


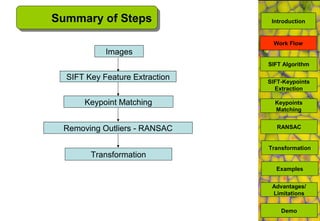


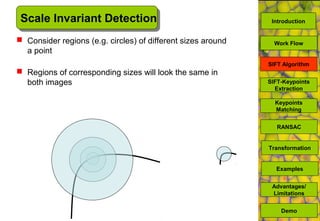

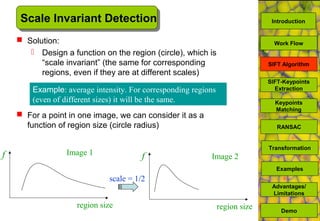
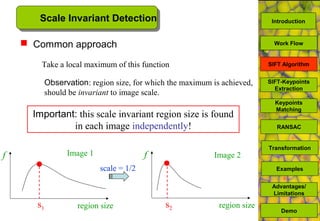
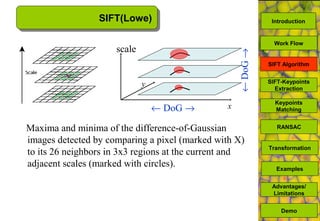
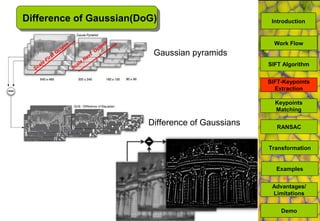
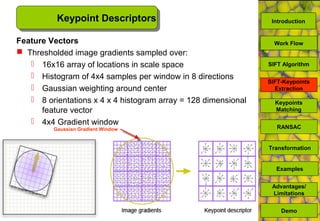














The document discusses a MATLAB procedure aimed at detecting levelling rods using the SIFT algorithm developed by David Lowe, which involves keypoint extraction and matching. It covers the algorithm's ability to identify invariant features across transformations, including scaling and rotation, utilizing methods like RANSAC to filter outliers. The final results indicate the algorithm's effectiveness, while also noting some limitations regarding image types and transformations.
































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)








