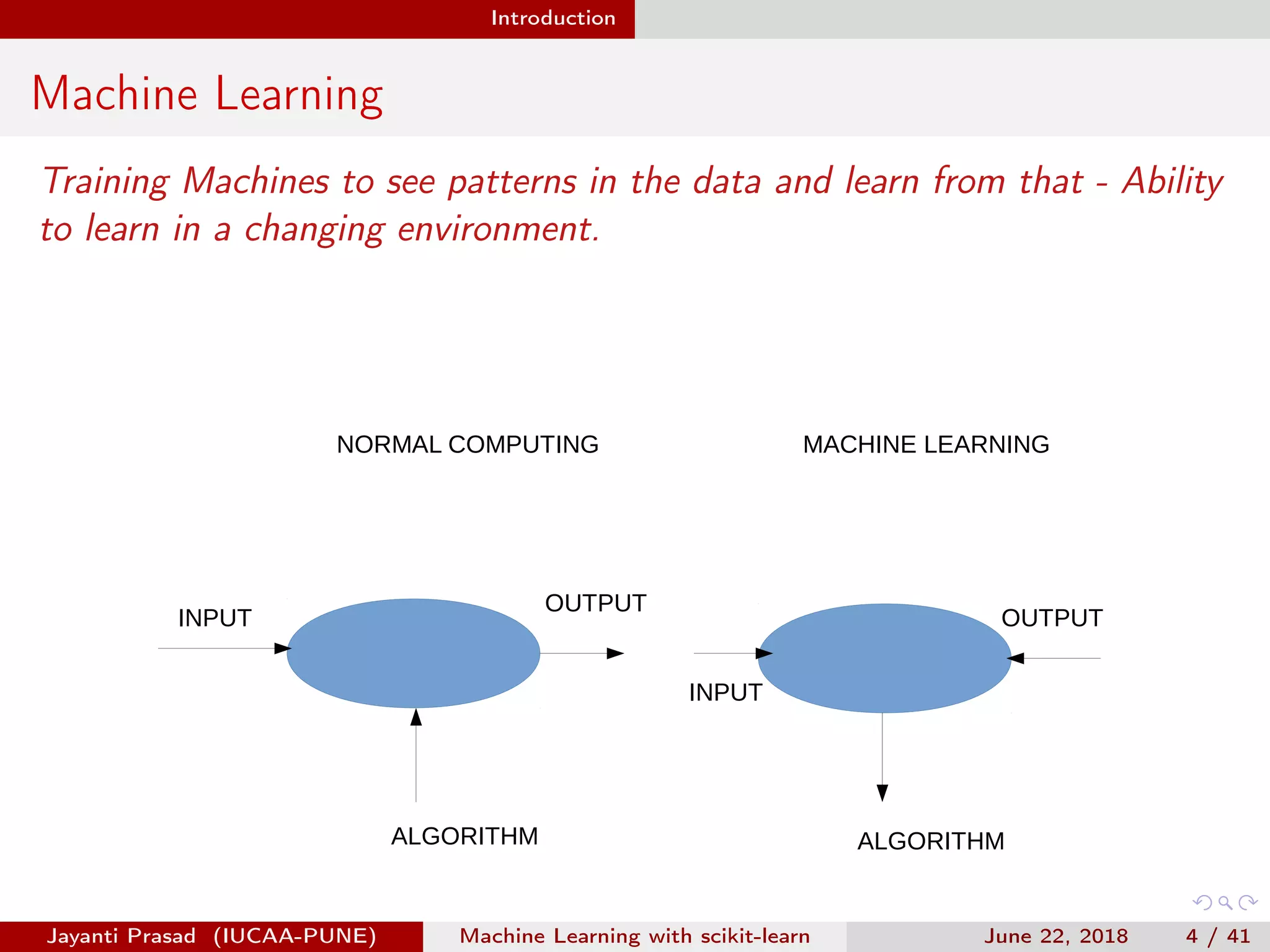
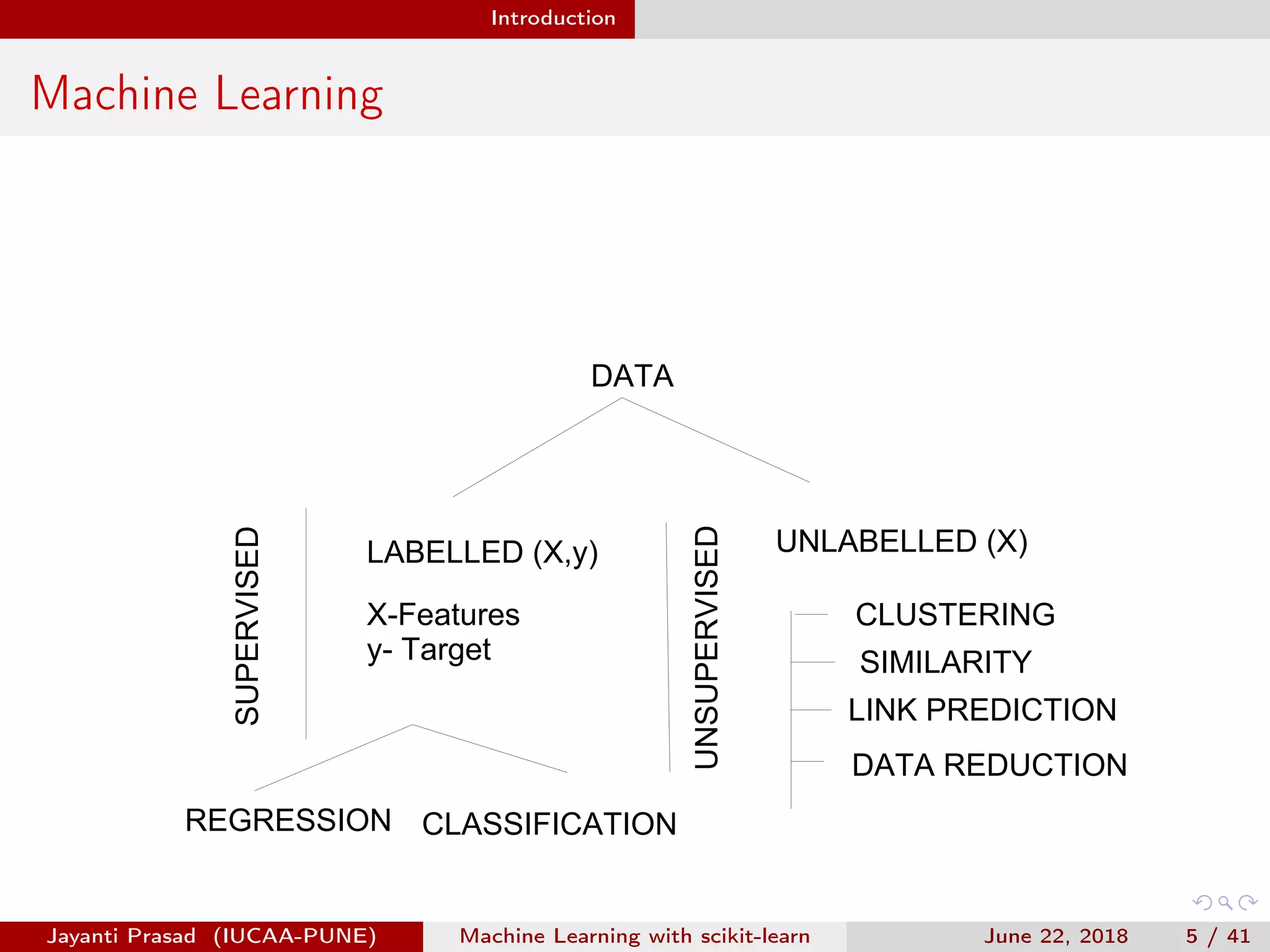
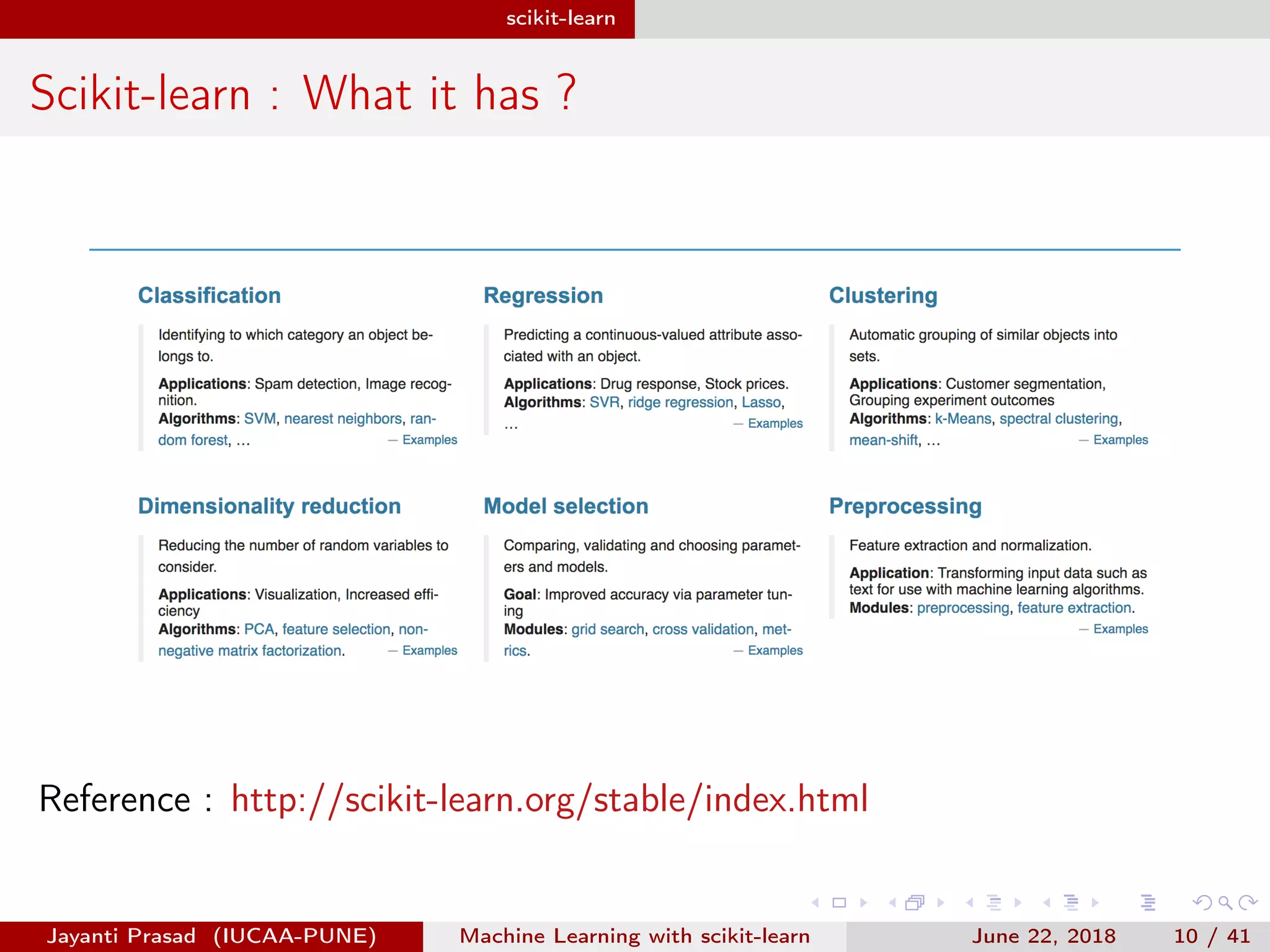
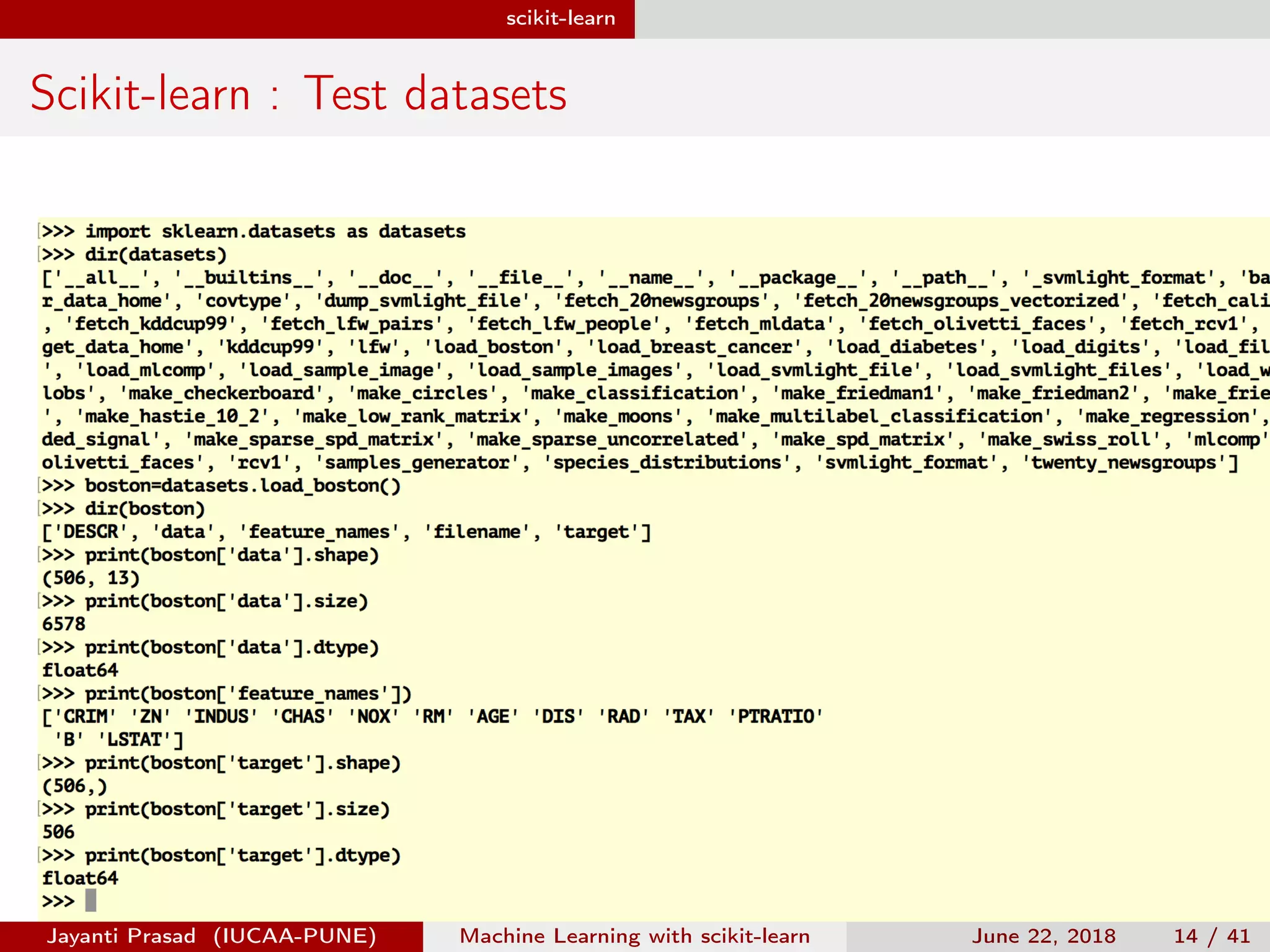
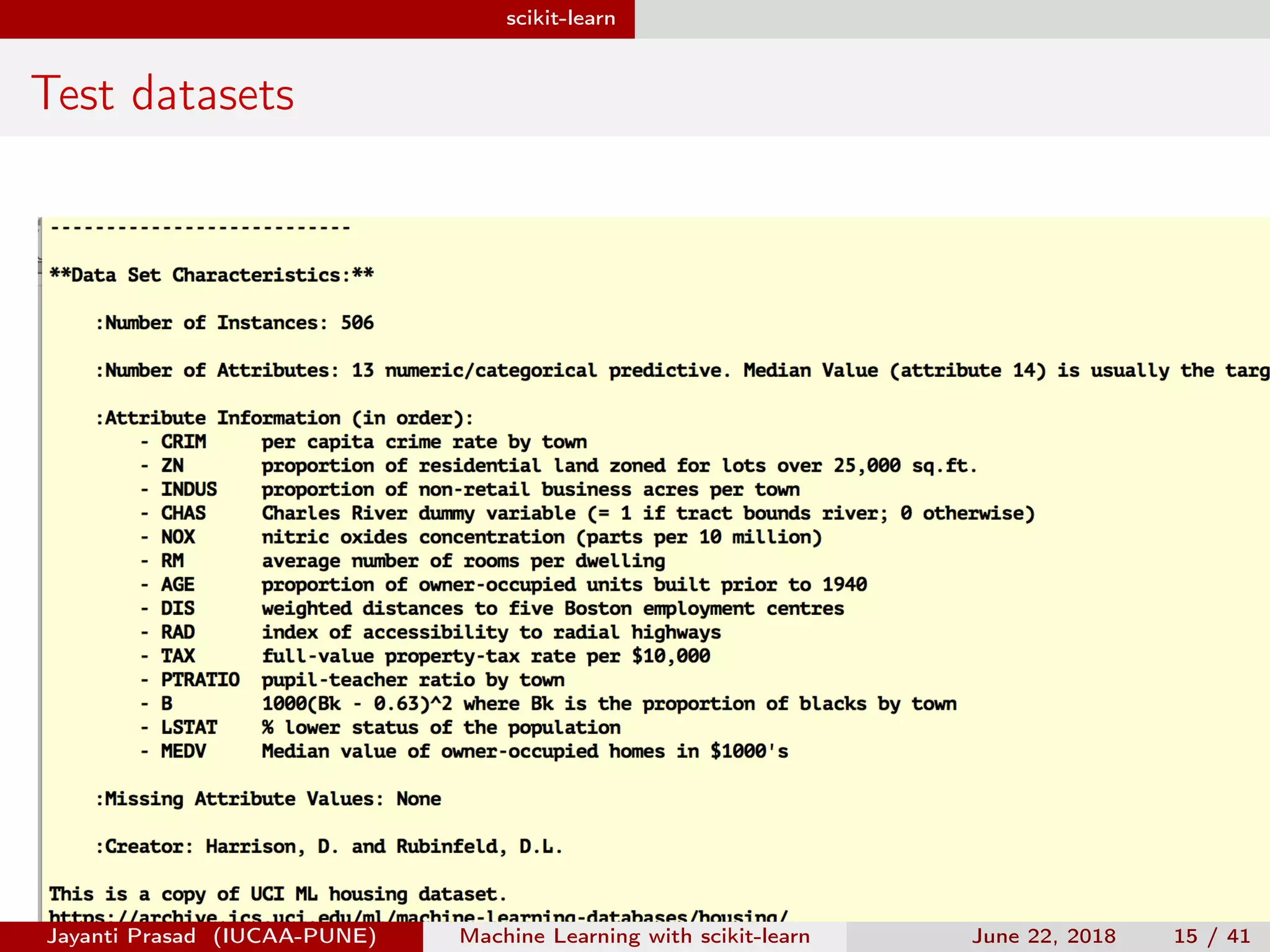
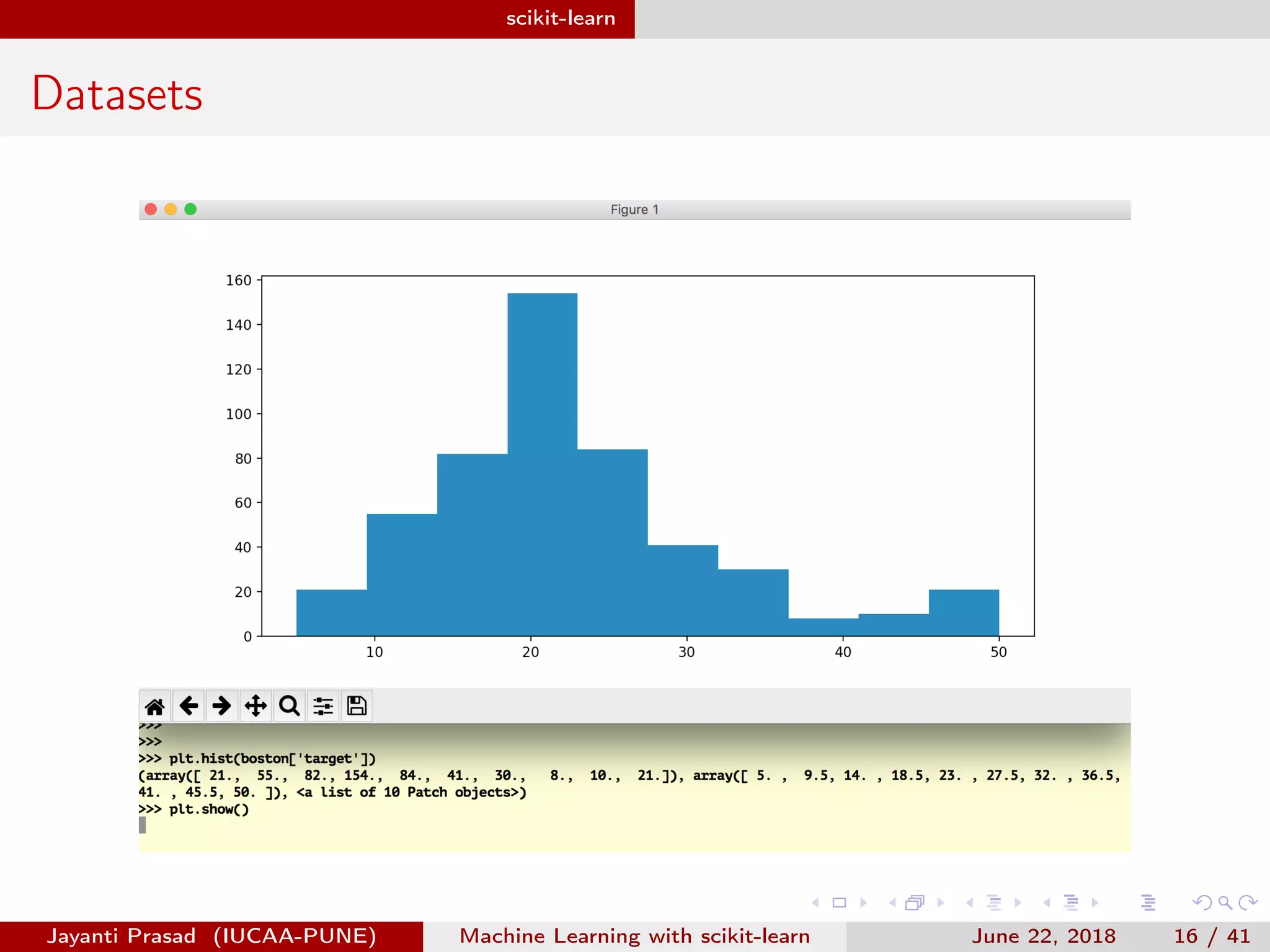
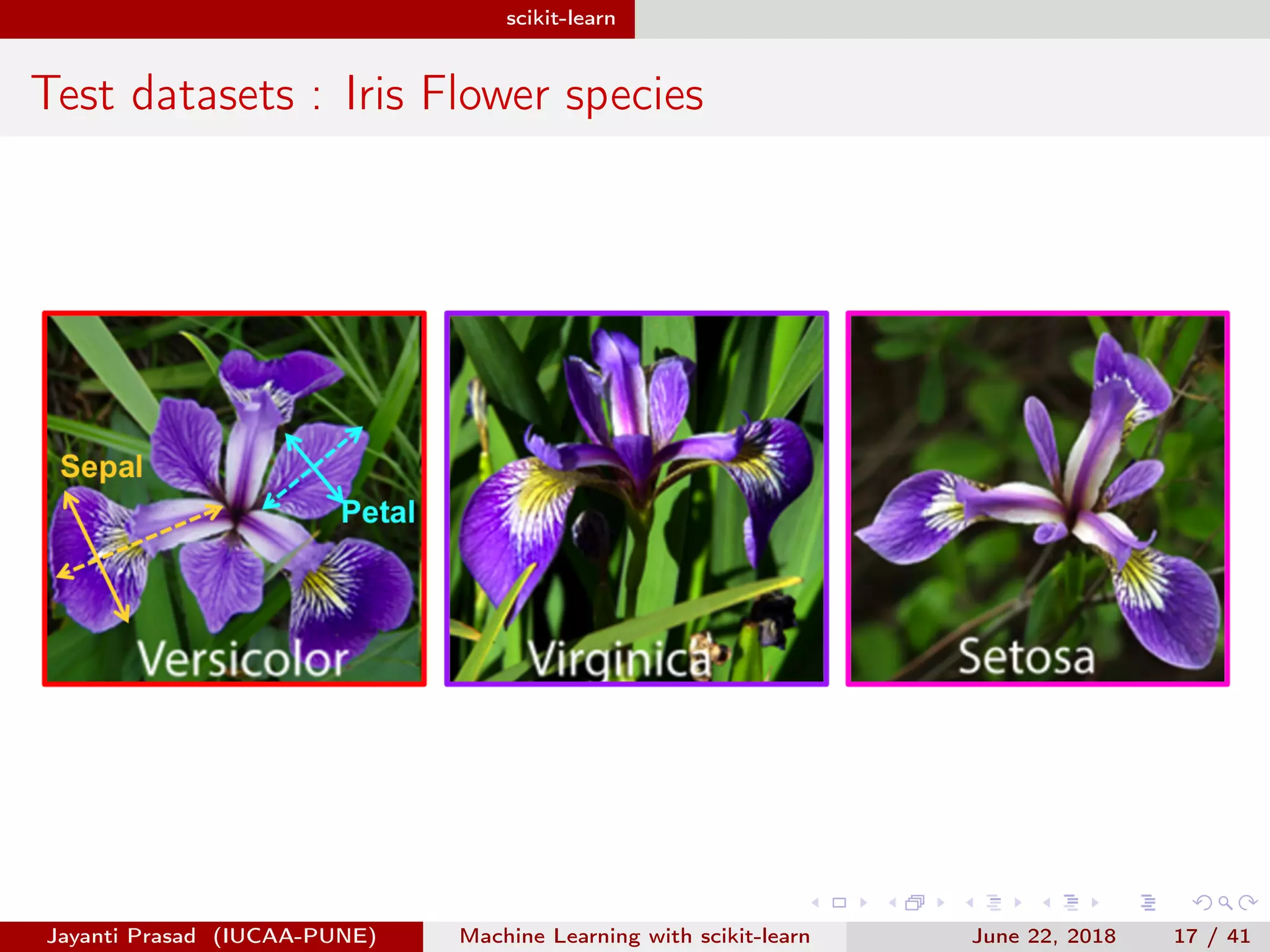
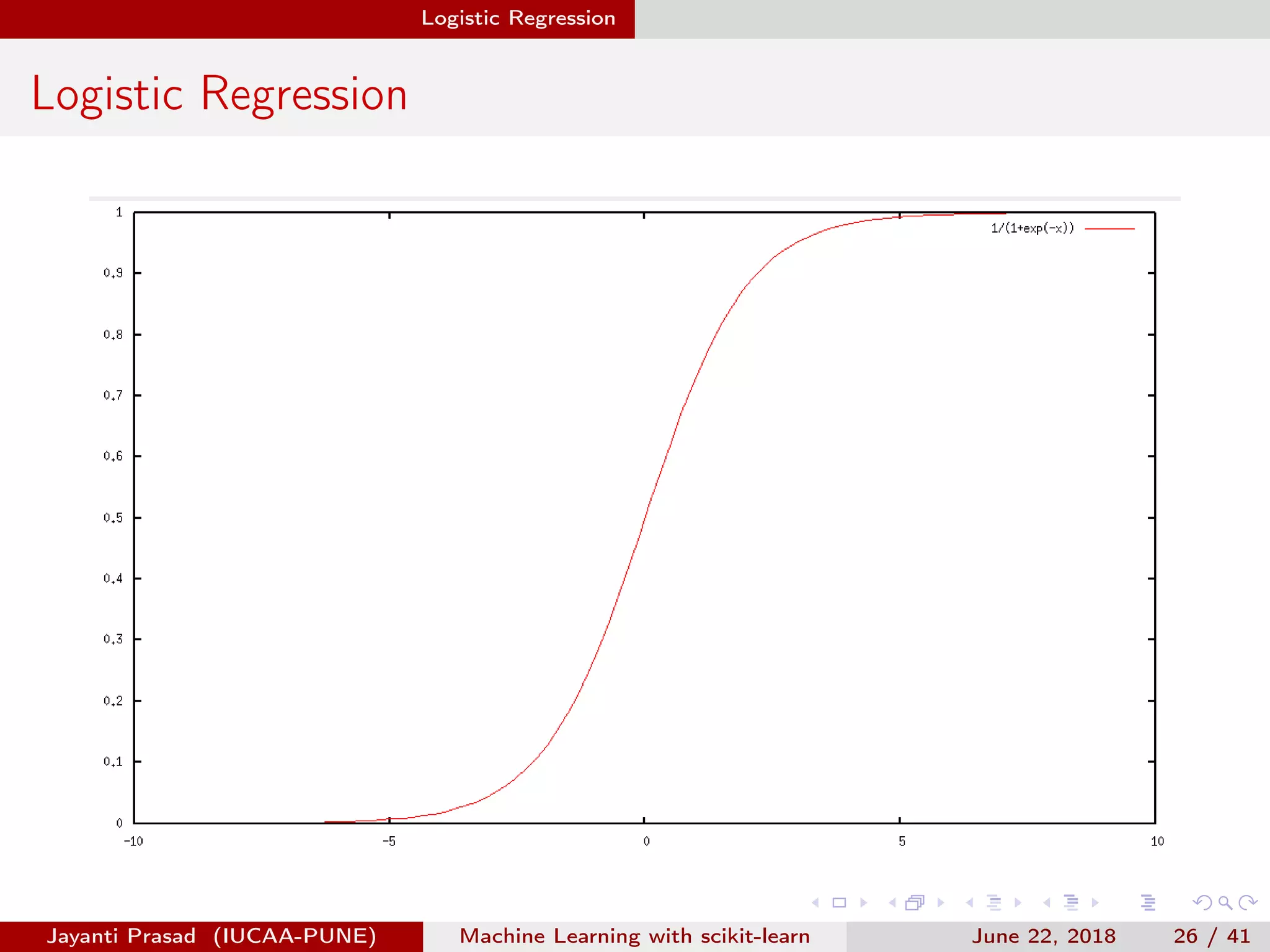
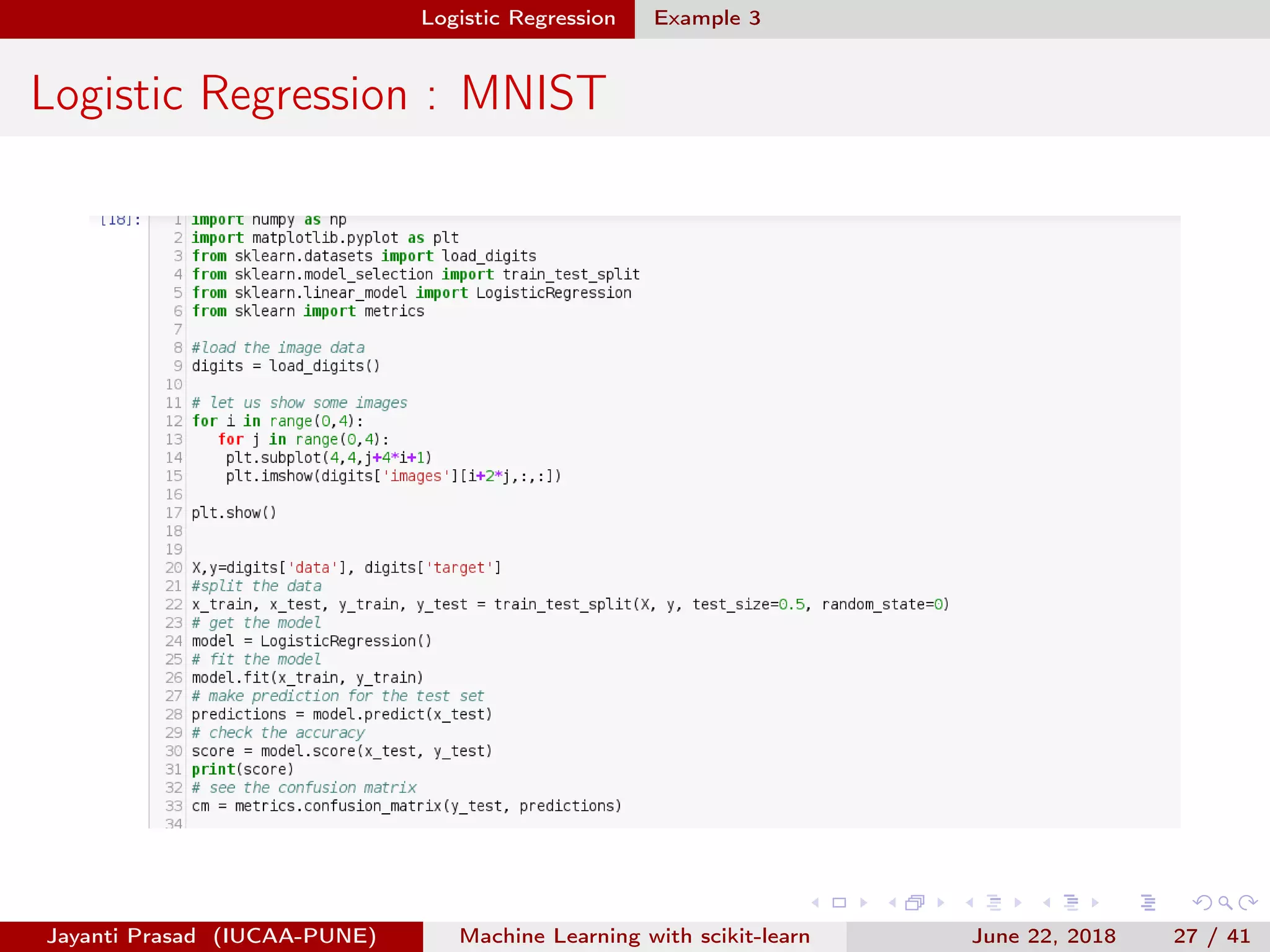
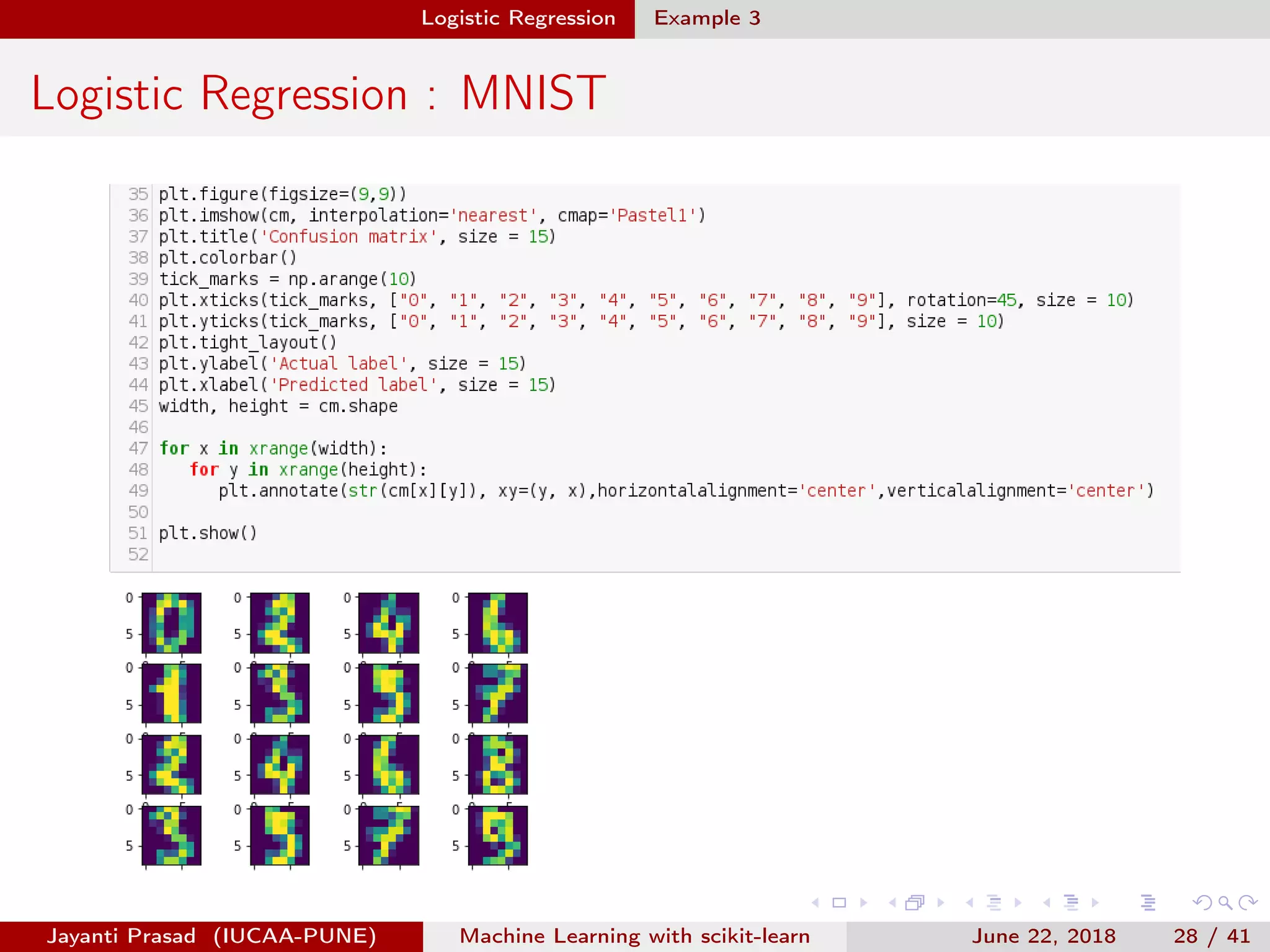
The document outlines Jayanti Prasad's presentation on machine learning with scikit-learn. The presentation covers an introduction to machine learning and scikit-learn, and examples of linear regression, logistic regression, and nearest neighbors algorithms using scikit-learn and datasets like Iris.










![Linear Regression Example 1
Linear Regression : Examples
[linear-regression-general.ipynb]
Jayanti Prasad (IUCAA-PUNE) Machine Learning with scikit-learn June 22, 2018 20 / 41](https://image.slidesharecdn.com/scikit-learn-180622105434/75/Scikit-learn1-20-2048.jpg)
![Linear Regression Example 1
Linear Regression: Examples [linear-regression-general.ipynb]
Jayanti Prasad (IUCAA-PUNE) Machine Learning with scikit-learn June 22, 2018 21 / 41](https://image.slidesharecdn.com/scikit-learn-180622105434/75/Scikit-learn1-21-2048.jpg)

![Linear Regression Example 2
Linear Regression : Example [linear-regression-ridge.ipynb]
Jayanti Prasad (IUCAA-PUNE) Machine Learning with scikit-learn June 22, 2018 23 / 41](https://image.slidesharecdn.com/scikit-learn-180622105434/75/Scikit-learn1-23-2048.jpg)
![Linear Regression Example 2
Linear Regression [linear-regression-ridge.ipynb]
Jayanti Prasad (IUCAA-PUNE) Machine Learning with scikit-learn June 22, 2018 24 / 41](https://image.slidesharecdn.com/scikit-learn-180622105434/75/Scikit-learn1-24-2048.jpg)




![Nearest neighbors Example 5
Iris with NN: [knn-neighbours-iris.ipynb]
Jayanti Prasad (IUCAA-PUNE) Machine Learning with scikit-learn June 22, 2018 36 / 41](https://image.slidesharecdn.com/scikit-learn-180622105434/75/Scikit-learn1-36-2048.jpg)

![Nearest neighbors Example
Iris KNN : [knn-iris.ipynb]
Jayanti Prasad (IUCAA-PUNE) Machine Learning with scikit-learn June 22, 2018 38 / 41](https://image.slidesharecdn.com/scikit-learn-180622105434/75/Scikit-learn1-38-2048.jpg)
![Nearest neighbors Example
Iris KNN : [knn-iris.ipynb]
Jayanti Prasad (IUCAA-PUNE) Machine Learning with scikit-learn June 22, 2018 39 / 41](https://image.slidesharecdn.com/scikit-learn-180622105434/75/Scikit-learn1-39-2048.jpg)





















































![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dobrica Cosic - Savings by the Second: How Dynamic Pricing an...](https://cdn.slidesharecdn.com/ss_thumbnails/znp09f3smtqz3w2sq6wn-1-dobrica-cosic-savings-by-the-second-how-dynamic-pricing-and-smart-data-are-bu-251208151905-26e6f41e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Aleksandra Dragicevic - AI-Boosted Research in Healthcare: Fr...](https://cdn.slidesharecdn.com/ss_thumbnails/iqwngszurf2r7pi1lnnj-4-aleksandra-dragicevic-ad-dsc-europe-conference-20-251208151905-37c3238a-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Zdravkovic - The road less traveled in District Heating...](https://cdn.slidesharecdn.com/ss_thumbnails/nfaboniqwsz4ucyctnmy-2-milan-zdravkovic-dsc2025-the-road-less-traveled-in-district-heating-operation-251208151905-f56388a5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)