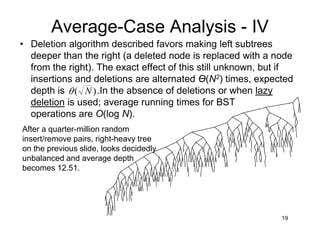

This document discusses binary search trees (BSTs). It describes how BSTs are structured, with each node containing a value greater than all values in its left subtree and less than all values in its right subtree. It then summarizes common BST operations like insertion, deletion, finding minimum/maximum values, and provides pseudocode implementations. The average-case runtime of these operations is analyzed, showing that since the average depth of a BST is O(log N), most operations take O(log N) time on average. Repeated insertions and deletions can cause imbalance and increase the average depth to O(√N).

































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)


















