サイボウズ・ラボユース成果発表会2015/03/27 8
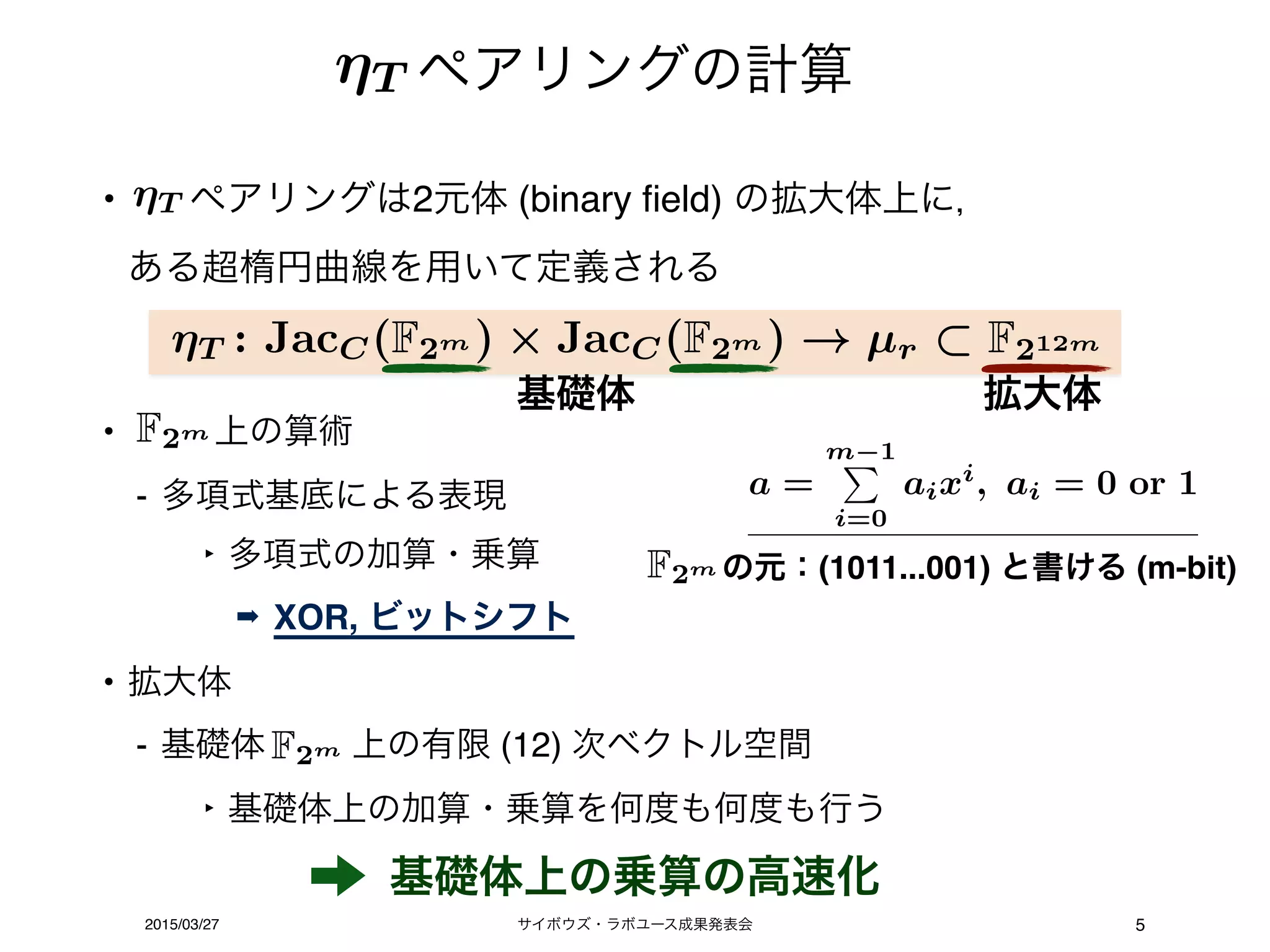
結果(SIMD実装)
OS Windows8.1
CPU Intel Core i7-3520M, 2.90GHz, 2 cores
Memory DDR3-1333, 5.60 GB
Compiler Visual C++ 2013 Preview, gcc 4.8.2
SIMD instruction SSE2, 4.1, 4.2
methods of multiplication VC++ gcc
comb method 160 150
comb method with load shift 131 104
window method (window size: 6) 50 41
window method with load shift
(window size: 4) 49 33
timings of pairing (ms)T (m = 487)
• 先行研究の最新結果(対称ペアリング)
‣ 16.4 million clock cycles (Core 2 processor), m=439
‣ 2.75 million clock cycles (Core i5 32nm processor), m=367
まだ遅い
9.
サイボウズ・ラボユース成果発表会2015/03/27
複数ペアリングのGPU並列実装
9
• GPGPU: GPUを用いた汎用系算の並列化,その技術
-シミュレーション,暗号解読,暗号実装
• CUDA: NVIDIAが提供する開発環境
• 複数ペアリングの並列実装
- ペアリング等暗号関数単体のGPUによる並列化は基本的に非効率
- 関数型暗号等のプロトコルは多くのペアリング計算が必要
- 各ペアリングを独立に並列計算し,それらの体上の演算も並列化(二重)
‣ 乗算はLeft-to-right comb window methodによる
- 国際会議へ投稿:
“Parallel GPU Implementation of Pairing over Fields of Characteristic
Two” (ICNCS2014)
T
10.
サイボウズ・ラボユース成果発表会2015/03/27 10
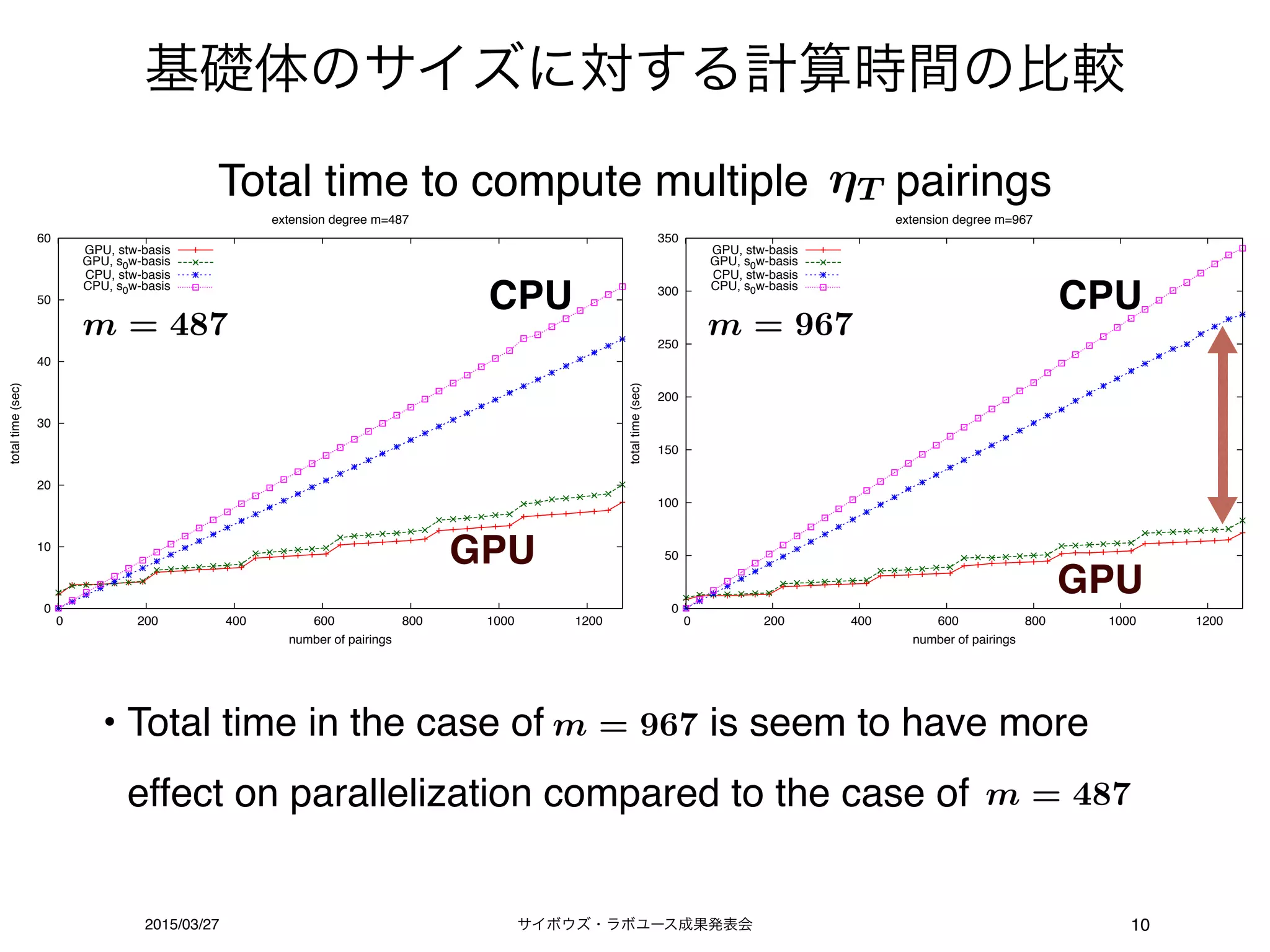
基礎体のサイズに対する計算時間の比較
• Totaltime in the case of is seem to have more
effect on parallelization compared to the case of
0
10
20
30
40
50
60
0 200 400 600 800 1000 1200
totaltime(sec)
number of pairings
extension degree m=487
GPU, stw-basis
GPU, s0w-basis
CPU, stw-basis
CPU, s0w-basis
0
50
100
150
200
250
300
350
0 200 400 600 800 1000 1200
totaltime(sec) number of pairings
extension degree m=967
GPU, stw-basis
GPU, s0w-basis
CPU, stw-basis
CPU, s0w-basis
m = 487 m = 967
CPU CPU
GPU
GPU
Total time to compute multiple pairingsT
m = 487
m = 967
11.
サイボウズ・ラボユース成果発表会2015/03/27 11
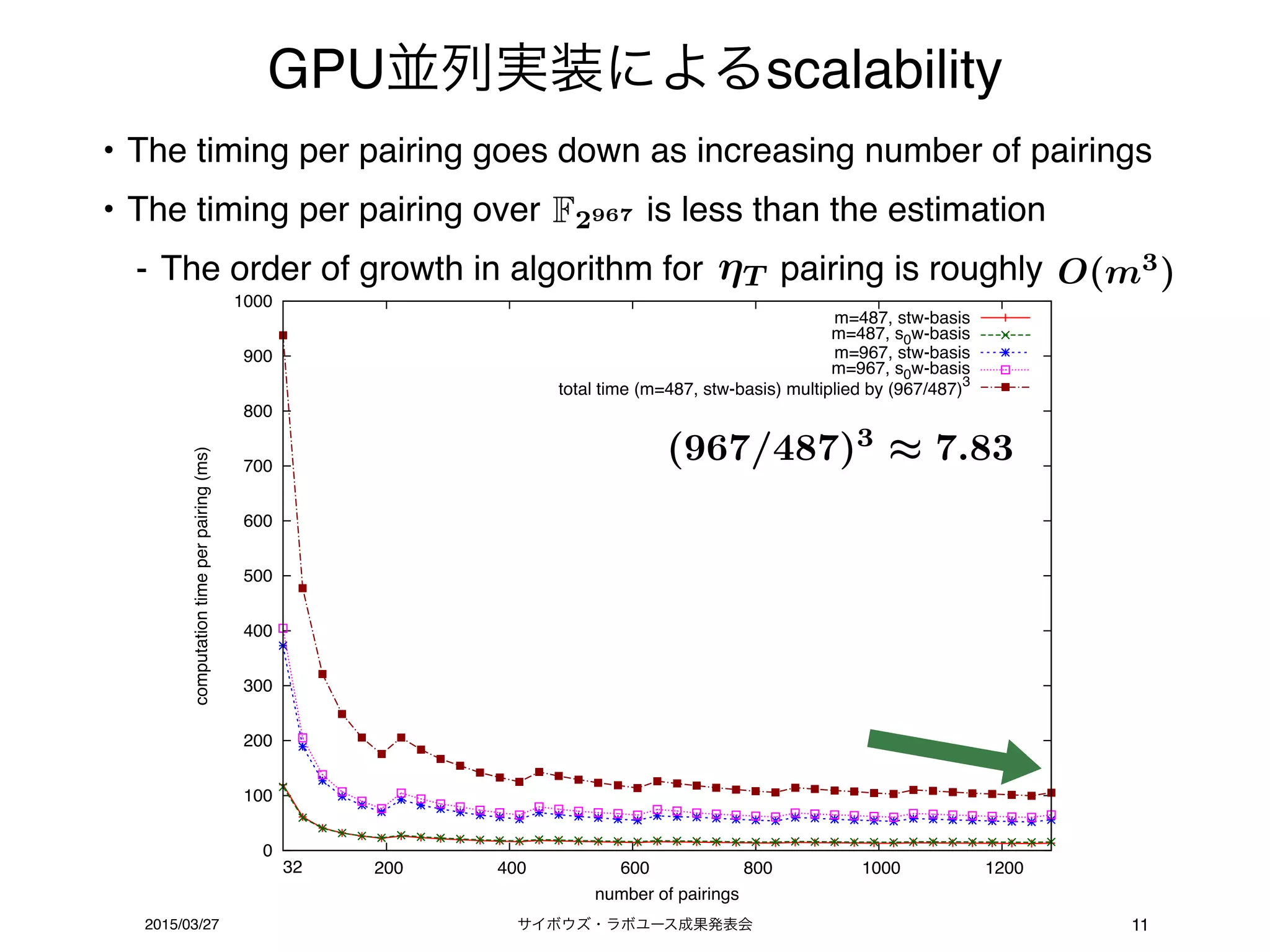
GPU並列実装によるscalability
• Thetiming per pairing goes down as increasing number of pairings
• The timing per pairing over is less than the estimation
- The order of growth in algorithm for pairing is roughly
0
100
200
300
400
500
600
700
800
900
1000
200 400 600 800 1000 1200
computationtimeperpairing(ms)
number of pairings
32
m=487, stw-basis
m=487, s0w-basis
m=967, stw-basis
m=967, s0w-basis
total time (m=487, stw-basis) multiplied by (967/487)3
(967/487)3
7.83
T
F2967
O(m3
)
12.
サイボウズ・ラボユース成果発表会2015/03/27
脆弱化・次世代セキュリティレベル
12
• セキュリティレベルの低下
- 小標数の体におけるDLPを解くアルゴリズムに
大きなブレークスルー[Jou13, BGJT14]
‣対称ペアリングのセキュリティレベルが致命的に下がり実質使用不可
[Jou13] A. Joux: A New Index Calculus Algorithm with Complexity L(1/4 + o(1)) in Very Small Characteristic, 2013
[BGJT14] R. Barbulescu, P. Gaudry, A. Joux, and E. Thomé: A Heuristic Quasi-Polynomial Algorithm for Discrete Logarithm in Finite Fields of Small Characteristic
楕円曲線上のDLP 有限体上のDLP
e: E(Fpk )[r] E(Fpk )[r] µr Fpk
各セキュレティレベルにおける 長の比較
セキュリティレベル Factoring Modulus DL Key DL Group Elliptic Curve
80 (Legacy) 1248 1248 160 160
128 (2011 - 2030) 3248 3248 256 256
192 (>> 2030) 7936 7936 384 384
256 (>>> 2030) 15424 15424 512 512
ECRYPT II and NIST Recommendations on “Keylength”: http://www.keylength.com



![サイボウズ・ラボユース成果発表会2015/03/27
登場人物・背景
4
• ペアリング暗号?
- 公開 暗号方式の一つ
‣ メジャーな公開 暗号方式
✓ RSA: 素因数分解
✓ 楕円曲線暗号:楕円曲線上の離散対数問題
- ペアリングそのもの
‣ (超)楕円曲線上に定義される双線形写像
• ターゲット
- ペアリング(対称ペアリング)
‣ シンプル・高速
‣ 現在,暗号としてほぼ使えない程脆弱化
T
e(xP, Q) = e(P, Q)x
= e(P, xQ)
e: E(Fpk )[r] E(Fpk )[r] µr Fpk](https://image.slidesharecdn.com/finalreport-150327174546-conversion-gate01/75/slide-4-2048.jpg)


![サイボウズ・ラボユース成果発表会2015/03/27
脆弱化・次世代セキュリティレベル
12
• セキュリティレベルの低下
- 小標数の体におけるDLPを解くアルゴリズムに
大きなブレークスルー [Jou13, BGJT14]
‣対称ペアリングのセキュリティレベルが致命的に下がり実質使用不可
[Jou13] A. Joux: A New Index Calculus Algorithm with Complexity L(1/4 + o(1)) in Very Small Characteristic, 2013
[BGJT14] R. Barbulescu, P. Gaudry, A. Joux, and E. Thomé: A Heuristic Quasi-Polynomial Algorithm for Discrete Logarithm in Finite Fields of Small Characteristic
楕円曲線上のDLP 有限体上のDLP
e: E(Fpk )[r] E(Fpk )[r] µr Fpk
各セキュレティレベルにおける 長の比較
セキュリティレベル Factoring Modulus DL Key DL Group Elliptic Curve
80 (Legacy) 1248 1248 160 160
128 (2011 - 2030) 3248 3248 256 256
192 (>> 2030) 7936 7936 384 384
256 (>>> 2030) 15424 15424 512 512
ECRYPT II and NIST Recommendations on “Keylength”: http://www.keylength.com](https://image.slidesharecdn.com/finalreport-150327174546-conversion-gate01/75/slide-12-2048.jpg)


















![[Ridge-i 論文よみかい] Wasserstein auto encoder](https://cdn.slidesharecdn.com/ss_thumbnails/wassersteinauto-encoder-181006055019-thumbnail.jpg?width=640&height=640&fit=bounds)






![[20170922 Sapporo Tech Bar] 地図用データを高速処理!オープンソースGPUデータベースMapDってどんなもの?? by 株式会社...](https://cdn.slidesharecdn.com/ss_thumbnails/20170922mapd-170926064811-thumbnail.jpg?width=640&height=640&fit=bounds)








































